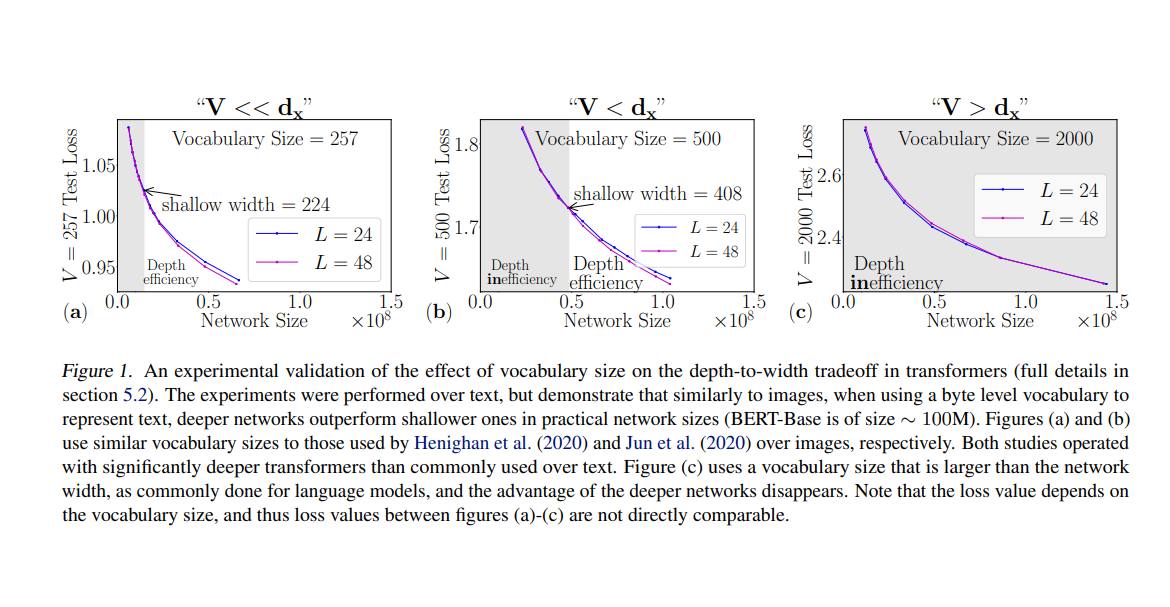
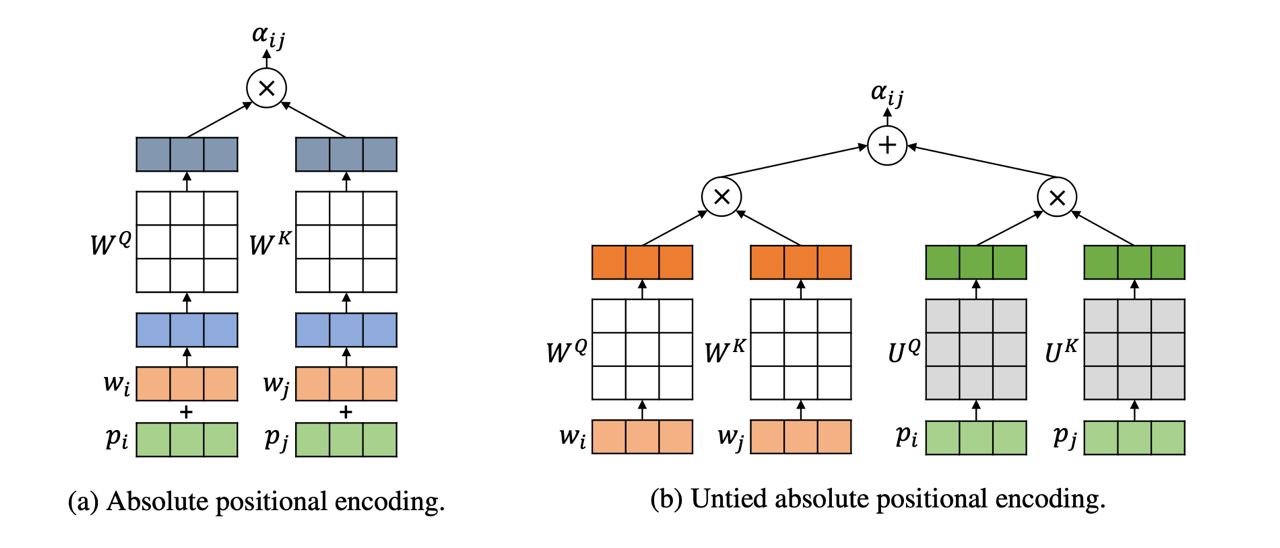
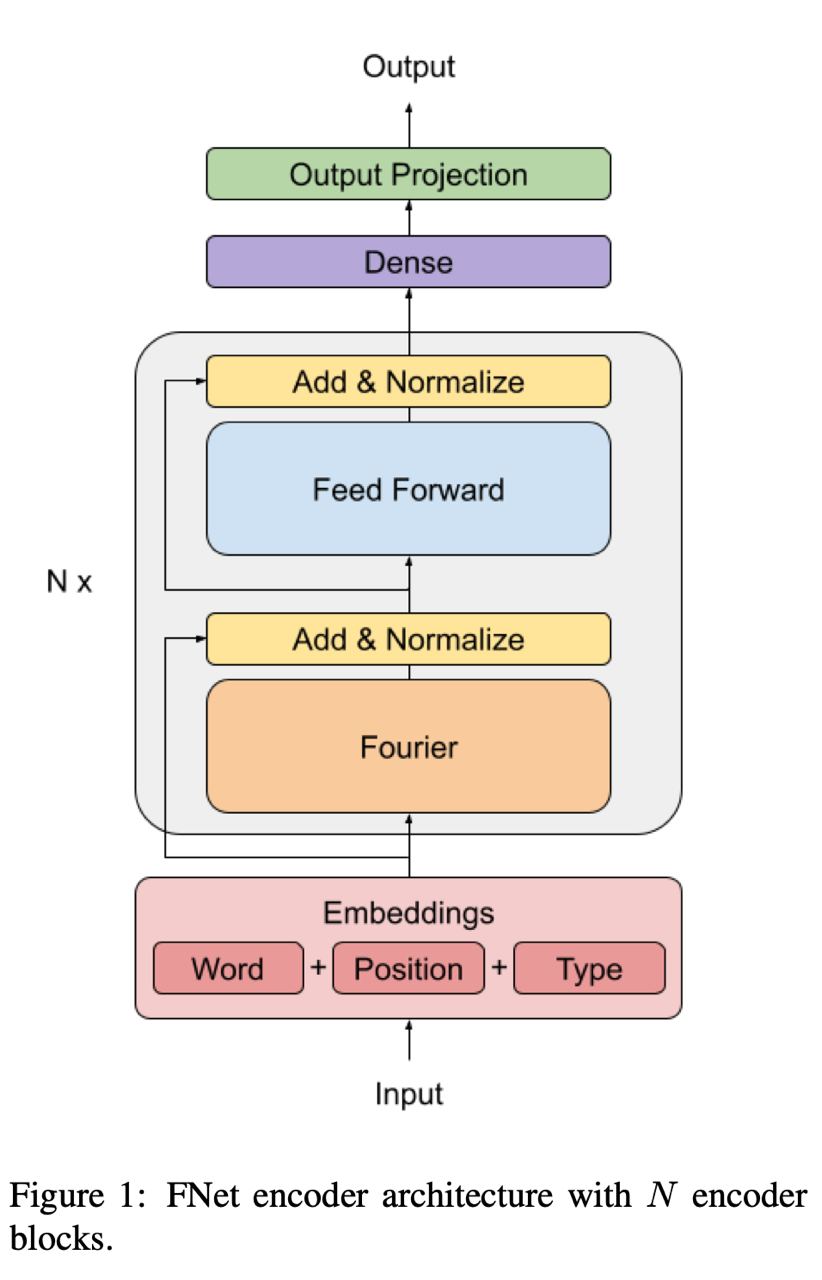
