OpenAI Codex: Evaluating Large Language Models Trained on Code
Chen et al.
arxiv.org/abs/2107.03374С одной стороны хайп по GitHub Copilot начал спадать, но с другой я не видел ни одного ревью статьи, которая описывает нейросетку под капотом.
Основная идея: зафайтнюнить GPT-3 генерировать код программы по её докстрингу. Первый вопрос: как эвалюировать? Считать перплексию как-то бессмысленно, поэтому авторы сделали тестовый сет из 164 задачек с юниттестами и смотрели может ли модель сгенерировать код, который их проходит. Также пробовали использовать BLEU и показали, что он бесполезен.
Тк сгенеренный моделью код должен где-то выполняться, чтобы злобный AI не захватил мир, авторы озаботились созданием сендбокса с помощью gVisor и eBPF-правил для файервола (на самом деле на случай, воспроизведения кода malware, которого на гитхабе хватает).
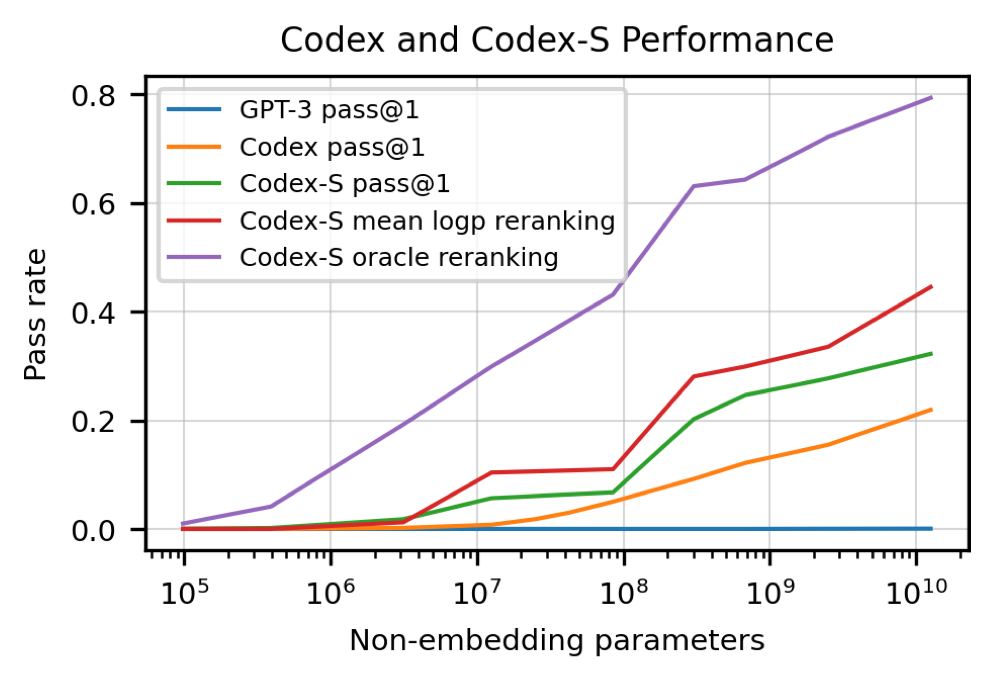
Кроме этого создали "чистый" датасет функций, который намайнили с сайтов типа leetcode, а также из репозиториев с CI, откуда забрали только те функции, которые проходят юниттесты из этих репозиториев. На нём зафайтнютились ещё раз, что сильно улучшило модель. Финальный результат: модель решает 28% задач, если генерируем только одну функцию и 70%, если генерируем 100 функций и ищем хотя бы одну, которая проходит юниттесты.
Интересные детали: GPT-3 в качестве инициализации не улучшает финальное качество по сравнению с обучением с нуля, но сходится быстрее. Также добавили в словарь токенов отвечающих за несколько пробелов подряд, это уменьшило длину на 30%.
Кажется, что мы про Copilot ещё услышим. Мне эта штука не нравится, тк сложность программирования не в том, чтобы код писать, а в том, чтобы его читать, и Copilot с этим не помогает и даже делает хуже.