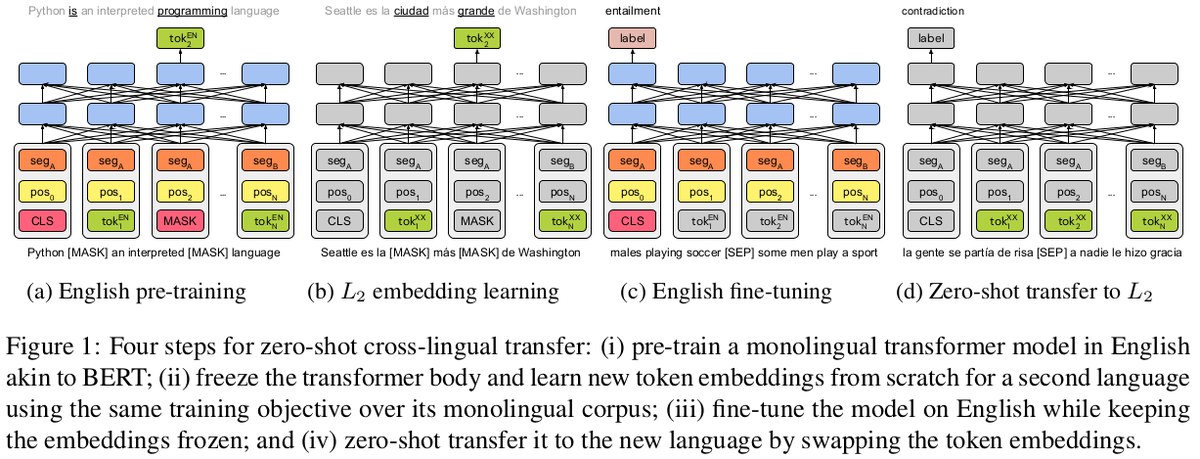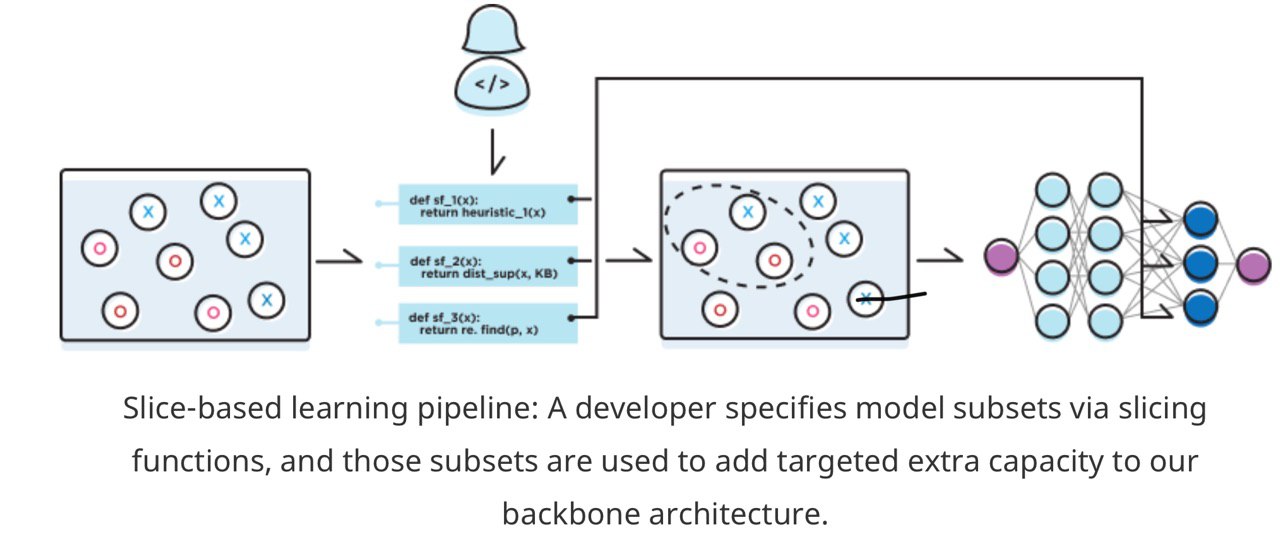
из твиттера рудера:
Most of the world’s text is not in English. We are releasing MultiFiT to train and fine-tune language models efficiently in any language.
