



Size: a a a
2019 November 26

The lottery ticket hypothesis suggests that by training DNNs from “lucky” initializations, we can train networks which are 10-100x smaller with minimal performance losses. In new work, we extend our understanding of this phenomenon in several ways... https://ai.facebook.com/blog/understanding-the-generalization-of-lottery-tickets-in-neural-networks https://twitter.com/facebookai/status/1199042155743862784/video/1
Do lottery tickets contain generic inductive biases or are they overfit to the particular dataset and optimizer used to find them? Encouragingly, we found that lottery tickets generalize across related, but distinct datasets and across optimizers: https://arxiv.org/abs/1906.02773
Is the lottery ticket phenomenon a general property of DNNs or merely an artifact of supervised image classification? We show that the lottery ticket phenomenon is a general property which is present in both #reinforcementlearning and #NLP
Can we begin to explain lottery tickets theoretically? We introduce a new theoretical framework on the formation of lottery tickets to help researchers advance toward a better understanding of lucky initializations
Via twitter.com/facebookai/status/1199042159334154241
Do lottery tickets contain generic inductive biases or are they overfit to the particular dataset and optimizer used to find them? Encouragingly, we found that lottery tickets generalize across related, but distinct datasets and across optimizers: https://arxiv.org/abs/1906.02773
Is the lottery ticket phenomenon a general property of DNNs or merely an artifact of supervised image classification? We show that the lottery ticket phenomenon is a general property which is present in both #reinforcementlearning and #NLP
