VirTex: Learning Visual Representations from Textual Annotations
Desai and Johnson [University of Michigan]
arxiv.org/abs/2006.06666v1
TL;DR предобучение для задач CV на задаче image captioning более sample-efficient, чем предобучение на ImageNet-классификации.
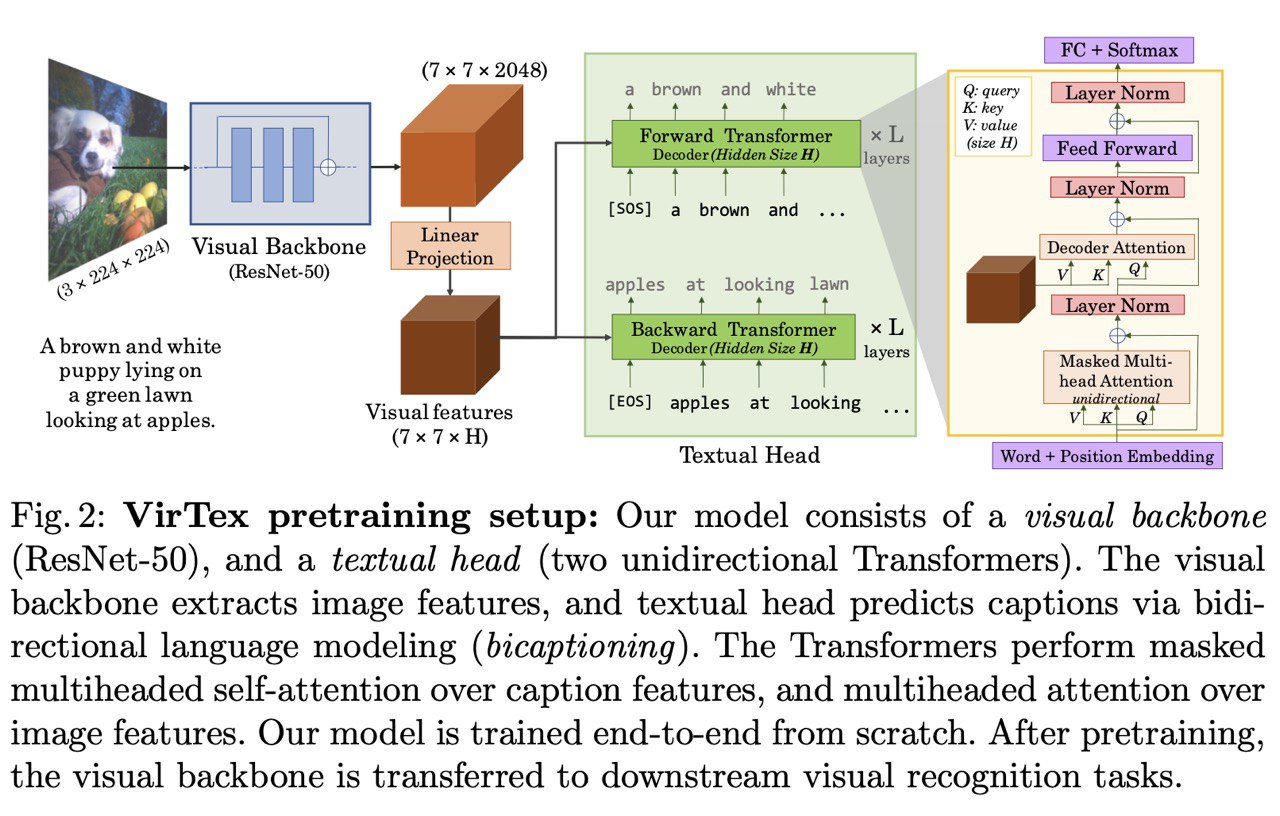
Обучали resnet+transformer lm. В качестве задачи выбрали комбинацию forward LM и backward LM, аналогично ELMo. Хотели попробовать MLM тоже, но не умеестились в compute.
Много людей считают, что связывание CV и NLP будет очень активно развиваться в ближайшие пару лет, я с ними согласен.
Desai and Johnson [University of Michigan]
arxiv.org/abs/2006.06666v1
TL;DR предобучение для задач CV на задаче image captioning более sample-efficient, чем предобучение на ImageNet-классификации.
Обучали resnet+transformer lm. В качестве задачи выбрали комбинацию forward LM и backward LM, аналогично ELMo. Хотели попробовать MLM тоже, но не умеестились в compute.
Много людей считают, что связывание CV и NLP будет очень активно развиваться в ближайшие пару лет, я с ними согласен.