Recipes for building an open-domain chatbotСтатья |
Блогпост |
Опенсорс |
Коллаб пообщаться с модельюTL;DRФейсбук натренировал и зарелизил SOTA open-domain чатбот модель. Лучшая модель имеет 2.7В параметров, самая большая - 9.4B. По архитектуре - трансформер. На human evaluation модель от FB получилась сильно лучше прошлой SOTA модели -
Meena от гугла.
Выложили все - код, модель и датасеты для файнтюна. Показали по сути два способа увеличения качества ответов модели:
- файнтюн модели на качественном разнообразном диалоговом корпусе
- тщательно подобранный способ декодинга ответа.
Суть:Натренировали и сравнили друг с другом разные типы диалоговых моделей:
- retrieval-based. На вход контекст и датасет респонсов, на выходе нужно выдать топ релевантных респонсов из датасета. Использовали Poly-encoder модель, по сути усовершенствованный двубашенный трансформер-енкодер, где одна башня - енкодер контекста, вторая - енкодер респонса, на выходе - dot product, показывающий релевантность респонса для данного контекста.
- генеративные. На входе контекст, на выходе нужно сгенерировать респонс. Архтектура - encoder-decoder transformer, малослойный енкодер, многослойный декодер. Натренировали три базовые модели отличающиеся кол-вом параметров: 90M, 2.7B (ровно как в Meena), 9.4B.
- retrieve and refine - смесь двух подходов выше. Сначало получаем список кандидатов из retrieval-based модели, и подаем их в качестве подсказок в генеративную модель для генерации финального ответа.
Все базовые модели тренировали на огромной корпусе реддита. Финальный почищенный корпус имеет 1.5B диалоговых сообщений. Сколько учились и на каком железе не написали.
Для генеративных моделей перебирали разные способы как трейна, так и декодинга для улучшения качества ответов:
- добавление unlikelihood лосса. По сути в лосс добавляем штраф за порождение частотных нграмм, чтобы форсить разнообразие слов и коллокаций при генерации ответа.
- subsequence blocking. Выбрасываем респонсы у которых есть нграмное пересечение с контекстом, или же одна нграмма несколько раз встречается в самом ответе, т.e модель повторяет, то что уже сказала.
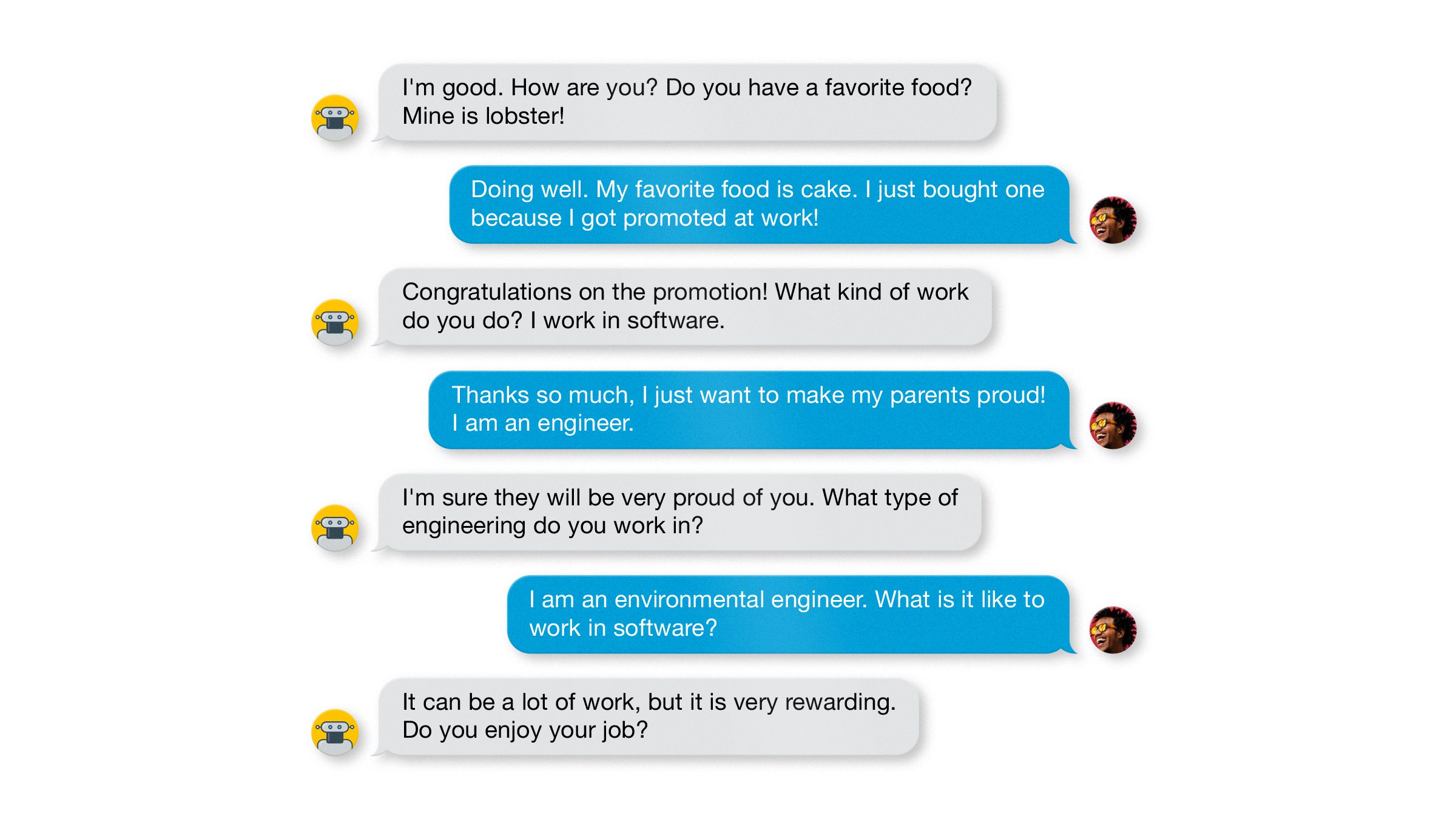
- файнтюн. Расмотрели 4 небольших диалоговых корпуса, от 50K до 200K сообщений в каждом: ConvAI2, Empathetic Dialogs, Wizard of Wikipedia и BST(Blended Skill Talk) - по сути объединение трех первых корпусов. Лучше всего файнтюн заработал на BST. Пример диалога из корпуса на скрине.
- декодинг. Пробовали beamsearch с разными beamsize, top-k сэмплирование, sample + rank как в Meena когда сначало сэмплим N ответов, а потом выбираем лучший по log-likelihood. В итоге лучшим оказался beamsearch (beam=10) c ограничением на длину, в котором они форсят генерировать ответ минимум в 20 токенов. Показали что таким образом увеличивается как качество ответов, так и engagingness - вовлеченность человека в беседу с чатботом.