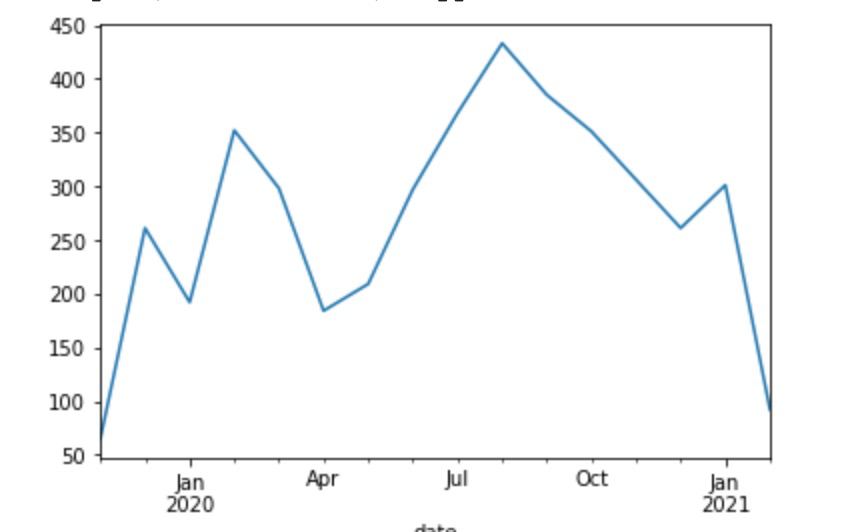
Народ, вот есть такой объём ежемесячных продаж по товару.
Я уже писал здесь, но вопрос другой чем был. Повторю условия, чтоб напомнить. Бизнес хочет спрогнозировать ежедневные продажи с минимальной ошибкой.
Сейчас они используют что-то типа скользящего среднего. И ошибка около 15%. Они написали нейронку. Там например погода забита и тд, она показала себя не очень.
Я нейронки вообще в глаза не видел, с классическим немного имел дело. У меня два варианта, либо отказаться совсем, либо попробовать XGBoost или что-то типа.
Внимание вопрос, правда ли что нейронка имеет лучшее применение на больших выборках, или это бред? И вообще насколько такая задача эффективно может решиться XGBoost или он вообще не конкурент DL
почему именно XGBoost ? Я бы посмотрел в сторону какого-нибудь fbprophet