



Size: a a a
2019 December 15


Советы из Programatic Programmer, которые релевантны и для девелоперов и исследователей
60 страниц заметок по последнему NeurIPS (RL, Meta-Learning и теория DL), если у вас есть час-два времени.
https://twitter.com/dabelcs/status/1206237428626923520
https://twitter.com/dabelcs/status/1206237428626923520

2019 December 16
Переслано от Irina
Минутка рекламы:
Dialogue Evaluation 2020: Дорожка по построению таксономии на русском языке
Мы рады сообщить Вам, что в 2019-2020 году впервые будет проходить соревнование по автоматическому предсказанию гиперонимов для русского языка в рамках 26-й Международной конференции DIALOGUE 2020: https://competitions.codalab.org/competitions/22168.
Предсказание отношений типа "являться" (банан — фрукт, кошка — животное), т.е. отношений гиперонимии, является одним из необходимых этапов семантического анализа для решения многих задач обработки естественного языка. Цель данного соревнования — автоматически обогатить существующую таксономию (ruWordNet) новыми словами, связав их отношениями гиперонимии с существующими.
Для английского языка задача поиска гиперонимов и автоматическому расширению тезаурусов уже не раз рассматривалась в рамках соревнований SemEval (SemEval-2018 task 9: Hypernym discovery, Semeval-2016 task 13: Taxonomy extraction evaluation, SemEval 2015 task 17), для русского языка данная задача ставится впервые.
Более того, условия данного соревнования более приближены к реальности, так как участникам на входе даны только сами слова без определений, а также контексты, в которых они встречаются.
Данную задачу можно сформулировать следующим образом: для слова, не включенного в тезаурус, необходимо предсказать ранжированный список из 10 синсетов, которые с наибольшей вероятностью могли бы быть гиперонимами для данного слова (гиперонимов может быть больше, чем 1).
Мы полагаем, что современные контекстуальные векторные представления слов, такие как ELMo и BERT, будут особенно эффективны в при поиске гиперонимов, и будем рады увидеть решения, использующие данные подходы (или любые другие) в нашем соревновании. В качестве базовых решений мы предоставим реализации, основанные на дистрибутивной семантике и нейросетевых языковых моделях.
Важные даты:
Начало соревнования: 15 декабря 2019.
Публикация тренировочных данных: 15 декабря 2019.
Публикация тестовых данных: 31 января 2020.
Последний день для отправки решений: 14 февраля 2020.
Результаты дорожки: 28 февраля 2020.
Если вы знаете кого-то, кому могло бы быть интересно данное соревнование — обязательно поделитесь этой новостью!
Контакты для связи с организаторами:
Irina.Nikishina@skoltech.ru
v.logacheva@skoltech.ru
Dialogue Evaluation 2020: Дорожка по построению таксономии на русском языке
Мы рады сообщить Вам, что в 2019-2020 году впервые будет проходить соревнование по автоматическому предсказанию гиперонимов для русского языка в рамках 26-й Международной конференции DIALOGUE 2020: https://competitions.codalab.org/competitions/22168.
Предсказание отношений типа "являться" (банан — фрукт, кошка — животное), т.е. отношений гиперонимии, является одним из необходимых этапов семантического анализа для решения многих задач обработки естественного языка. Цель данного соревнования — автоматически обогатить существующую таксономию (ruWordNet) новыми словами, связав их отношениями гиперонимии с существующими.
Для английского языка задача поиска гиперонимов и автоматическому расширению тезаурусов уже не раз рассматривалась в рамках соревнований SemEval (SemEval-2018 task 9: Hypernym discovery, Semeval-2016 task 13: Taxonomy extraction evaluation, SemEval 2015 task 17), для русского языка данная задача ставится впервые.
Более того, условия данного соревнования более приближены к реальности, так как участникам на входе даны только сами слова без определений, а также контексты, в которых они встречаются.
Данную задачу можно сформулировать следующим образом: для слова, не включенного в тезаурус, необходимо предсказать ранжированный список из 10 синсетов, которые с наибольшей вероятностью могли бы быть гиперонимами для данного слова (гиперонимов может быть больше, чем 1).
Мы полагаем, что современные контекстуальные векторные представления слов, такие как ELMo и BERT, будут особенно эффективны в при поиске гиперонимов, и будем рады увидеть решения, использующие данные подходы (или любые другие) в нашем соревновании. В качестве базовых решений мы предоставим реализации, основанные на дистрибутивной семантике и нейросетевых языковых моделях.
Важные даты:
Начало соревнования: 15 декабря 2019.
Публикация тренировочных данных: 15 декабря 2019.
Публикация тестовых данных: 31 января 2020.
Последний день для отправки решений: 14 февраля 2020.
Результаты дорожки: 28 февраля 2020.
Если вы знаете кого-то, кому могло бы быть интересно данное соревнование — обязательно поделитесь этой новостью!
Контакты для связи с организаторами:
Irina.Nikishina@skoltech.ru
v.logacheva@skoltech.ru
В канале начинают просить опубликовать не только сообщения о митапах, но и о воркшопах на топовых конференциях. 💪
Семинар TextGraphs @ COLING'2020 принимает работы на темы связанные с анализом графов для NLP, векторными представлениями графов и другими темами, которые имеют отношение к теории графов: https://sites.google.com/view/textgraphs2020
Вопросы по семинару можно направлять @apanc.
Семинар TextGraphs @ COLING'2020 принимает работы на темы связанные с анализом графов для NLP, векторными представлениями графов и другими темами, которые имеют отношение к теории графов: https://sites.google.com/view/textgraphs2020
Вопросы по семинару можно направлять @apanc.


