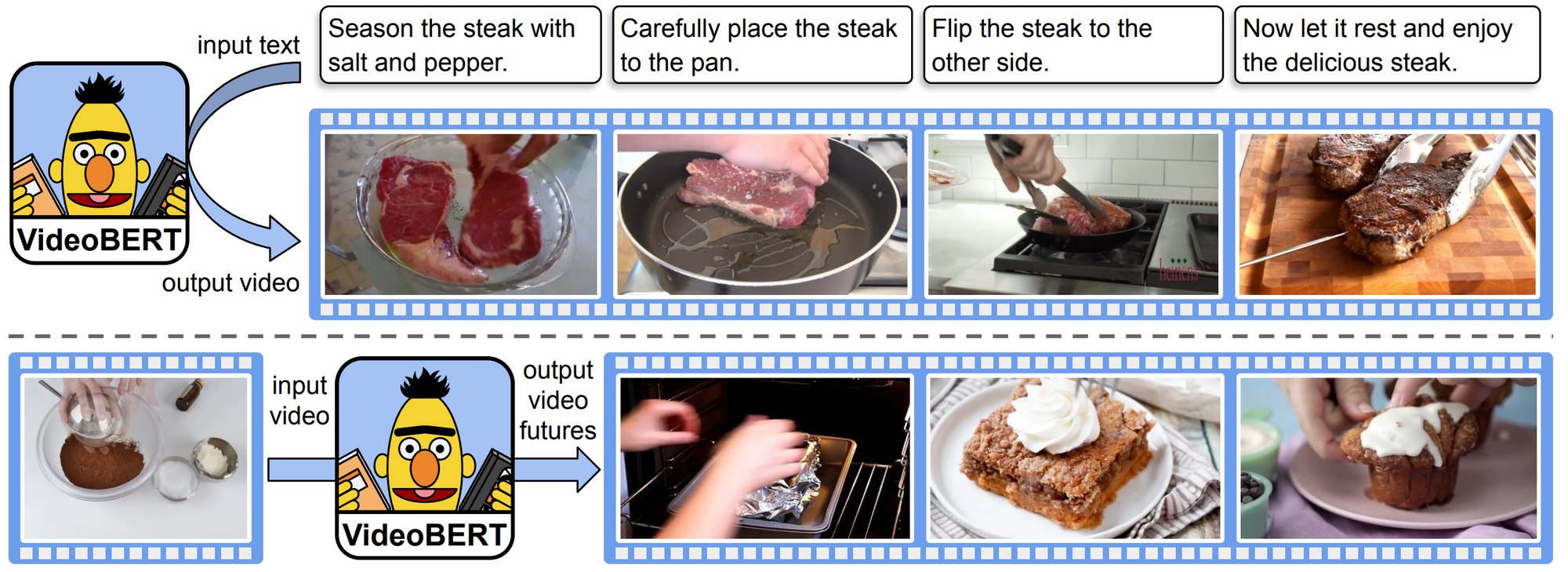
Трэд Thomas Wolf о том, как надо релизить ваш исследовательскиий код и зачем это вообще нужно делать.
Мега важная тема, потому что всем, кто программирует, нужно осознавать, что код, который невозможно прочитать и модифицировать хуже кода, который не работает.
Если коротко:
Ваш код - это не просто доказательство того, что вы не придумали цифры в статье. Это возможность позволить другим переиспользовать ваши идеи. Дайте другим понятные инструкции как запускать ваш код и релизьте веса обученных моделей. Предоставьте возможность быстро тестировать/дебажить. Используйте
меньше абстракций наболело. Потратьте ~4 дня на доработку кода после сабмита статьи.
От себя хочу добавить, что если ваш код удобен для модификации другими людьми, то это позволит вашим сследованиям сделать больший impact (а мы впедь ради этого ими и занимаемся, верно?). В конце-концов это позволит вам получить больше цитирований, а другим - меньше страдать. Win-win situation.