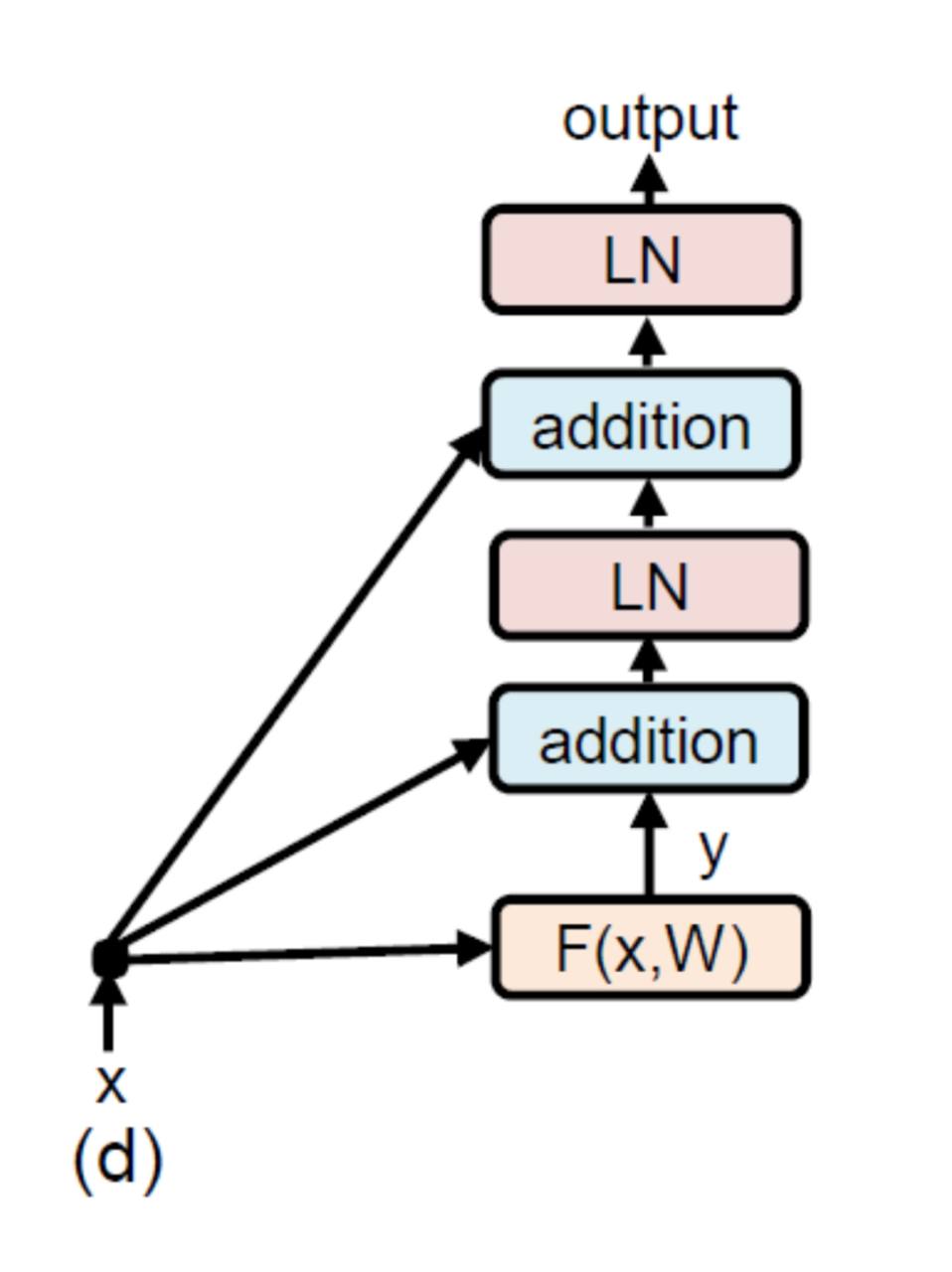
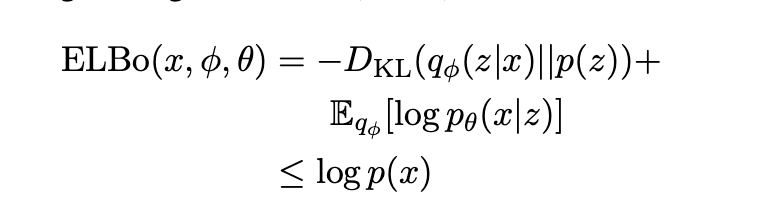Do sequence-to-sequence VAEs learn global features of sentences?
Bosc and Vincent, [MILA]
arxiv.org/abs/2004.07683
Короткий ответ на вопрос из заголовка: нет.