2019 December 18
Так как я большой фанат мультиязычных моделей
Cross-Lingual Ability of Multilingual BERT: An Empirical Study
Karthikeyan K et al.
arxiv.org/abs/1912.07840
Our experiments reveal some interesting and surprising results like the fact that word-piece overlap on the one hand, and multi-head attention on the other, are both not significant, whereas structural similarity and the depth of B-BERT are crucial for its cross-lingual ability.
Cross-Lingual Ability of Multilingual BERT: An Empirical Study
Karthikeyan K et al.
arxiv.org/abs/1912.07840
Our experiments reveal some interesting and surprising results like the fact that word-piece overlap on the one hand, and multi-head attention on the other, are both not significant, whereas structural similarity and the depth of B-BERT are crucial for its cross-lingual ability.
2019 December 19
Давайте признаемся, что все мы любим писать код в ноутбуках. Потому что итерироваться удобно и есть доступ к глобальному стейту, что позволяет обходиться принтами для дебагатв 99% случаев
Ellis el al. MIT решили, что почему бы не попробовать научить нейросетку писать программы в такой же парадигме: read-eval-print-loop. И вроде бы даже получилось.
papers.nips.cc/paper/9116-write-execute-assess-program-synthesis-with-a-repl
Ellis el al. MIT решили, что почему бы не попробовать научить нейросетку писать программы в такой же парадигме: read-eval-print-loop. И вроде бы даже получилось.
papers.nips.cc/paper/9116-write-execute-assess-program-synthesis-with-a-repl
Но ничего не сравнится с этой новостью: в Git 2.23 для переключения между брачными можно будет использовать команду
Потому что авторитаризм
github.com/git/git/blob/master/Documentation/RelNotes/2.23.0.txt
Не будьте как персонажи этого комикса, учите гит.
git switch <branch_name>, а для рестора файла на предыдущую версию: git restore <file>
Потому что авторитаризм
git checkout нужно прекращать.github.com/git/git/blob/master/Documentation/RelNotes/2.23.0.txt
Не будьте как персонажи этого комикса, учите гит.


2019 December 20
Спасибо @someotherusername за наводку на забавную статью на хабре
habr.com/ru/post/481228
В статье больше рассказывается про историю генерации языка, чем вообще про NLP. Вообще интересно посмотреть в очень сильной ретроспективе, как люди пытались формализовать язык в разное время и где мы сейчас.
habr.com/ru/post/481228
В статье больше рассказывается про историю генерации языка, чем вообще про NLP. Вообще интересно посмотреть в очень сильной ретроспективе, как люди пытались формализовать язык в разное время и где мы сейчас.