Can we begin to explain lottery tickets theoretically? We introduce a new theoretical framework on the formation of lottery tickets to help researchers advance toward a better understanding of lucky initializations
Via twitter.com/facebookai/status/1199042159334154241
И немного новостей из параллельного (но очень близкого) NLP мира
We just released the paper and code for Mellotron: a multispeaker voice synthesis model that can make a voice emote and sing without emotive or singing training data.
https://github.com/NVIDIA/mellotron
Via twitter.com/RafaelValleArt/status/1199017762774900738
We just released the paper and code for Mellotron: a multispeaker voice synthesis model that can make a voice emote and sing without emotive or singing training data.
https://github.com/NVIDIA/mellotron
Via twitter.com/RafaelValleArt/status/1199017762774900738

2019 November 27
Переслано от Anya Bataeva
2019 November 28
Переслано от Петр Остроухов...
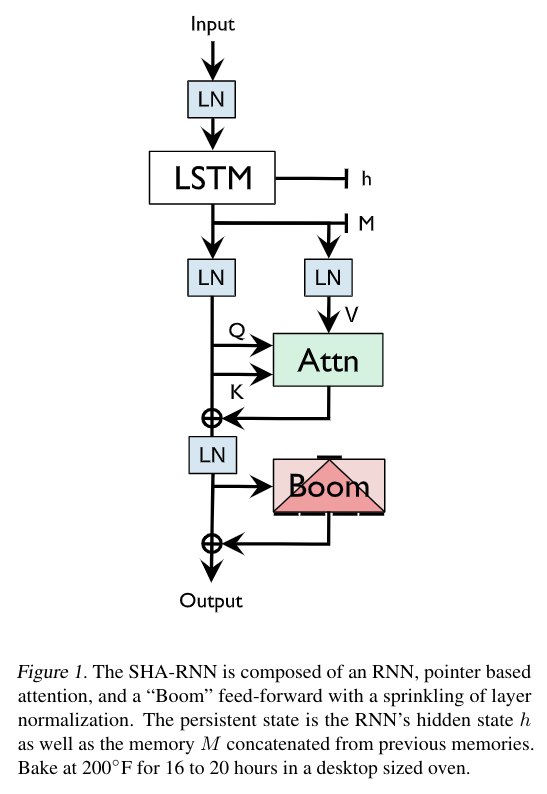
Новый гайд от Jay Alammar по использованию BERT https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/
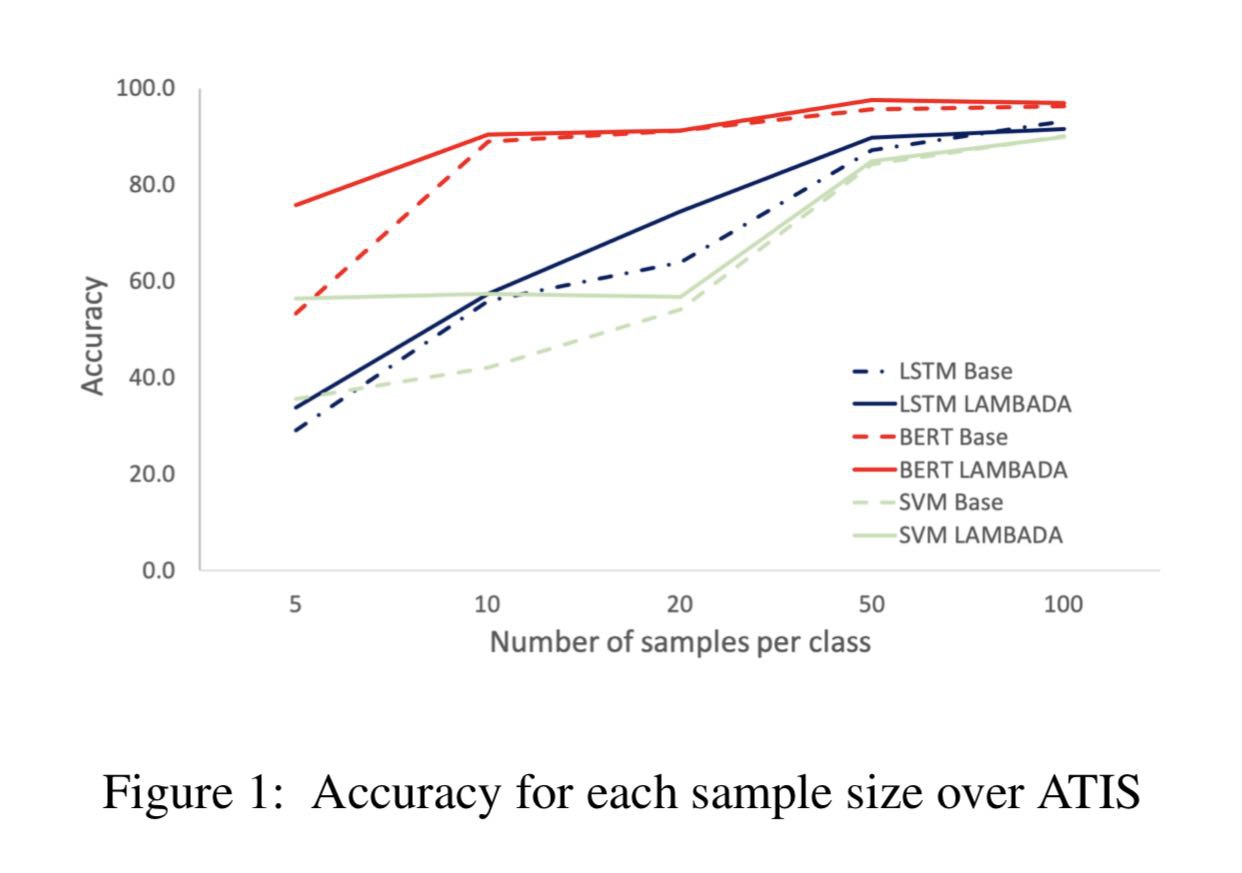
Not Enough Data? Deep Learning to the Rescue!
Anaby-Tavor et al
https://arxiv.org/abs/1911.03118
Метод аугментации текстового датасета через генерацию примеров на основе языковой модели. Эксперименты не очень убедительны, но вроде бы метод даёт хороший буст, если примеров класса меньше 10.
Anaby-Tavor et al
https://arxiv.org/abs/1911.03118
Метод аугментации текстового датасета через генерацию примеров на основе языковой модели. Эксперименты не очень убедительны, но вроде бы метод даёт хороший буст, если примеров класса меньше 10.

2019 November 30
How Much Over-parameterization Is Sufficient to Learn Deep ReLU Networks?