А теперь подбробнее. В NLP принятно считать, что если вы делаете автокодировщик, сжимающий ваше предложение в один вектор, а потом разжимающий его обратно, но лучше использовать VAE. Интуитивно это выходит из того, что дополнительная регуляризация в ELBo и семплирование из пространства латентных переменных позволят сделать вектора, лучше описывающие глобальные фичи предложения.
Авторы этой статьи показывают противоречащие этой интуиции результаты. Они показывают, что VAE склонны запоминать только первые несколько слов, а дальше пологаться на то, что декодер сможет правильно угадать остальные. Возможно, это в том числе следует из хака под названием free bits, который борется с локальным минимумом VAE, когда KL-tem равен нулю и модель просто производит шум и ничего не учит.
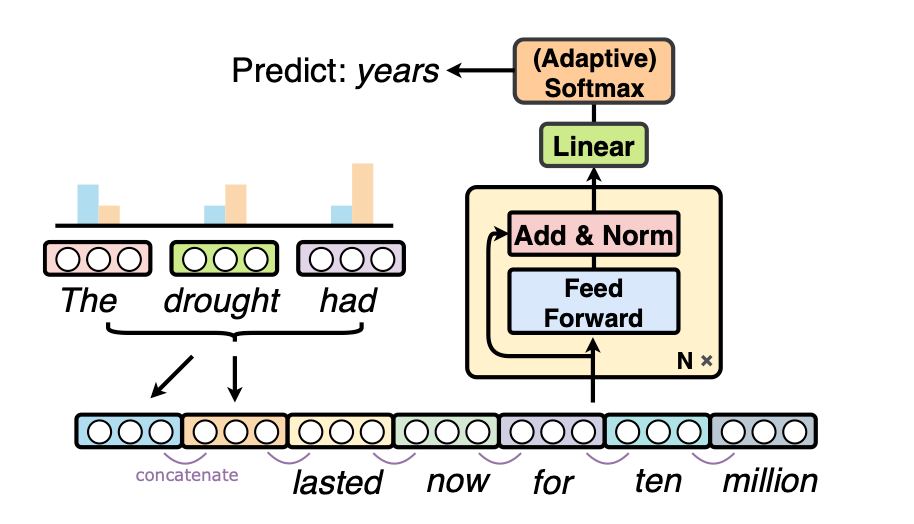
В конце статьи они предлагают исспользовать альтернативные энкодеры (Bag of Words (BoW) или предобученную LM с фиксированными весами) и альтарнативный декодер, который довольно хитрый и если я правильно понял, предсказывает BoW-вероятности слов предложения. На некоторых датасетах по классификации эти варианты улучшают F меру вплоть до 5 пунктов по сравнению с обычным VAE, это намекает на то, что BoW заметно улучшает представления VAE, а ещё точнее показывает, что VAE настолько плохо учит фичи, что даже BoW может быть лучше.
Bosc and Vincent, [MILA]
arxiv.org/abs/2004.07683
Короткий ответ на вопрос из заголовка: нет.
А теперь подбробнее. В NLP принятно считать, что если вы делаете автокодировщик, сжимающий ваше предложение в один вектор, а потом разжимающий его обратно, но лучше использовать VAE. Интуитивно это выходит из того, что дополнительная регуляризация в ELBo и семплирование из пространства латентных переменных позволят сделать вектора, лучше описывающие глобальные фичи предложения.
Авторы этой статьи показывают противоречащие этой интуиции результаты. Они показывают, что VAE склонны запоминать только первые несколько слов, а дальше пологаться на то, что декодер сможет правильно угадать остальные. Возможно, это в том числе следует из хака под названием free bits, который борется с локальным минимумом VAE, когда KL-tem равен нулю и модель просто производит шум и ничего не учит.
В конце статьи они предлагают исспользовать альтернативные энкодеры (Bag of Words (BoW) или предобученную LM с фиксированными весами) и альтарнативный декодер, который довольно хитрый и если я правильно понял, предсказывает BoW-вероятности слов предложения. На некоторых датасетах по классификации эти варианты улучшают F меру вплоть до 5 пунктов по сравнению с обычным VAE, это намекает на то, что BoW заметно улучшает представления VAE, а ещё точнее показывает, что VAE настолько плохо учит фичи, что даже BoW может быть лучше.