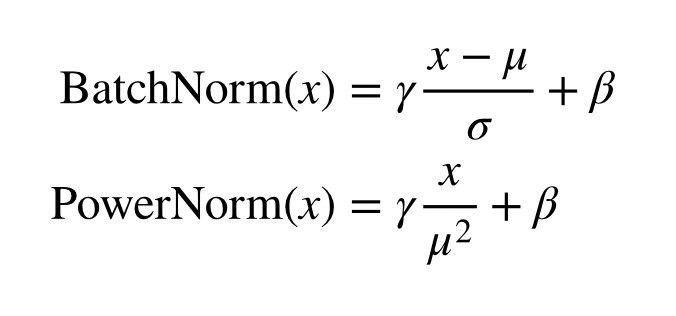Emerging Cross-lingual Structure in Pretrained Language Models
Wu, Conneau, et al. [FAIR]
arxiv.org/abs/1911.01464Статья для тех, кто не любит SOTA-driven approach. Авторы задают конкретные вопросы про мультиязычные модели и пытаются на них ответить:
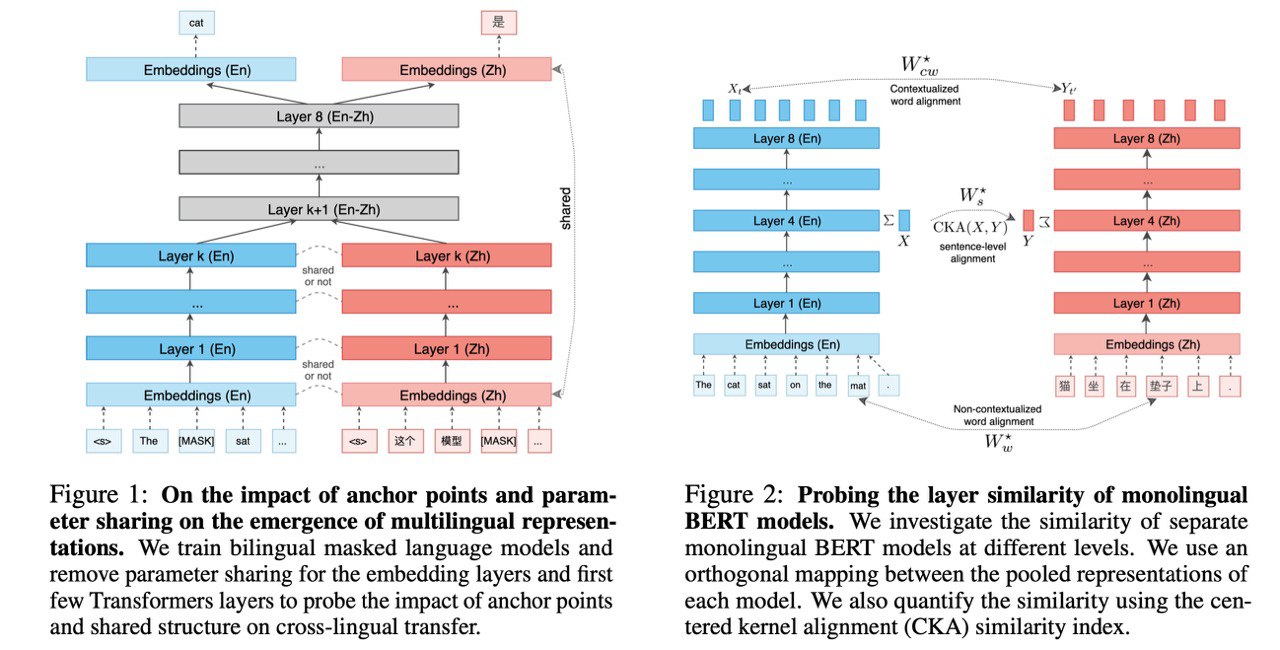
Q: Важны ли anchor points (одинаковые по написанию и смыслу токены, которые автоматически мапятся в один эмбеддинг ещё на стадии предобработки) для предтренировки mBERT?
A: Слабо важны, дают 1-2 пункта на downstream-задачах
Q: Насколько важен model parameter sharing между языками?
A: Критически важен, для далёких языков (En-Ru, En-Zh) качество downstream задач падает почти до уровня случайного выбора, если шарить только
половину параметров
Q: Хорошо ли мапятся векторные представления слова и его перевода (контекстуальные и неконтекстуальные) если использовать представления mBERT?
A: Примерно на уровне fastText
Q: Насколько похожи обученные нейросети? Похож ли одноязычный английский BERT на одноязычный русский BERT? А на мультиязычный En-Ru BERT?
A: Похожи, для близких языков схожесть больше, чем для далёких