Chen et al., 2019 [UCLA]
arxiv.org/abs/1911.12360
The theory of deep learning is a new and fast-developing field. Recent studies suggest that huge over-parametrization of neural networks is not a bug, but a feature that allows deep NNs both to generalize and to be optimizable using simple (first-order gradient) optimization.
Chen et al. make another step into solving mysteries of deep learning, and their main results are:
1. Sharp optimization and generalization guarantees for deep ReLU networks
1. Better asymptotics that allows applying the theory to smaller networks (polylogarithmic instead of polynomial hidden size)
As authors say, "Our results push the study of over-parameterized deep neural networks towards more practical settings."
For a deep dive to a theory of deep learning, I suggest
iPavlov: github.com/deepmipt/tdl (Russian and English)
Stanford: stats385.github.io (English)
Chen et al., 2019 [UCLA]
arxiv.org/abs/1911.12360
The theory of deep learning is a new and fast-developing field. Recent studies suggest that huge over-parametrization of neural networks is not a bug, but a feature that allows deep NNs both to generalize and to be optimizable using simple (first-order gradient) optimization.
Chen et al. make another step into solving mysteries of deep learning, and their main results are:
1. Sharp optimization and generalization guarantees for deep ReLU networks
1. Better asymptotics that allows applying the theory to smaller networks (polylogarithmic instead of polynomial hidden size)
As authors say, "Our results push the study of over-parameterized deep neural networks towards more practical settings."
For a deep dive to a theory of deep learning, I suggest
iPavlov: github.com/deepmipt/tdl (Russian and English)
Stanford: stats385.github.io (English)

2019 December 01
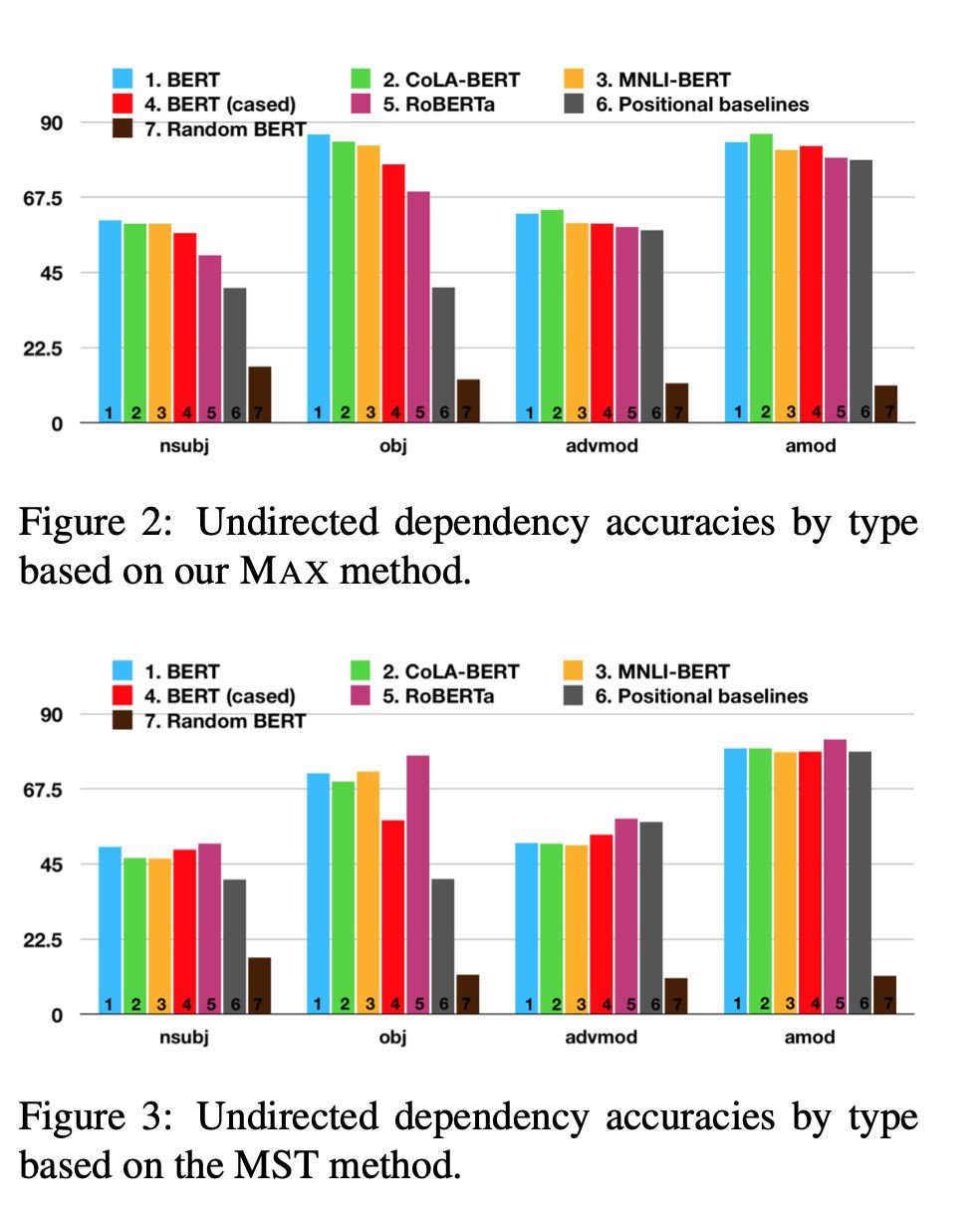
Do Attention Heads in BERT Track Syntactic Dependencies?
Mon Htut et al. [NYU]
arxiv.org/abs/1911.12246
“Our results suggest that these models have some specialist attention heads that track individual dependency types, but no generalist head that performs holistic parsing significantly better than a trivial baseline, and that analyzing attention weights directly may not reveal much of the syntactic knowledge that BERT-style models are known to learn.