2019 December 22
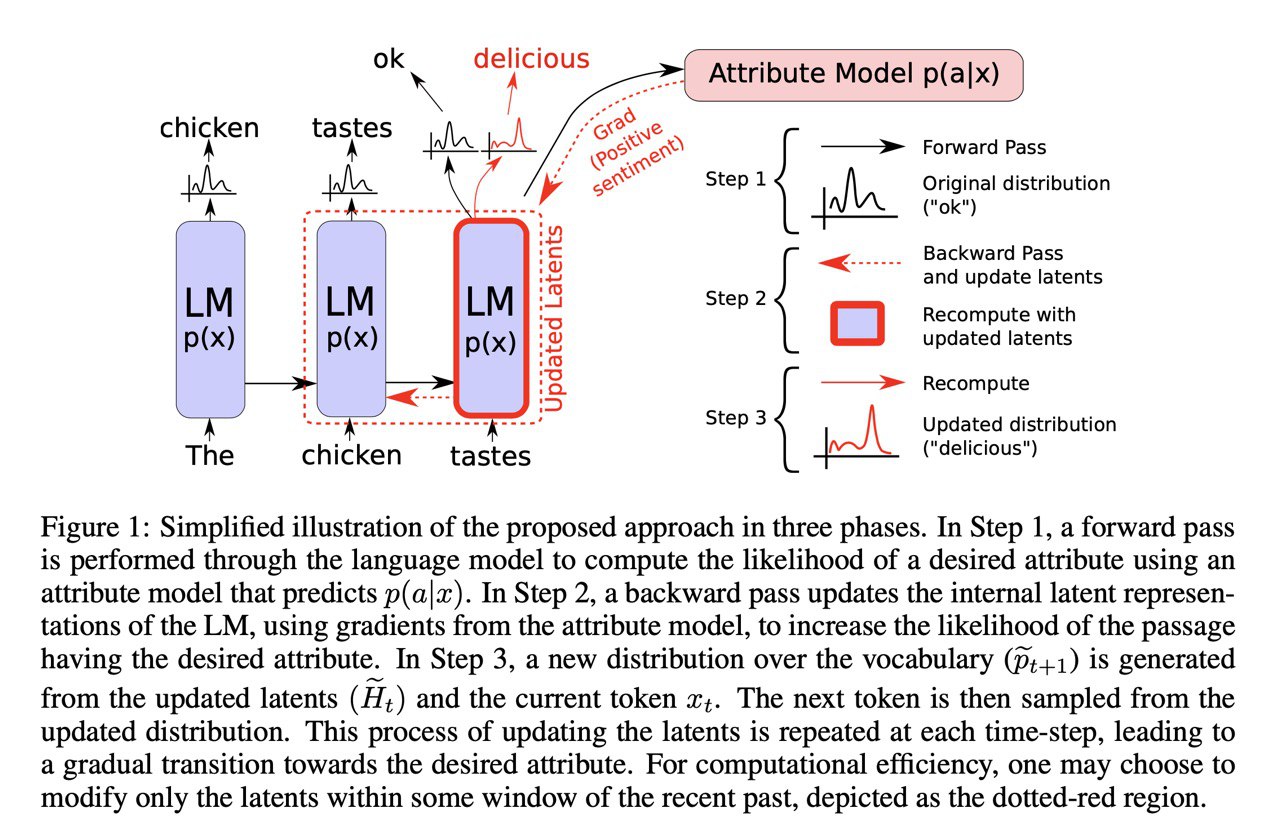
Plug and Play Language Models: a Simple Approach to Controlled Text Generation
Dathathri et al. [Uber AI]
arxiv.org/abs/1912.02164
Про эту статью уже был небольшой пост, но теперь захотелось разобрать её подбробнее.
Допустим, вы хотите сгенерировать текст с определёнными праметрами (e.g., позитивный отзыв на определённый сериал) и у вас есть обычный GPT-2, который всего этого не умеет. Можно, конечно, зафайнтюнить его на ваши тексты, но во-первых это долго, во-вторых: это требует большого числа текстов, в-третьих: под каждую комбинацию параметров (негативный отзыв / другой сериал) нужно повторять процесс заново.
Авторы предлагают новый подход: Plug and Play LM (PPLM). Для генерации используется стандартный предобученный GPT-2 + пачка классификаторов (для каждого из ваших параметров) и текст генерится итеративно:
1. сгенерили новое слово
2. прогнали это через классификатор
3. посчитали градиент логвероятности требуемого класса по представлениям GPT-2
4. обновили втутренние представления, чтобы максимизировтаь эту вероятность
5. повторили 2-4 несколько раз (~3-10)
6. повторили 1-5 пока нас не устраивает длина
Чтобы тексты были более реалистичные:
1. к objective (логвероятность класса) добавляем регуляризацию на KL между PPLM и GPT-2
1. семплиируем из смешанных веростностей PPLM и PGT-2 (post-norm fusion)
Способ несколько хитрый и медленный, но нужно обучать нужно только лишь классификаторы. В статье утверждают, что работает как минимум не хуже файнтюнинга / CTRL.
Dathathri et al. [Uber AI]
arxiv.org/abs/1912.02164
Про эту статью уже был небольшой пост, но теперь захотелось разобрать её подбробнее.
Допустим, вы хотите сгенерировать текст с определёнными праметрами (e.g., позитивный отзыв на определённый сериал) и у вас есть обычный GPT-2, который всего этого не умеет. Можно, конечно, зафайнтюнить его на ваши тексты, но во-первых это долго, во-вторых: это требует большого числа текстов, в-третьих: под каждую комбинацию параметров (негативный отзыв / другой сериал) нужно повторять процесс заново.
Авторы предлагают новый подход: Plug and Play LM (PPLM). Для генерации используется стандартный предобученный GPT-2 + пачка классификаторов (для каждого из ваших параметров) и текст генерится итеративно:
1. сгенерили новое слово
2. прогнали это через классификатор
3. посчитали градиент логвероятности требуемого класса по представлениям GPT-2
4. обновили втутренние представления, чтобы максимизировтаь эту вероятность
5. повторили 2-4 несколько раз (~3-10)
6. повторили 1-5 пока нас не устраивает длина
Чтобы тексты были более реалистичные:
1. к objective (логвероятность класса) добавляем регуляризацию на KL между PPLM и GPT-2
1. семплиируем из смешанных веростностей PPLM и PGT-2 (post-norm fusion)
Способ несколько хитрый и медленный, но нужно обучать нужно только лишь классификаторы. В статье утверждают, что работает как минимум не хуже файнтюнинга / CTRL.

