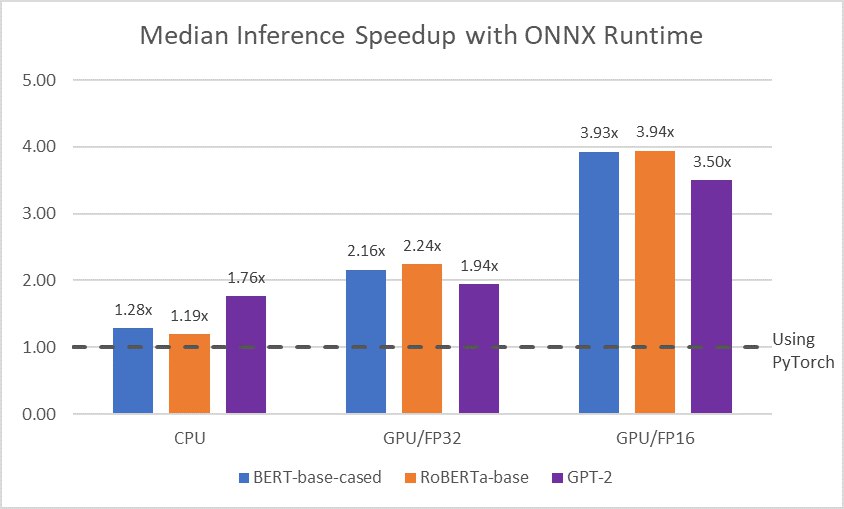
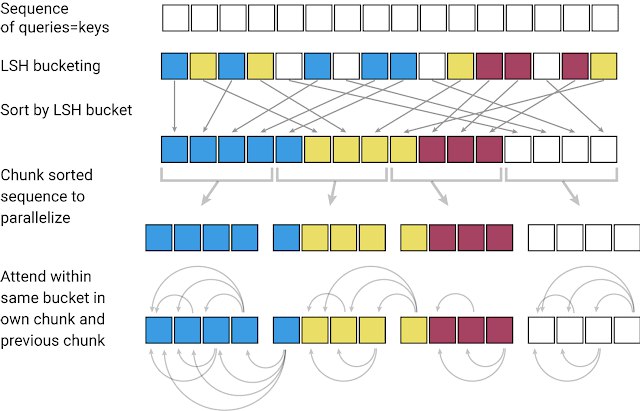
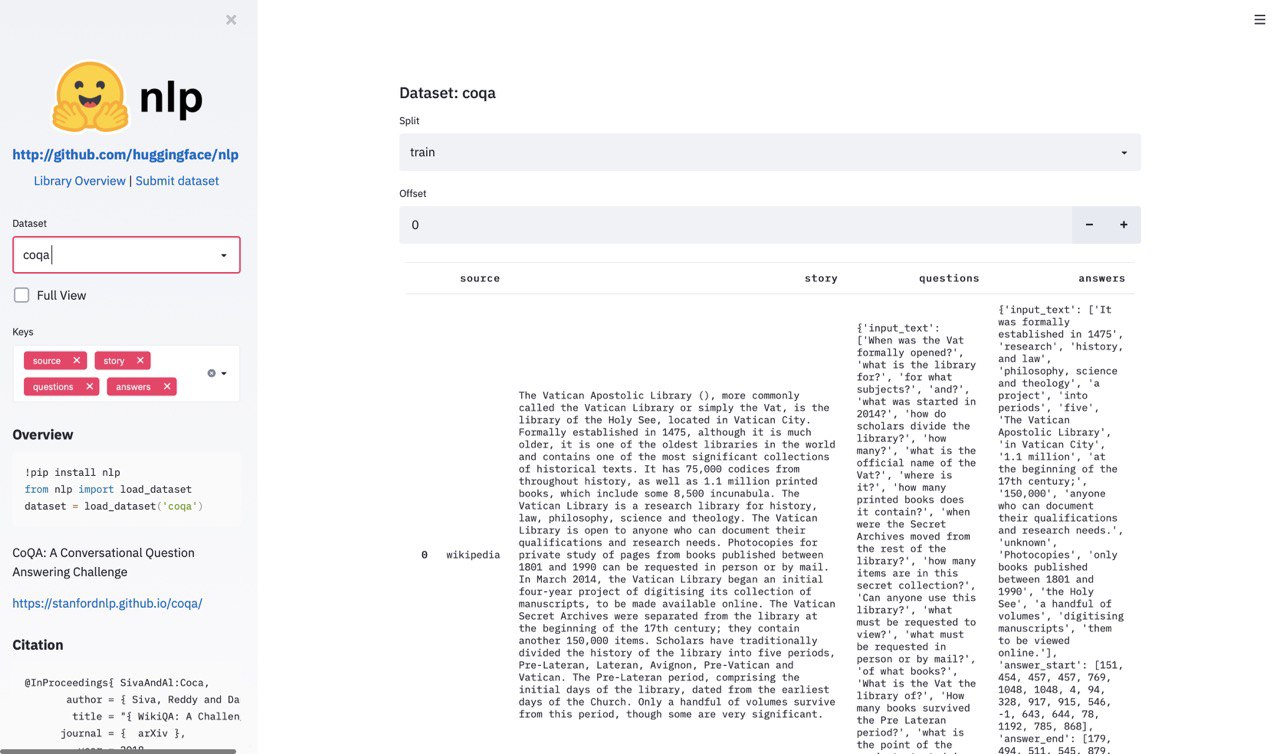
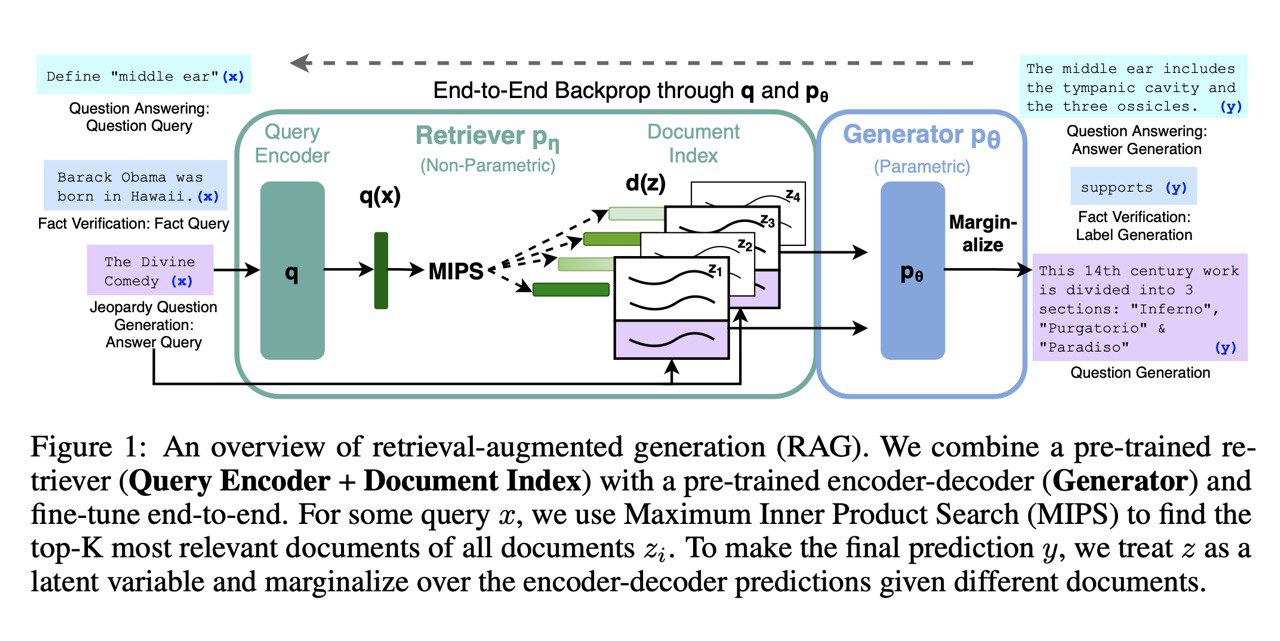
DeepMind постит у себя в твитере рекомендации от их рисёчеров на почитать
Из интересного нашёл:
1. d2l.ai - книга по DL с примерами кода на вообще всё. Вот главы про attention и transformer для примера (осторожно MXNet)
1. The Scientist in the Crib - научпоп книжка о том как люди (очень маленькие люди) учатся и чему это может научить нас
1. Лекция про bias на NIPS 2017
1. Ещё лекция: 21 definitions of fairness and their politics
1. Курс MIT Introduction to Deep Learning - на мой взгляд слишком поверхностный, но есть весёлые домашки
1. Внезапно, курс о том, как деплоить модельки - очень советую всем джунам да и не только смотреть в эту область более пристально. Это сложная тема.
Всё тут не опишу, лучше следите за DeepMind в твиттере и за хештегом #AtHomeWithAI.
Из интересного нашёл:
1. d2l.ai - книга по DL с примерами кода на вообще всё. Вот главы про attention и transformer для примера (осторожно MXNet)
1. The Scientist in the Crib - научпоп книжка о том как люди (очень маленькие люди) учатся и чему это может научить нас
1. Лекция про bias на NIPS 2017
1. Ещё лекция: 21 definitions of fairness and their politics
1. Курс MIT Introduction to Deep Learning - на мой взгляд слишком поверхностный, но есть весёлые домашки
1. Внезапно, курс о том, как деплоить модельки - очень советую всем джунам да и не только смотреть в эту область более пристально. Это сложная тема.
Всё тут не опишу, лучше следите за DeepMind в твиттере и за хештегом #AtHomeWithAI.