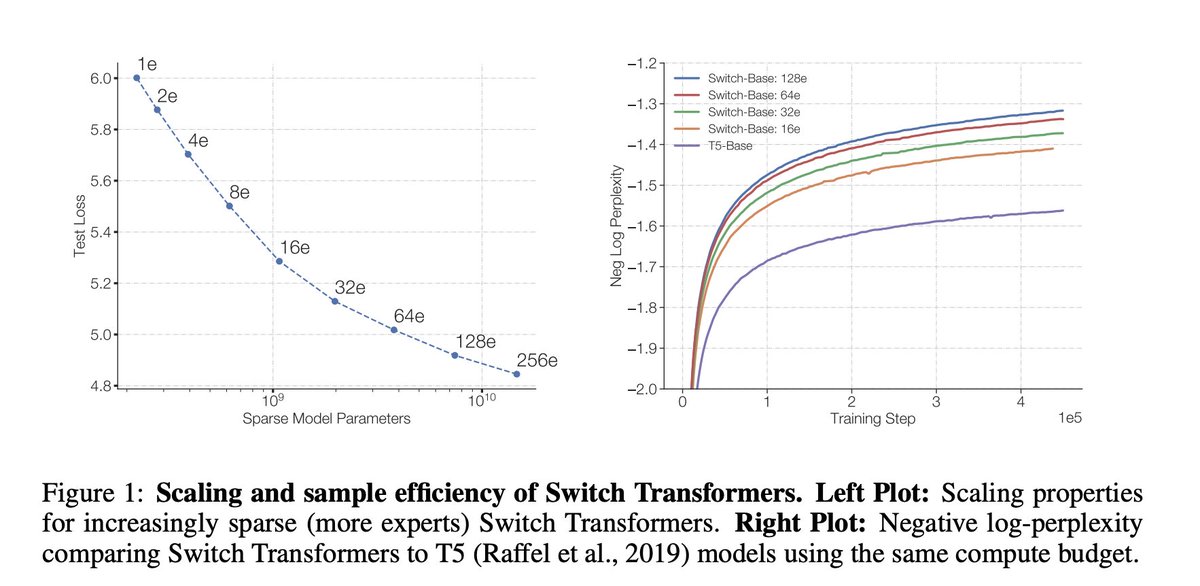
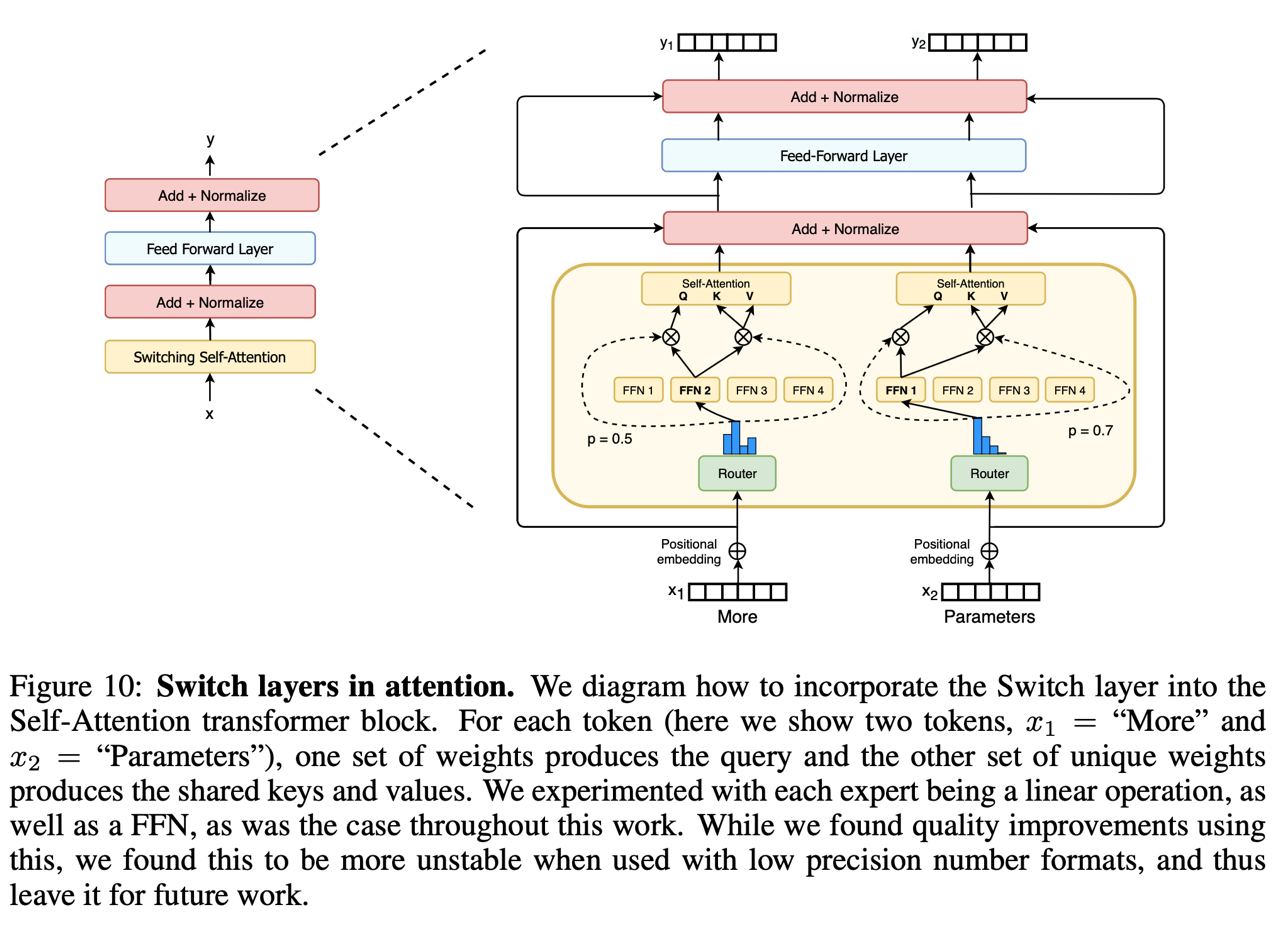
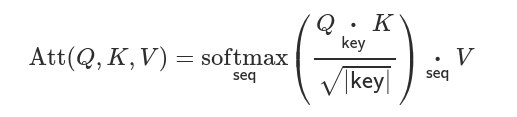Очень много шума наделала модель DALL·E от OpenAI, которая умеет генерировать картинки вместе с текстом.
К сожалению, OpenAI (уже традиционно) опубликовали блогпост без статьи 😕, поэтому придётся угадывать что же они там делали. Ещё один момент - зачастую блогпост OpenAI и статья OpenAI очень разные. Поэтому подробный обзор DALL·E будет позже.
