The compositionality of neural networks: integrating symbolism and connectionism
Hupkes et al.
arxiv.org/abs/1908.08351
Больше статей про то, что нейронные сети могут больше, чем мы думаем. В этой тестируют могут ли сети в композициональность. Конкретно авторы проверяют:
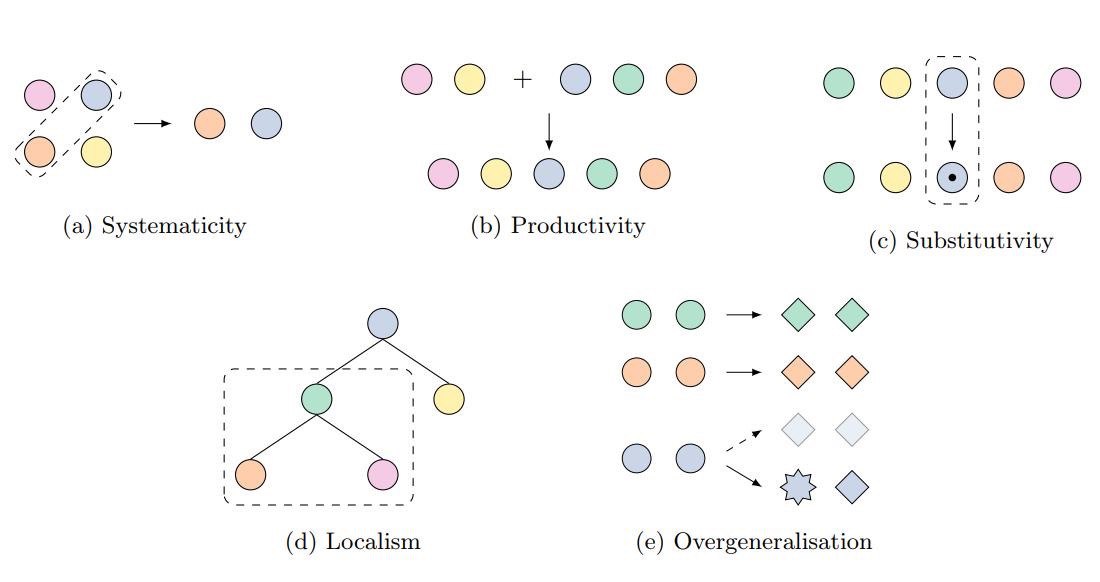
(i) ability to systematically recombine known parts and rules
(ii) ability to extend predictions beyond the length they have seen in the training data
(iii) if predictions are robust to synonym substitutions
(iv) composition operations are local or global
(v) network favour rules or exceptions during training
Спойлер: трансформер рвёт LSTM и CNN. Результаты намекают на то, что в общем сети скорее могут в композициональность, чем нет, что несколько противоречит нашим текущим представлениям о них.
Более подробное саммари от автора:
twitter.com/_dieuwke_/status/1164875248283656192