We also analyze BERT fine-tuned on two datasets — the syntax-oriented CoLA and the semantics-oriented MNLI — but we do not observe substantial differences in the overall dependency relations extracted using our methods.”
Mon Htut et al. [NYU]
arxiv.org/abs/1911.12246
“Our results suggest that these models have some specialist attention heads that track individual dependency types, but no generalist head that performs holistic parsing significantly better than a trivial baseline, and that analyzing attention weights directly may not reveal much of the syntactic knowledge that BERT-style models are known to learn.
We also analyze BERT fine-tuned on two datasets — the syntax-oriented CoLA and the semantics-oriented MNLI — but we do not observe substantial differences in the overall dependency relations extracted using our methods.”
2019 December 02
The Dialogue Dodecathlon
https://parl.ai/projects/dodecadialogue/
TL;DR
Собрали вместе 12 диалоговых датасетов, обучили на них transformer-based seq2seq модель в multitasking режиме и получили SOTA на всех 12 задачах.
Суть подхода
Две идеи для обучения генеративной диалоговой модели, работающей в open-domain сеттинге:
1. Для предобучения лучше использовать диалоговые данные (Reddit), а не произвольные текстовые (например, WebText, на котором учили GPT2).
2. Лучше учить модели в multi-tasking режиме:
- во-первых, удобно иметь одну универсальную модель, а не 10-20 специализированных;
- во-вторых, в теории обучение на одних задачах может помочь в достижении хороших результатах на других; поэтому среди рассмотренных в статье датасетов есть не только текстовые, но и QA-датасеты по картинкам.
Датасеты, рассмотренные в статье:
- ConvAI - кондишен на факты о персоне
- DailyDialog - обсуждение разных повседневных тем
- Wiz. of Wikipedia - кондишен на факты из википедии
- Empathetic Dialog - обсуждение жизненные ситуаций в дружелюбной (терапевтической) манере
- Cornell Movie - субтитры
- LIGHT - roll-play в выдуманных ситуациях
- ELI5 - вопросы и ответы в длинной форме
- Ubuntu - чат поддержки
- Twitter - twitter
- pushshift.io Reddit - 2.2 миллиарда предложений с реддита на разные темы
- Image Chat - обсуждение персон на картинках
- IGC - вопросы и ответы по картинкам на разные темы
Результаты
В качестве бейзлайна взяли предобученную GPT2-модель в реализации hugging face'a (которую в статье почему-то называют BERT'ом).