Сейчас попытаюсь саммаризировать то, что я понял и мои предположения,
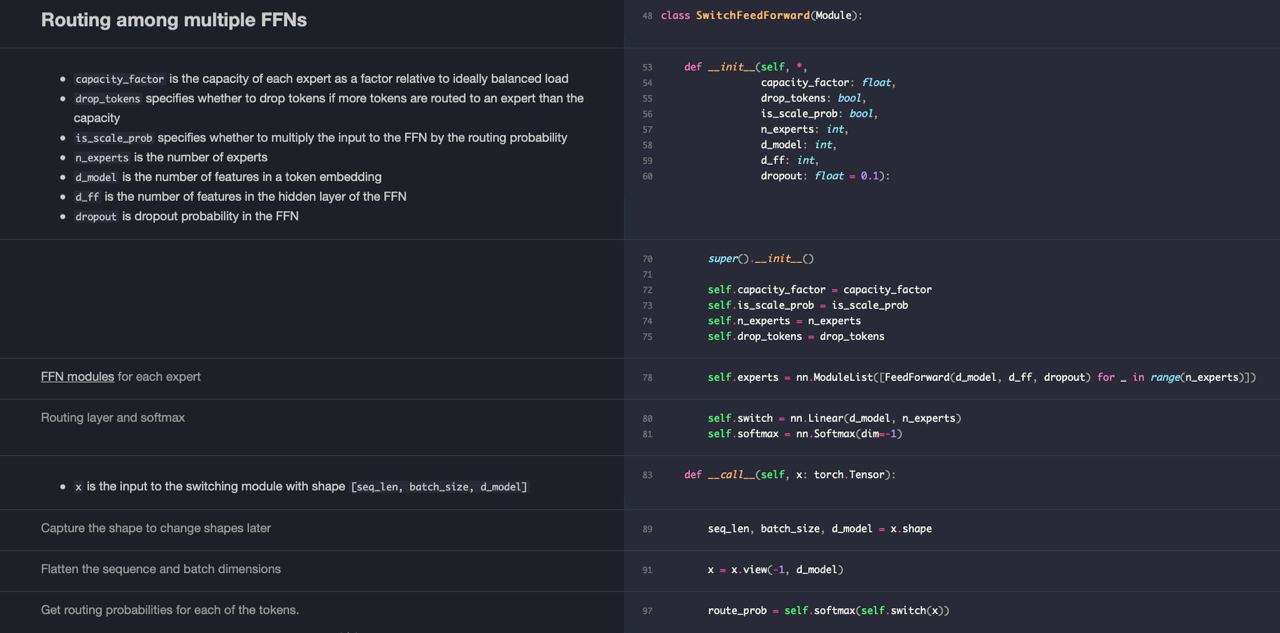
DALL·E - это просто языковая модель-трансформер. Но она обучена на последовательностях вида “текст связанный с картинкой <значения пикселей картинки>”. О том, как OpenAI применяет языковое моделирование для изображений можно почтитать тут.
