On Identifiability in Transformers
Brunner et al. [ETH Zurich]
arxiv.org/abs/1908.04211Вторая волна анализа attentiion пошла! :parrot:
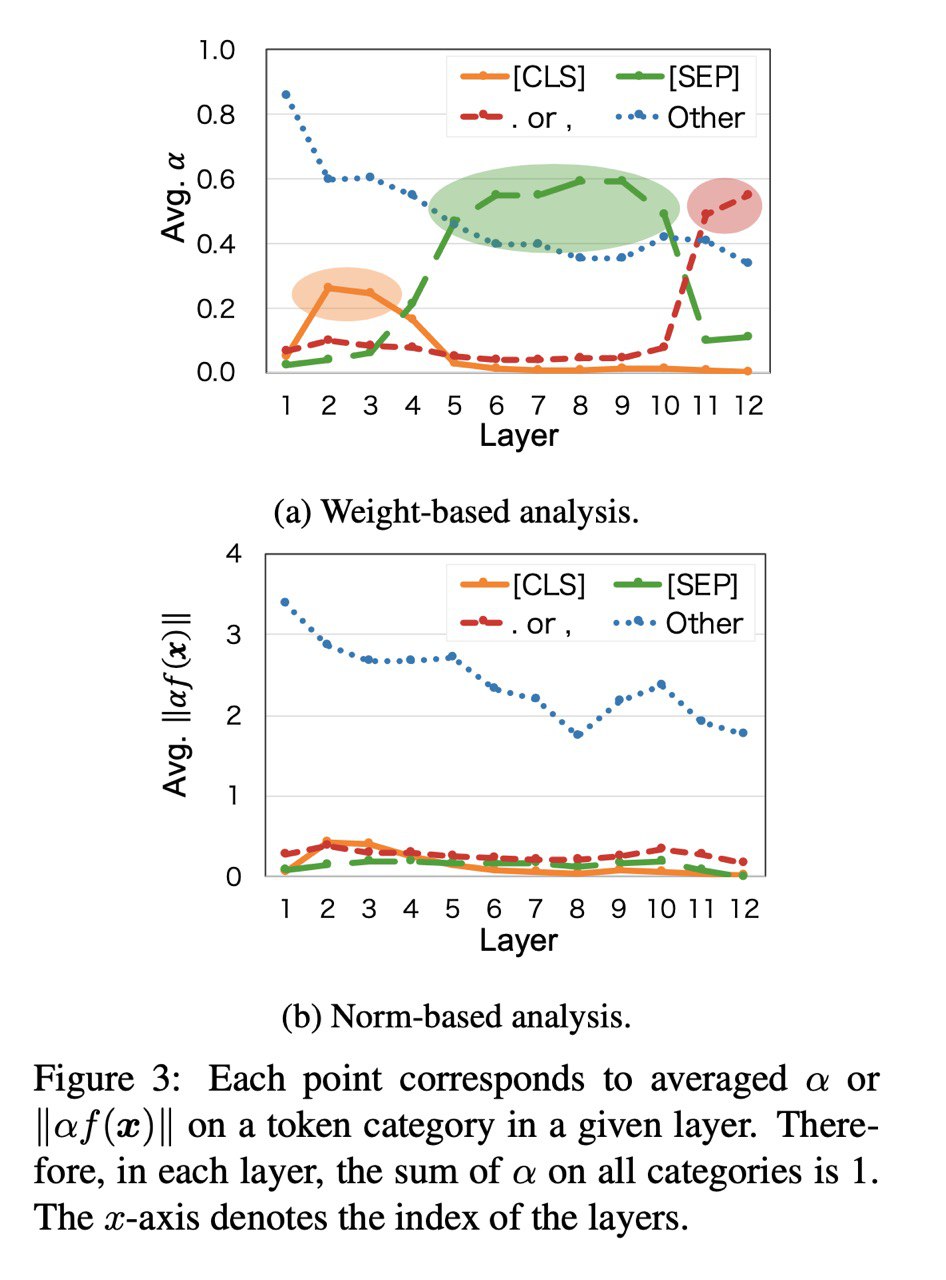
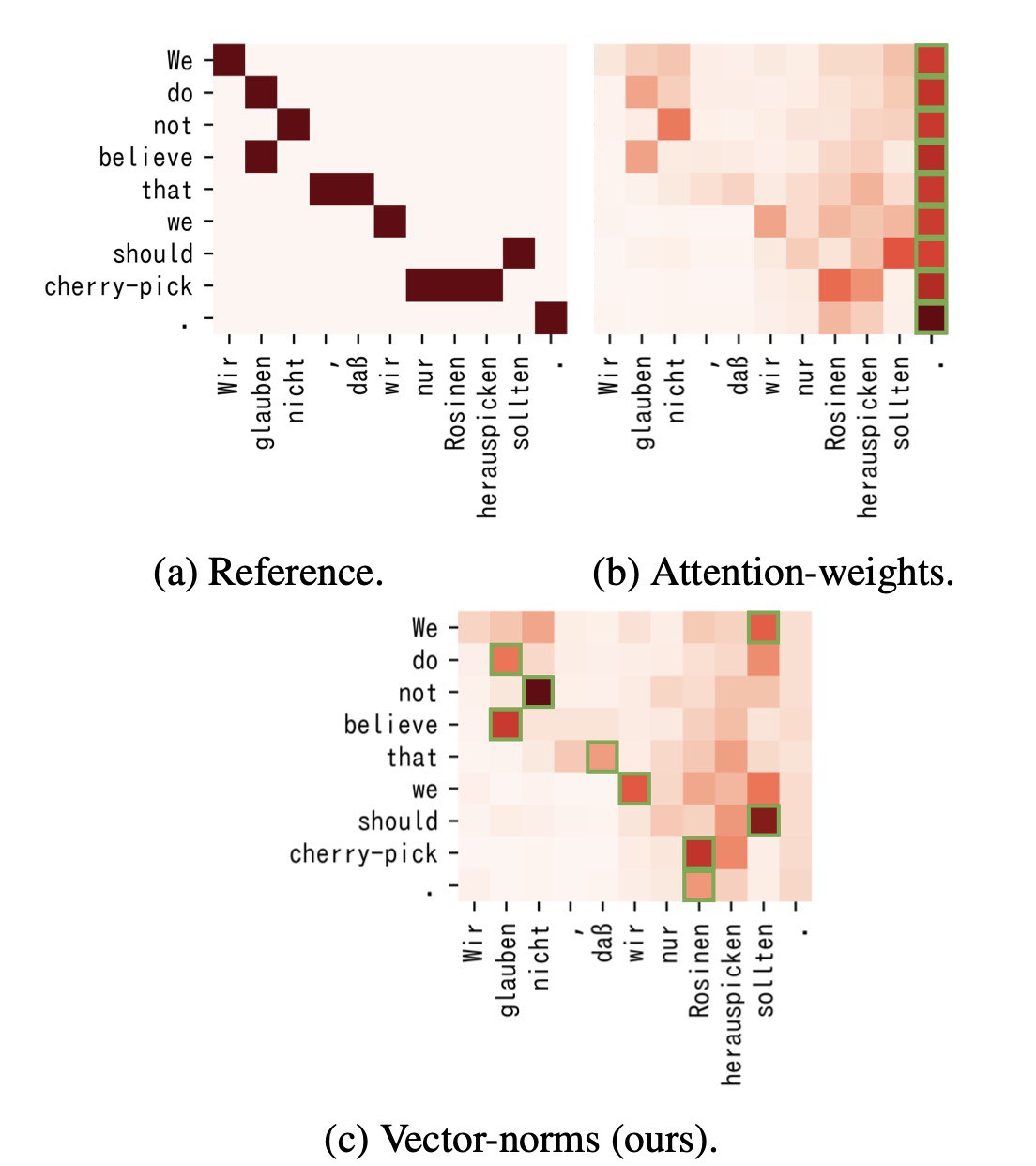
В этой статье авторы тоже говорят, что использовать attention weights для интерпретации - это плохая идея и даже дают формальное описание почему (но как по мне их определениие "идентифицируемости" слишком строгое и поэтому далеко от реальности). Из интересного тут то, что они предлагают ещё один метод анализа attention, который, аналогично Attention Module is Not Only a Weight показывает, что CLS и SEP токены не так важны.
