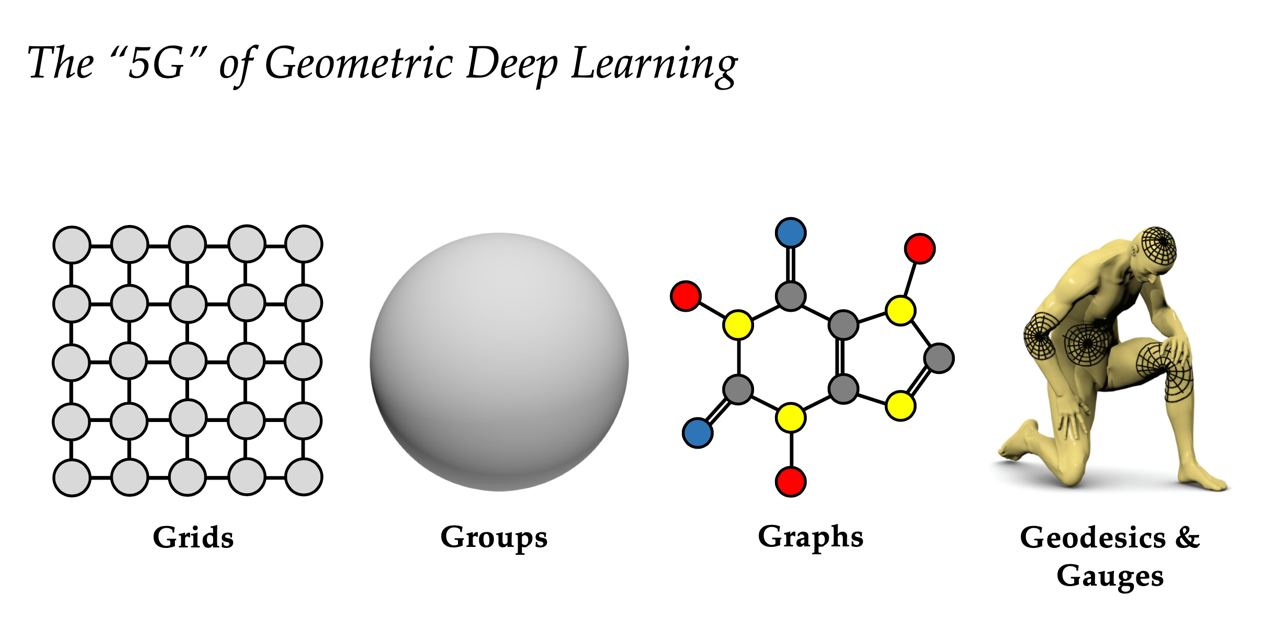
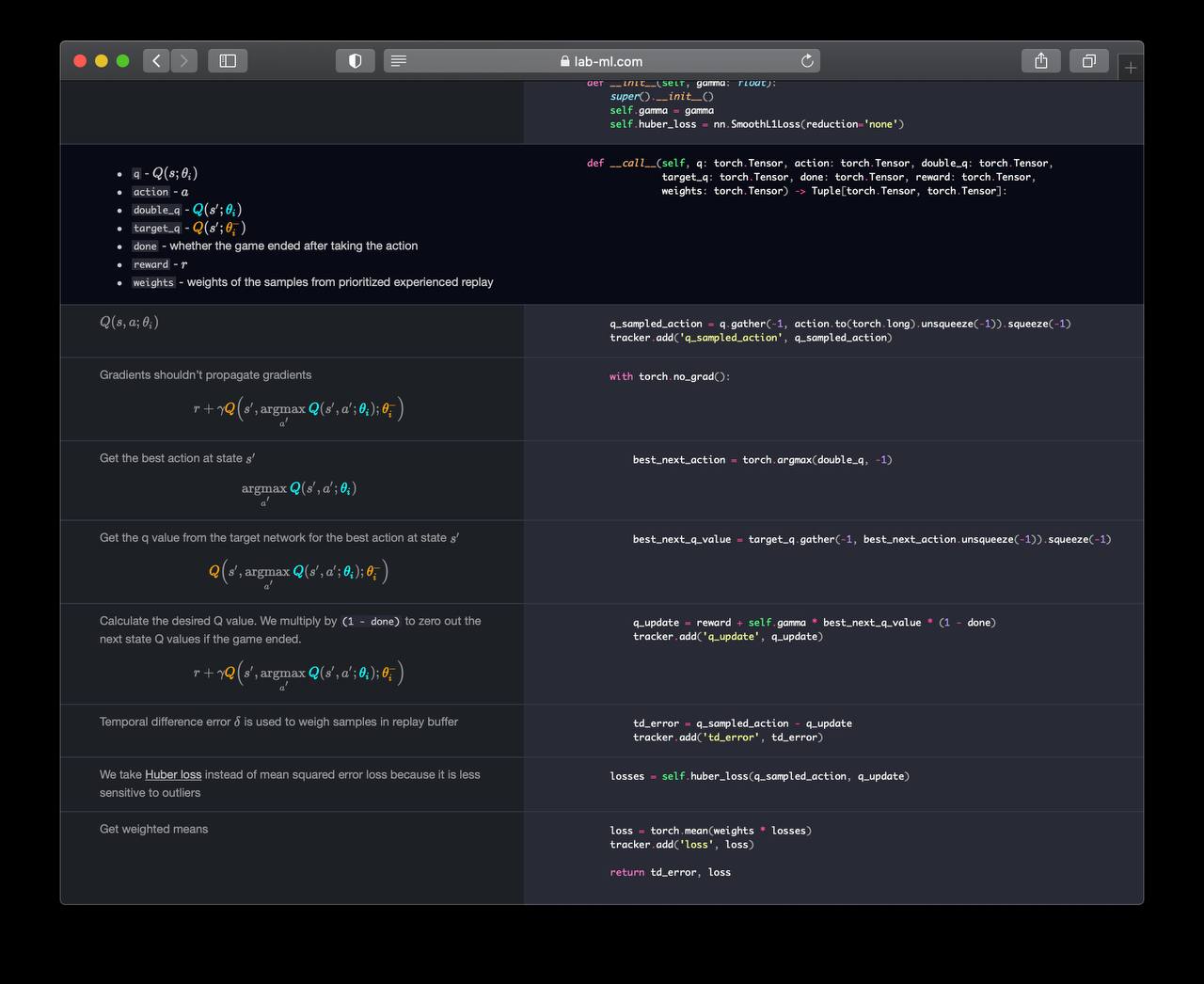
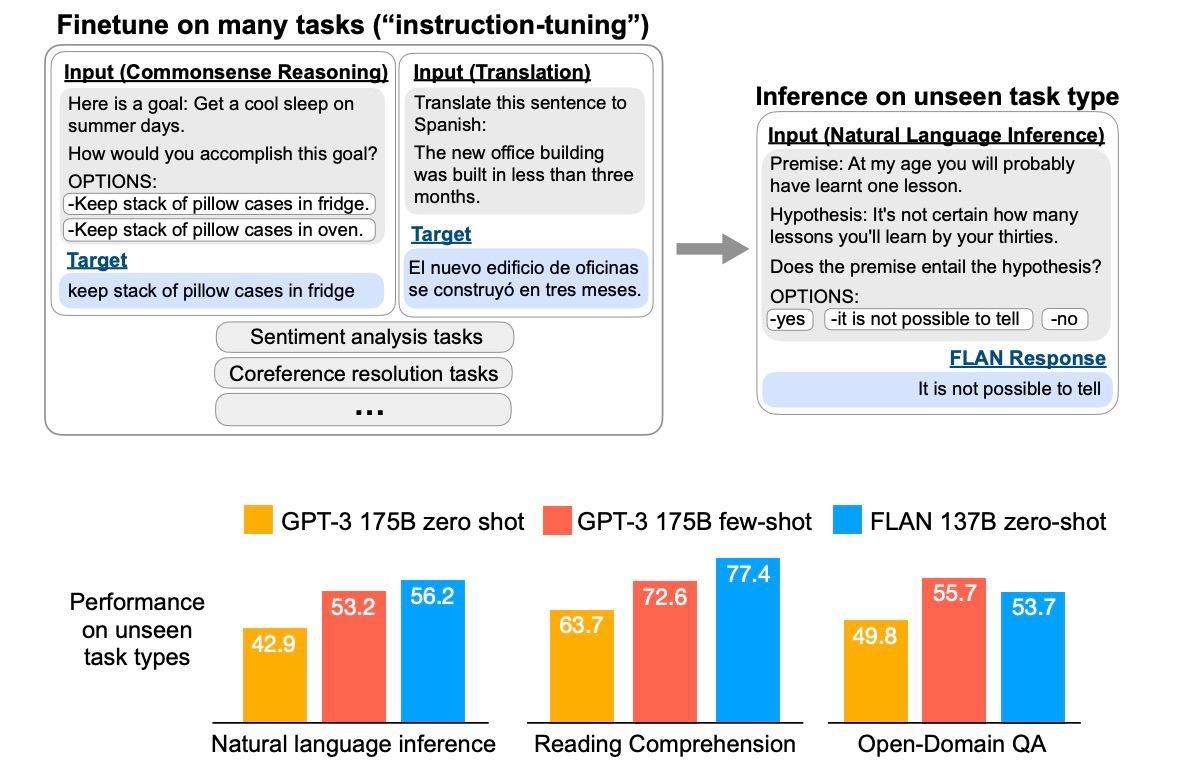
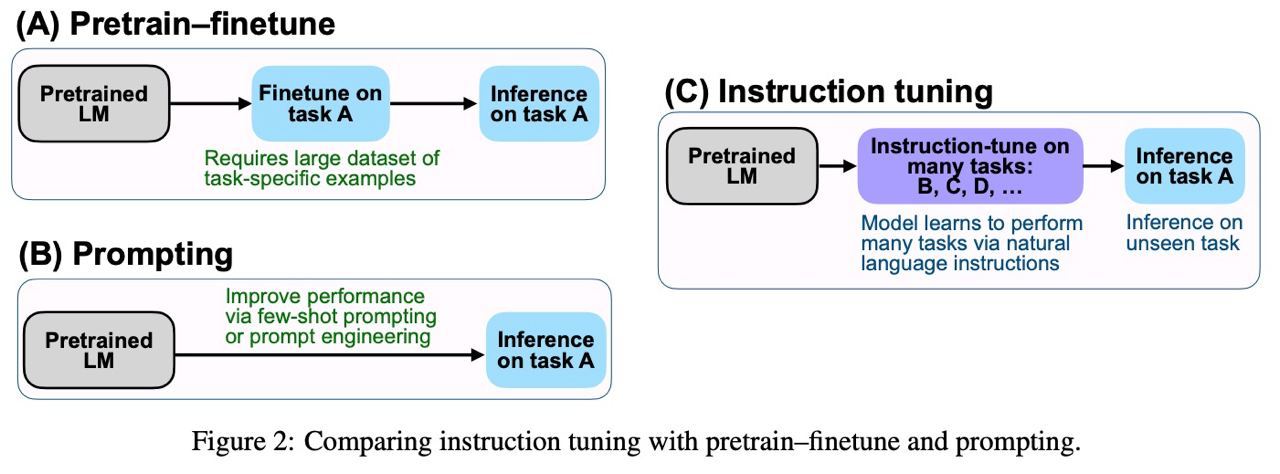
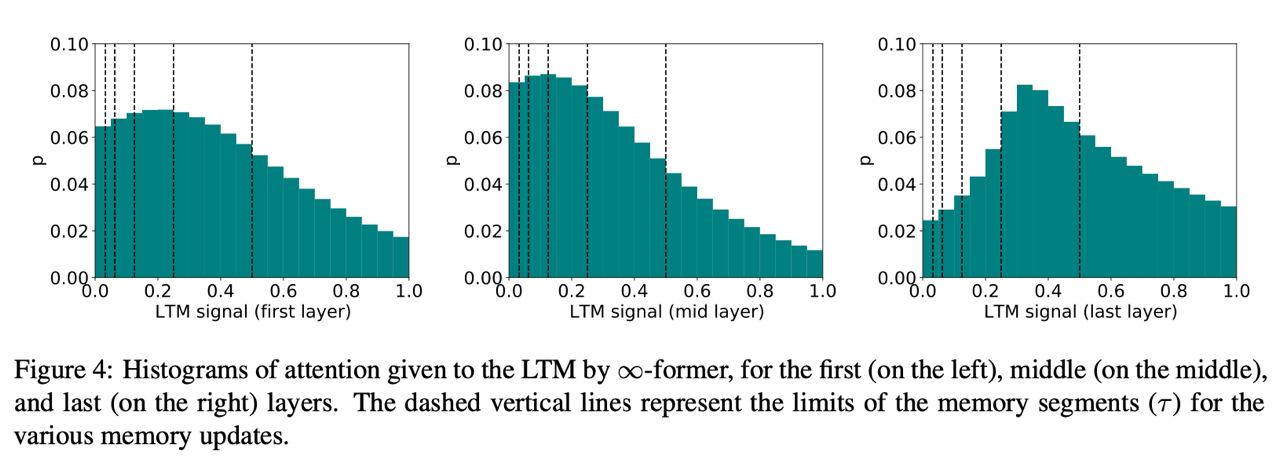
∞
-former: Infinite Memory TransformerMartins et al.
arxiv.org/abs/2109.00301Просто бомбическая статья о том, как сделать attention сколько угодно длинным. Для этого attention вычисляется не для N токенов, а как некоторая непрерывная функция. Дальше только веселее — последовательность токенов тоже представляют как непрерывную функцию. Конкретно, как линейную комбинацию из K радиально-базисных функций. При этом число базисных функций K может быть меньше числа токенов N.