Моделируется последовательность состоящая и из текста и из картинки просто одним большим трансформером. То есть модель предсказывает следующий токен, который может быть как словом, так и пикселем. При этом картинка и текст связанны друг с другом и помогают друг друга предсказать.
Теперь мои догадки о том, как майнили пары текст-изображение. Скорее всего просто делали поиск в интернете и майнили соответствующие картинки, соответствующие коротким фразам из датасета на котором тренировали GPT-3. Что ещё можно было сделать: как-то отсеивать тексты, которые не похожи на описания картинок или делать поиск наоборот - текста по намайненым картинкам. В конце-концов третья вещь - использовать предтренированные модели object detection или metric learning чтобы проверять, что картинки и правда похожи на текст. В качестве такой модели можно использовать DALL·E, который натренирован на предыдущей итерации датасета (оценивая моделью вероятность текста при условии картинки или наоборот).
Результаты:
Можно генерировать изображения обусловливаясь на тексте или даже не тексте и начале изображения. При этом качество картинок и уровень понимания текста зачастую очень удивляют. Например вы можете написать “вот такой же чайник, но со словом GPT на нём <картинка чайника>” и получить вот такие картинки.
openai.com/blog/dall-e
Неофициальная имплементация: github.com/lucidrains/DALLE-pytorch
Спасибо за ссылку @Archelunch
К сожалению, OpenAI (уже традиционно) опубликовали блогпост без статьи 😕, поэтому придётся угадывать что же они там делали. Ещё один момент - зачастую блогпост OpenAI и статья OpenAI очень разные. Поэтому подробный обзор DALL·E будет позже.
Сейчас попытаюсь саммаризировать то, что я понял и мои предположения,
DALL·E - это просто языковая модель-трансформер. Но она обучена на последовательностях вида “текст связанный с картинкой <значения пикселей картинки>”. О том, как OpenAI применяет языковое моделирование для изображений можно почтитать тут.
Моделируется последовательность состоящая и из текста и из картинки просто одним большим трансформером. То есть модель предсказывает следующий токен, который может быть как словом, так и пикселем. При этом картинка и текст связанны друг с другом и помогают друг друга предсказать.
Теперь мои догадки о том, как майнили пары текст-изображение. Скорее всего просто делали поиск в интернете и майнили соответствующие картинки, соответствующие коротким фразам из датасета на котором тренировали GPT-3. Что ещё можно было сделать: как-то отсеивать тексты, которые не похожи на описания картинок или делать поиск наоборот - текста по намайненым картинкам. В конце-концов третья вещь - использовать предтренированные модели object detection или metric learning чтобы проверять, что картинки и правда похожи на текст. В качестве такой модели можно использовать DALL·E, который натренирован на предыдущей итерации датасета (оценивая моделью вероятность текста при условии картинки или наоборот).
Результаты:
Можно генерировать изображения обусловливаясь на тексте или даже не тексте и начале изображения. При этом качество картинок и уровень понимания текста зачастую очень удивляют. Например вы можете написать “вот такой же чайник, но со словом GPT на нём <картинка чайника>” и получить вот такие картинки.
openai.com/blog/dall-e
Неофициальная имплементация: github.com/lucidrains/DALLE-pytorch
Спасибо за ссылку @Archelunch