И список заинтересовавших за неделю постов/статей/новостей:
1. How This Bootcamp in the US Could Reduce Their Quiz to ~5 mins - неплохой пример того, как удачно использовать ML в задаче не про ML и о том, как правильно считать feature importance.
1. Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model - weak supervision на випипедии для улучшения commonsence knowledge. Похоже на костыль, но хороший пример weak supervision.
1. 🤗 pipelines (beta) - готовые пайплайны предобработки для типичных задач NLU (e.g., extractive QA, classification, …). Пока что не видел удачных примеров унификации предобработки в NLP, но есть надежда на 🤗
1. Зарелижен код к Neural Text Generation with Unlikelihood Training
1. 200 years of diachronic word embeddings on largest available newspaper collections for English, Finnish, Dutch and Swedish - отличный ресурс для изучения того, как менялись значения слов в течении 200 лет, ещё и заалайненый в общее между языками пространство (вроде бы).
1. A Survey on Document-level Machine Translation: Methods and Evaluation - обзор методов переводов документов (и в принципе NMT), достаточно неплохой
1. Туториал по nbdev - ещё один шанс полюбить (возненавидеть) интерактиивный подход к разработке
1. How This Bootcamp in the US Could Reduce Their Quiz to ~5 mins - неплохой пример того, как удачно использовать ML в задаче не про ML и о том, как правильно считать feature importance.
1. Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model - weak supervision на випипедии для улучшения commonsence knowledge. Похоже на костыль, но хороший пример weak supervision.
1. 🤗 pipelines (beta) - готовые пайплайны предобработки для типичных задач NLU (e.g., extractive QA, classification, …). Пока что не видел удачных примеров унификации предобработки в NLP, но есть надежда на 🤗
1. Зарелижен код к Neural Text Generation with Unlikelihood Training
1. 200 years of diachronic word embeddings on largest available newspaper collections for English, Finnish, Dutch and Swedish - отличный ресурс для изучения того, как менялись значения слов в течении 200 лет, ещё и заалайненый в общее между языками пространство (вроде бы).
1. A Survey on Document-level Machine Translation: Methods and Evaluation - обзор методов переводов документов (и в принципе NMT), достаточно неплохой
1. Туториал по nbdev - ещё один шанс полюбить (возненавидеть) интерактиивный подход к разработке