В качестве конкурента использовали transformer-based seq2seq модель из своего ParlAI, в которую в частности добавили возможность кондишениться на фичи, извлеченные из картинок.
Вывод 1.
Лучшая стратегия претрейна для диалоговых моделей - обучаться на огромном датасетете pushshifit.io Reddit (2.2 миллиарда предложений). Претрейн на твиттере и использование весов GPT2 существенно проигрывает по perplexity.
Для справки - свой seq2seq на Reddit'e они они учили две недели на 64-ех Nvidia V100.
Вывод 2.
Если после предобучения на Reddit'e доучивать модель на всех 12-задачах в multi-tasking режиме, уже получается универсальная модель, которая бьет почти все предыдущие task-specific модели по perplexity и специфичным метрикам типа BLEU / ROUGE / F1.
Вывод 3.
Наиболее результативным остается подход с finetune'ом модели на конкретную задачу: сначала идет предобучение на Reddit'a, потом обучение на всех задачах в multitasking режими, а потом finetune на конкретную задачу. При таком подходе получаются новые SOTA-модели для всех 12 задач.
Вывод 4.
Пожалуй, самый интересный результат статьи связан с так называемым Leave-One-Out Zero-Shot Performance: дообучаемся в multitasking режиме на всех датасетах, кроме одного, а тестируемся на оставшемся.
Авторы статьи показали, что и в этом случае метрики на новом датасете также очень приличные (если только не выкидывать Reddit из дообучения), что говорит о том, что multitasking-обучение способствует лучшему обобщению модели и "переносу знаний" на новые домены.
https://parl.ai/projects/dodecadialogue/
TL;DR
Собрали вместе 12 диалоговых датасетов, обучили на них transformer-based seq2seq модель в multitasking режиме и получили SOTA на всех 12 задачах.
Суть подхода
Две идеи для обучения генеративной диалоговой модели, работающей в open-domain сеттинге:
1. Для предобучения лучше использовать диалоговые данные (Reddit), а не произвольные текстовые (например, WebText, на котором учили GPT2).
2. Лучше учить модели в multi-tasking режиме:
- во-первых, удобно иметь одну универсальную модель, а не 10-20 специализированных;
- во-вторых, в теории обучение на одних задачах может помочь в достижении хороших результатах на других; поэтому среди рассмотренных в статье датасетов есть не только текстовые, но и QA-датасеты по картинкам.
Датасеты, рассмотренные в статье:
- ConvAI - кондишен на факты о персоне
- DailyDialog - обсуждение разных повседневных тем
- Wiz. of Wikipedia - кондишен на факты из википедии
- Empathetic Dialog - обсуждение жизненные ситуаций в дружелюбной (терапевтической) манере
- Cornell Movie - субтитры
- LIGHT - roll-play в выдуманных ситуациях
- ELI5 - вопросы и ответы в длинной форме
- Ubuntu - чат поддержки
- Twitter - twitter
- pushshift.io Reddit - 2.2 миллиарда предложений с реддита на разные темы
- Image Chat - обсуждение персон на картинках
- IGC - вопросы и ответы по картинкам на разные темы
Результаты
В качестве бейзлайна взяли предобученную GPT2-модель в реализации hugging face'a (которую в статье почему-то называют BERT'ом).
В качестве конкурента использовали transformer-based seq2seq модель из своего ParlAI, в которую в частности добавили возможность кондишениться на фичи, извлеченные из картинок.
Вывод 1.
Лучшая стратегия претрейна для диалоговых моделей - обучаться на огромном датасетете pushshifit.io Reddit (2.2 миллиарда предложений). Претрейн на твиттере и использование весов GPT2 существенно проигрывает по perplexity.
Для справки - свой seq2seq на Reddit'e они они учили две недели на 64-ех Nvidia V100.
Вывод 2.
Если после предобучения на Reddit'e доучивать модель на всех 12-задачах в multi-tasking режиме, уже получается универсальная модель, которая бьет почти все предыдущие task-specific модели по perplexity и специфичным метрикам типа BLEU / ROUGE / F1.
Вывод 3.