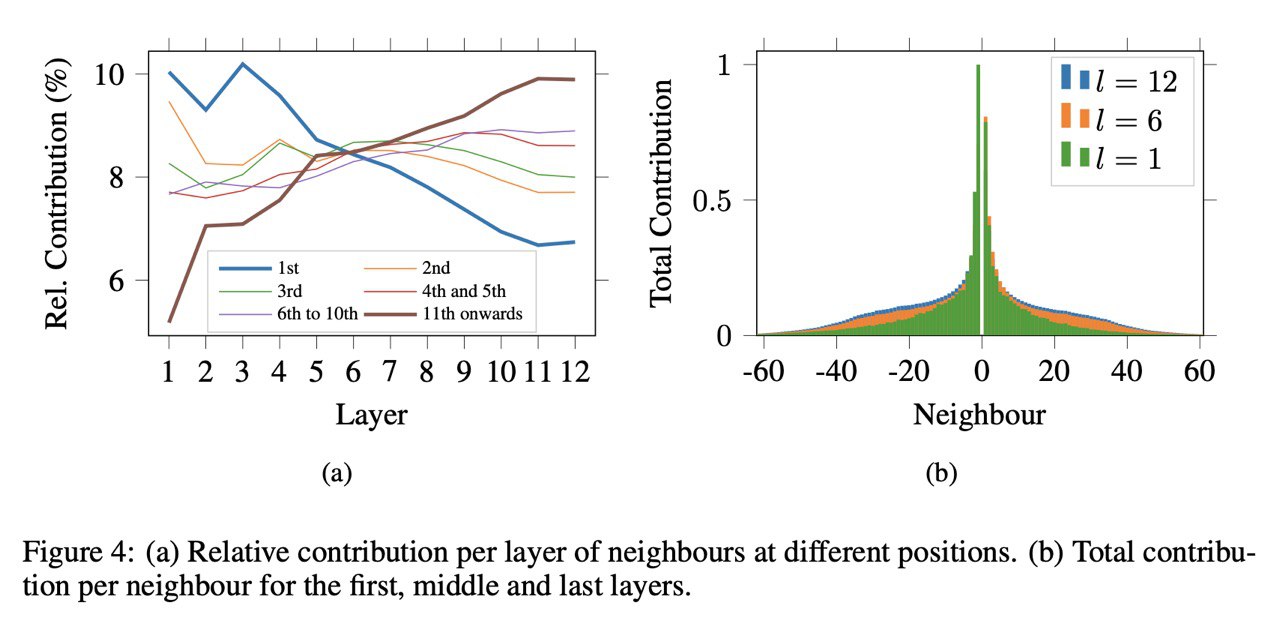
Дальше интереснее: их эксперименты показывают две на первый взгляд противоречащих штуки.
1. Токен достаточно хорошо сопоставляется его эмбеддингу в том числе в последних слоях трансформера
2. Эмбеддинги различных слов
сильно смешиваются внутри трансформера
То есть с одной стороны мы можем сказать, что 4 токен действительно соответствует 4 слову, но с другой - в нём очень много информации про другие слова. В принципе это ровно то, что мы имеем в виду под контекстуализированными эмбеддингами, но зато теперь мы имеем экспериментальное подтверждение этого.