BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
Lewis et al. [FAIR]
arxiv.org/abs/1910.13461Ok, people. We all know that seq2seq is kinda the most general task in NLP. So every pre-training task we have can be built into it. Let’s add some new ones and see what happends.
List of tasks:
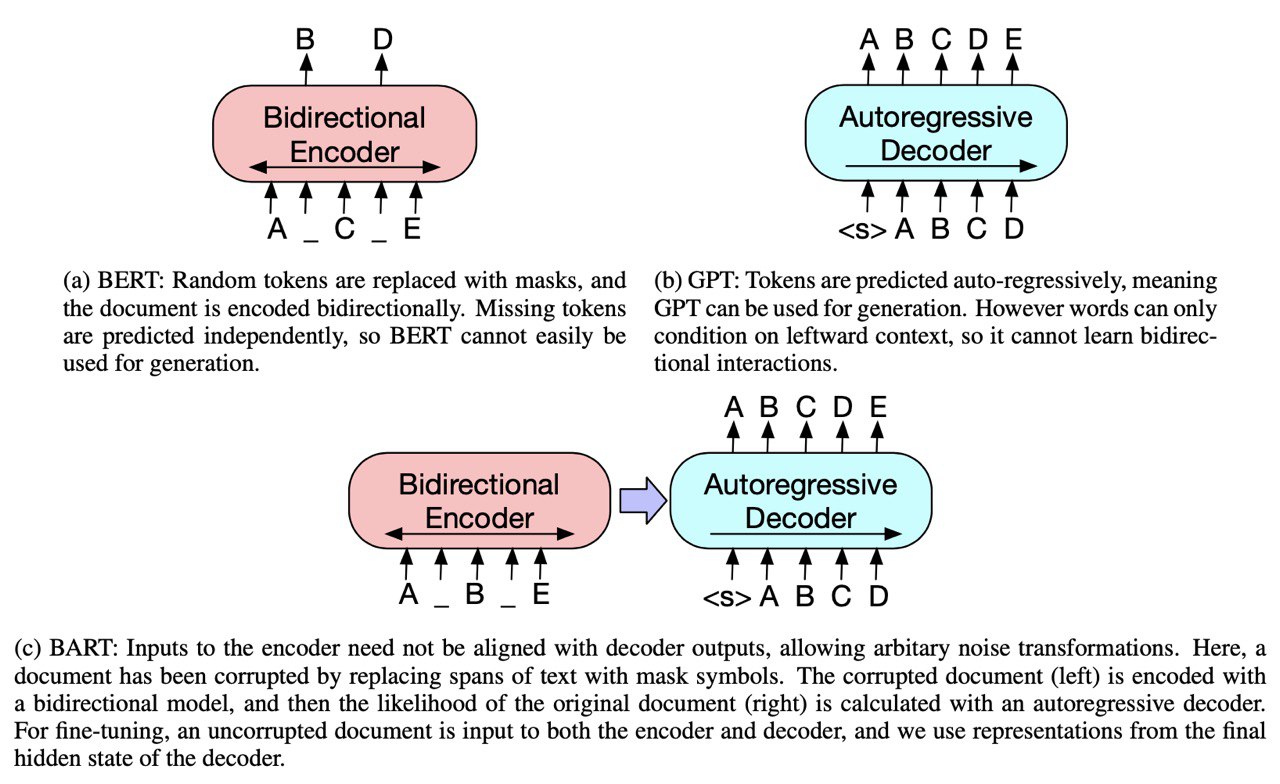
1. Masked Language Modelling
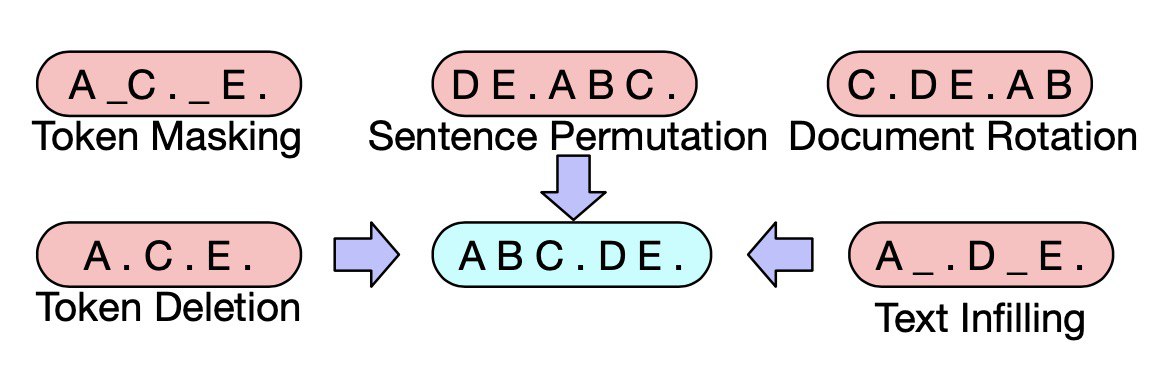
1. Random Token Deletion
1. Text Infilling - replase a sequence of tokens with a
single MASK token, restore them all (not knowing how many was deleted)
1. Sentence Shuffling - permute the sentences, restore them in the original order
1. Document Rotation - select random token, start document from this token and when it ends continue it with the first token, model should restore the document starting with the original token
After some experiments authors chose two tasks: Text Infilling and Sentence Shuffling and train seq2seq on this two tasks in RoBERTa setup.
Results: compatible to RoBERTa on NLU (GLUE, SQuAD, …) and
SOTA on NLG (ELI5, XSum, CNN/DailyMail, PersonaChat). But not-so-good metrics at (Romanian-English) translation.