Пайплайн выглядит вот так:
1. берём токены, эмбеддим, а дальше аппроксимируем получившуюся матрицу с помощью K базисных функций, точнее как X = B @ F, где B - матрица размера N на K, а F - это K базисных функций
2. берём матрицу B и считаем keys и values для attention с помощью линейных проекций
3. далее мы хотим получить непрерывный attention, который мы моделируем с помощью гауссианы N(mu, sigma). Для этого считаем mu и sigma как attention между keys и queries плюс ещё одно линейное преобразование плюс sigmoid (для mu) или softplus (для sigma^2)
4. теперь делаем взвешенное усреднение values с весами полученными от гаусианы, то есть условное матожидание. Авторы мало про это пишут, скорее всего есть какие-то аналитические решения для матожидания радиальных функций, которые тут использутся.
5. последний шаг — сделать всё это n_heads раз и потом смешать все головы с помощью линейного слоя. Это помогает избавиться от того, что у гаусиана унимодальна (у неё только один пик) и после смешивания нескольких разных гаусиан наш attention может смотреть на несколько разных кусков текста.
Результаты: на wikitext-103 превосходит TransformerXL и Compressive Transformer. Также придумали процедуру "обесконечивания" обычных трансформеров, где обычный attention дополняется бесконечным attention и файнтюнится.