Post: http://nlp.fast.ai/classification/2019/09/10/multifit.html
Paper: https://arxiv.org/abs/1909.04761
Abstract
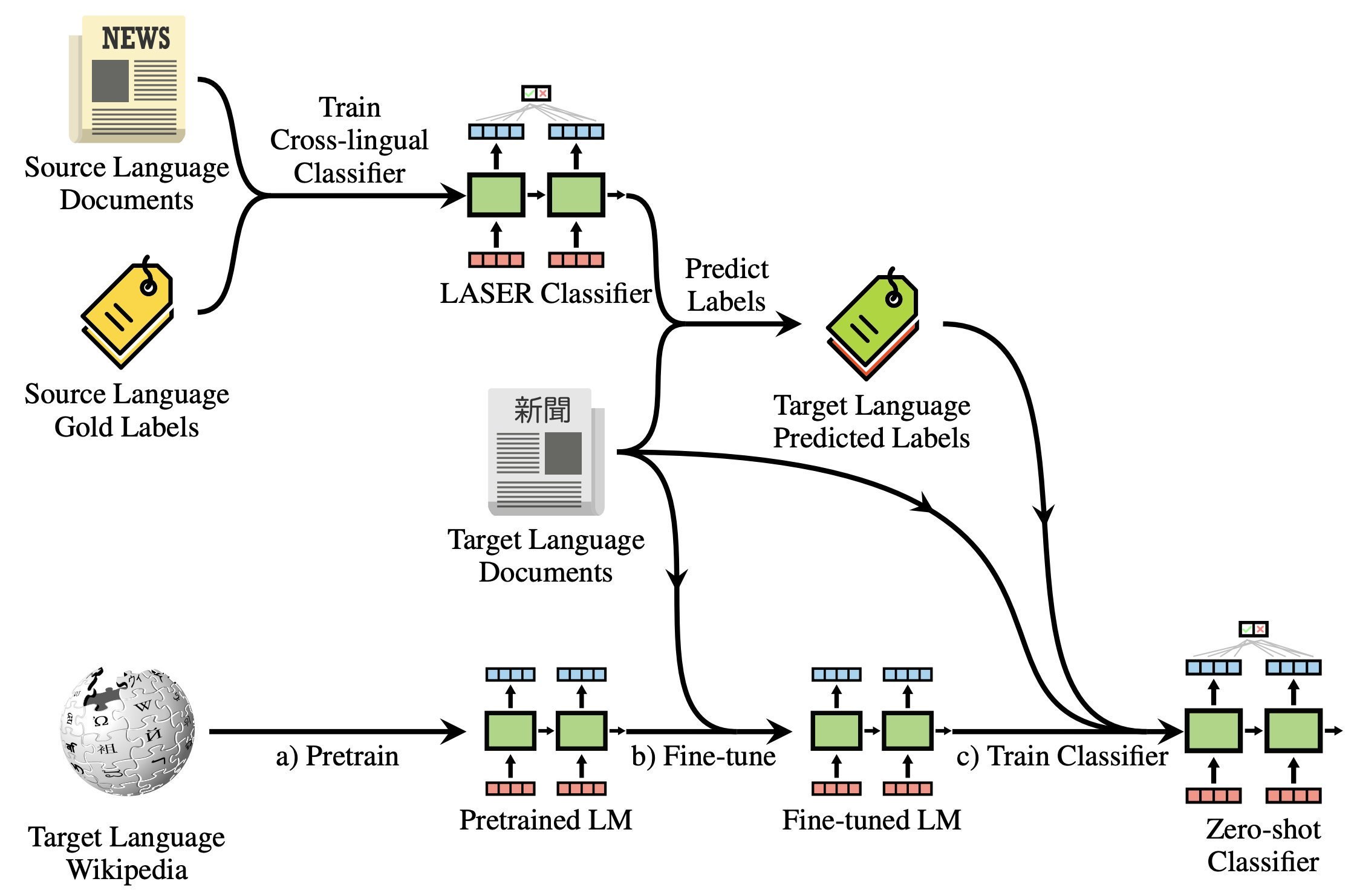
Pretrained language models are promising particularly for low-resource languages as they only require unlabelled data. However, training existing models requires huge amounts of compute, while pretrained cross-lingual models often underperform on low-resource languages. We propose Multi lingual language model Fine-Tuning (MultiFiT) to enable practitioners to train and fine-tune language models efficiently in their own language. In addition, we propose a zero-shot method using an existing pretrained cross-lingual model. We evaluate our methods on two widely used cross-lingual classification datasets where they outperform models pretrained on orders of magnitude more data and compute. We release all models and code.