Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges
Arivazhagan et al. [Google Brain]
arxiv.org/abs/1907.05019We also studied other properties of very deep networks, including the depth-width trade-off, trainability challenges and design choices for scaling
Transformers to over
1500 layers with
84 billion parameters.А теперь немного серьёзнее. Как они до такого дошли?
Идея: многоязычные системы машинного перевода существуют уже давно, но обычно их обучают на нескольких high-resource языках (гигабайты текста); но почему бы не попробовать обучить их на
103 языках (
25 млн. пар предложений) и посмотреть на BLEU en⟼any и any⟼ en?
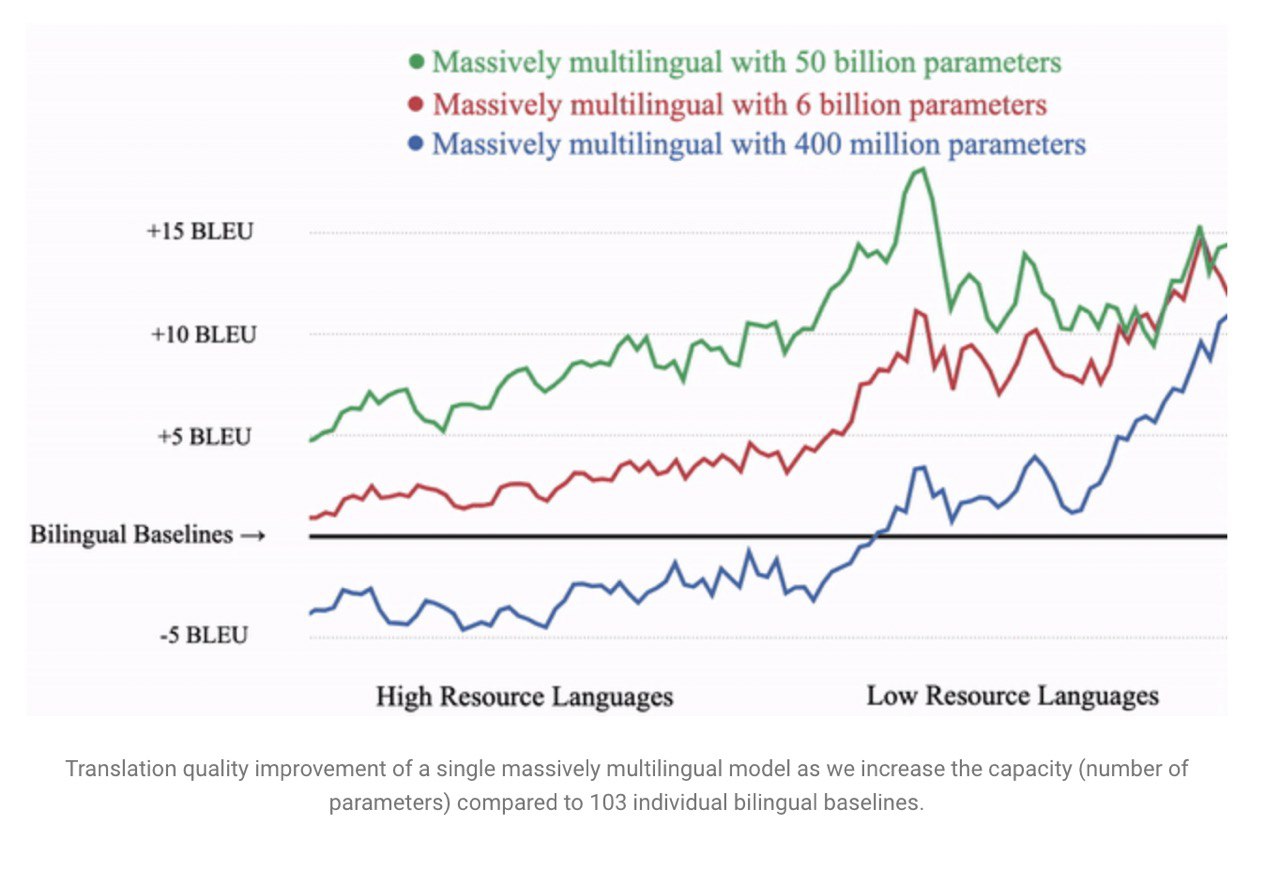
При модели
Transformer-Big, стандартной для машинного перевода, у высокоресурсных языков (немецкий, французский, …) качество падает относительно двуязычного бейзлайна (максимум -5 BLEU). Однако, BLEU низкоресурсных языков (йоруба, синдхи, савайский, …) растёт вплоть до +10 BLEU (в среднем +5). И это очень заметное улучшение.
Но как сохранить высокочастотные языки? Возможно, модель просто недостаточно ёмкая, чтобы выучить их одновременно с низкочастотными (попробуйте сами выучить сотню языков). Как проверить эту гипотезу? Увеличить модель до безумных размеров!
Способа увеличить модельку два: в ширину и в глубину.
1.
Wide transformer (24 слоя, 32 головы, 2048 attention hidden, 16384 fc-hidden, 1.3B total)
2.
Deep transformer (48 слоёв, 16 голов, 1024 attention hidden, 4096 fc-hidden, 1.3B total)
Результат: ещё больший прирост в низкоресурсных, появился прирост в среднересурсных, потерь в высокоресурсных почти нет.
статья в блоге:
ai.googleblog.com/2019/10/exploring-massively-multilingual.htmlза ссылку спасибо
@twlvthP.S. Заявленная в блоге модель на 84B параметров в тексте статьи так и не появилась =(
Гугл, не надо так.
P.P.S Также очень советую посмотреть статью. В ней много подробностей о тренировке, e.g. как правильно семплить языки и больше интересных резульатов. В один пост не уместить.