2020 January 04
Надеюсь большинство из вас уже очнулисось от новогоднего безумия, доело оливье и готово диплёрнить дальше.
Начать год хочется с хорошего, но пост будет про боль.
Отличный блогпост про опыт публикации инди-исследователя и почему не нужно им становиться.
TL;DR
Топовые университеты не берут на PhD без 1-2 публикаций на топовых конференциях. Можно попытаться написать эти статьи за год, работая над ними фултайм (50-100 часов в неделю) и подрабатывая фрилансером. Но по факту нет, и это будет очень больно. Не делайте так.
Кроме этого в статье много общеполезных советов:
1. Занимайтесь одновременно несколькими проектами - если один из них провалится, будет не так больно, а кроме этого успехи маленьких сайд-проектов будут вам помогать тащить основной
1. Обязательно обсуждайте свою работу с теми, кто может дать совет и/или конструктивно критиковать вас
1. Скорее всего вашу первую версию статьи не примут к публикации на топовых конференциях. Не сокрушайтесь, исправляйте косяки и сабмитьте на другую конференцию.
1. Некоторые сайд-проекты или (достаточно отдалённые от основной темы) куски вашей статьи можно отправить на воркшоп.
1. Читайте phdcomics.com
Начать год хочется с хорошего, но пост будет про боль.
Отличный блогпост про опыт публикации инди-исследователя и почему не нужно им становиться.
TL;DR
Топовые университеты не берут на PhD без 1-2 публикаций на топовых конференциях. Можно попытаться написать эти статьи за год, работая над ними фултайм (50-100 часов в неделю) и подрабатывая фрилансером. Но по факту нет, и это будет очень больно. Не делайте так.
Кроме этого в статье много общеполезных советов:
1. Занимайтесь одновременно несколькими проектами - если один из них провалится, будет не так больно, а кроме этого успехи маленьких сайд-проектов будут вам помогать тащить основной
1. Обязательно обсуждайте свою работу с теми, кто может дать совет и/или конструктивно критиковать вас
1. Скорее всего вашу первую версию статьи не примут к публикации на топовых конференциях. Не сокрушайтесь, исправляйте косяки и сабмитьте на другую конференцию.
1. Некоторые сайд-проекты или (достаточно отдалённые от основной темы) куски вашей статьи можно отправить на воркшоп.
1. Читайте phdcomics.com

2020 January 05
Внезапно оказалось, что у Microsoft Research есть свой подкаст. И он довольно хорош.

Несколько забавных статей, которые сейчас обсуждают в твиттере.
AdderNet: Do We Really Need Multiplications in Deep Learning?
Chen et al. [Huawei Noah’s Ark Lab et al.]
arxiv.org/abs/1912.13200
Умножать сложнее, чем складывать. Об этом подумали в Huawei и сделали новый нейросетевой фремворк, который использует только сложение. Пока что придумали только для CNN и там куча хитростей, плюс геометрическая интерпретация неочевидна, но выглядит мегаинтересно.
A General and Adaptive Robust Loss Function
Barron [Google Research]
arxiv.org/abs/1701.03077
Вообще в этом мире используют не только кросс-энтропию, но и множество других функций потерь. Barron придумал, как всё это разнообразие можно обобщить, и получить в руки ещё один гиперпараметр, который поможет вам за(овер)фититься. Кроме этого новый лосс обладает интереснымии свойствами теоретически полезными для VAE.
Recurrent Independent Mechanisms
Goyal et al. [MILA]
arxiv.org/abs/1909.10893
Хитрая комбинация из нескольких RNN, обменивающихся друг с другом информацией с помощью attention. Протестировано на очень искуственной таске, но обходит на ней трансформеры. Было бы интересно поиграться с этой штукой на задачас с длиннымии текстами.
AdderNet: Do We Really Need Multiplications in Deep Learning?
Chen et al. [Huawei Noah’s Ark Lab et al.]
arxiv.org/abs/1912.13200
Умножать сложнее, чем складывать. Об этом подумали в Huawei и сделали новый нейросетевой фремворк, который использует только сложение. Пока что придумали только для CNN и там куча хитростей, плюс геометрическая интерпретация неочевидна, но выглядит мегаинтересно.
A General and Adaptive Robust Loss Function
Barron [Google Research]
arxiv.org/abs/1701.03077
Вообще в этом мире используют не только кросс-энтропию, но и множество других функций потерь. Barron придумал, как всё это разнообразие можно обобщить, и получить в руки ещё один гиперпараметр, который поможет вам за(овер)фититься. Кроме этого новый лосс обладает интереснымии свойствами теоретически полезными для VAE.
Recurrent Independent Mechanisms
Goyal et al. [MILA]
arxiv.org/abs/1909.10893
Хитрая комбинация из нескольких RNN, обменивающихся друг с другом информацией с помощью attention. Протестировано на очень искуственной таске, но обходит на ней трансформеры. Было бы интересно поиграться с этой штукой на задачас с длиннымии текстами.