Наиболее результативным остается подход с finetune'ом модели на конкретную задачу: сначала идет предобучение на Reddit'a, потом обучение на всех задачах в multitasking режими, а потом finetune на конкретную задачу. При таком подходе получаются новые SOTA-модели для всех 12 задач.
Вывод 4.
Пожалуй, самый интересный результат статьи связан с так называемым Leave-One-Out Zero-Shot Performance: дообучаемся в multitasking режиме на всех датасетах, кроме одного, а тестируемся на оставшемся.
Авторы статьи показали, что и в этом случае метрики на новом датасете также очень приличные (если только не выкидывать Reddit из дообучения), что говорит о том, что multitasking-обучение способствует лучшему обобщению модели и "переносу знаний" на новые домены.
Хипстеры из fast.ai переизобрели Jupyter-ноутбуки. Нужно будет попробовать.
fast.ai/2019/12/02/nbdev
Трэд в твиттере с примерами:
twitter.com/jeremyphoward/status/1201447678346842112
fast.ai/2019/12/02/nbdev
Трэд в твиттере с примерами:
twitter.com/jeremyphoward/status/1201447678346842112
В случайной сетке нашли подсетку, которая работает сравнимо с resnet-34 и при этом меньше resnet-34. Алгоритм поиска прилагается. Пора исследовать таким образом трансформеры.
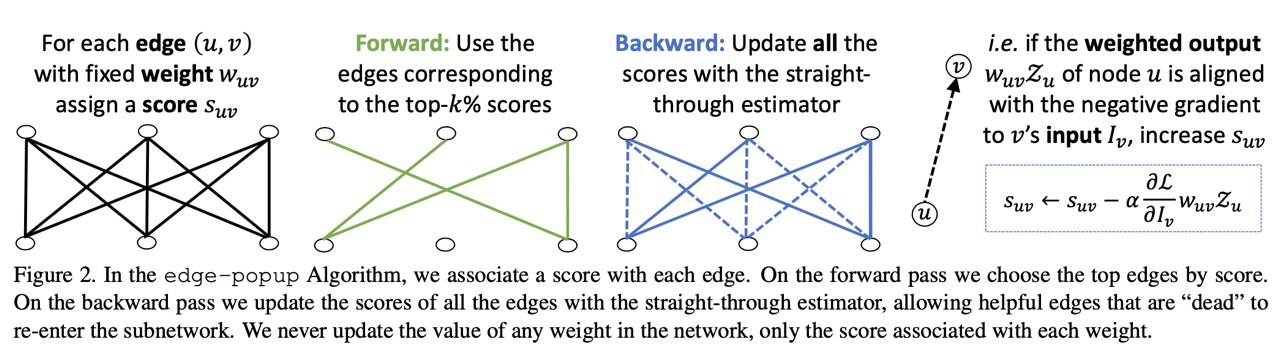
иллюстрация алгоритма
2019 December 03
Попробовал nbdev. Пока что кажется очень сырой штукой, к которой обязательно нужны туториалы для использования. Ховард обещал - будем ждать.
2019 December 04
Towards Lingua Franca Named Entity Recognition with BERT
Moon, Awasthy et al. [IBM]
arxiv.org/abs/1912.01389
Мультиязычный NER + различные исследования вокруг него. SOTA на CoNLL02 (голландский и испанский), OntoNotes (арабский и китайский)
Moon, Awasthy et al. [IBM]
arxiv.org/abs/1912.01389
Мультиязычный NER + различные исследования вокруг него. SOTA на CoNLL02 (голландский и испанский), OntoNotes (арабский и китайский)
Writing Across the World's Languages: Deep Internationalization for Gboard, the Google Keyboard
Vaan Esch et al. [Google]
arxiv.org/abs/1912.01218
Technical report о google keyboard и том как туда добавили 900 языков.
Кажется, большие компании начинают вспоминать, что в этом мире существуют другие языки, кроме английского.
Vaan Esch et al. [Google]
arxiv.org/abs/1912.01218
Technical report о google keyboard и том как туда добавили 900 языков.
Кажется, большие компании начинают вспоминать, что в этом мире существуют другие языки, кроме английского.