Новый релиз 🤗, теперь с лонгформером
https://github.com/huggingface/transformers/releases/tag/v2.11.0
https://github.com/huggingface/transformers/releases/tag/v2.11.0
Size: a a a
rearrange(input, "bs (n_gram n) hid -> (bs n_gram) n hid", n_gram=4) без модификаций в архитектуре.import fairseq это не тот fairseq, который можно получить по pip install, это папка fairseq в конкретно этом проекте, где изменены 3 файла. Какие именно? Смотри по коммитам. А fairseq весьма большой, так что удачи. И это становится ещё хуже - иногда так добавлен не один фреймфорк, а несколько. В результате зарелиженный код может быть и добавляет статье воспроизводимости, но reusability остаётся нулевой.--user-dir. В результате размер вашего репозитория уменьшается в сотни раз, позволяя проще модифицировать и переиспользовать ваш код.O(N^2) to O(N) in both time and space.n and stride k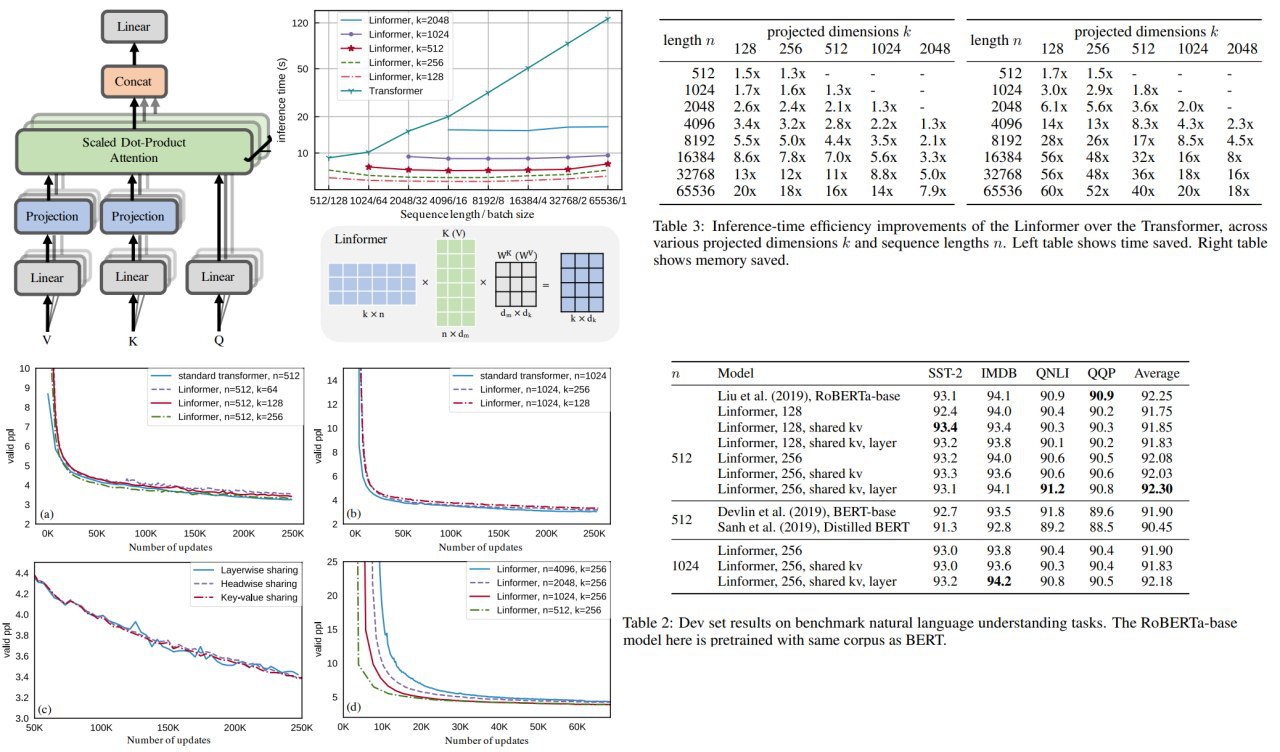
Вышел Russian SuperGLUE!
Лидерборд : http://russiansuperglue.com
Код: https://github.com/RussianNLP/RussianSuperGLUE
Чтобы правильно оценивать русскоязычные языковые модели, такие как популярные сейчас BERT, RoBERTa, XLNet и т.д., нужно иметь какие-то объективные метрики. Подходов, как это делать, не так много, а для русского языка их не было. Представлен Russian SuperGLUE - бенчмарк для задачи общего понимания языка (General Language Understanding) и дальнейшего развития моделей на русском.
Набор новых задач для оценки моделей:
1. LiDiRus (Linguistic Diagnostic for Russian) или просто общая диагностика — её мы полностью адаптировали с английского варианта.
2. DaNetQA — набор вопросов на здравый смысл и знание, с да-нет ответом.
3. RCB (Russian Commitment Bank) — классификация наличия причинно-следственных связей между текстом и гипотезой из него.
4. PARus (Plausible Alternatives for Russian) — целеполагание, выбор из альтернативных вариантов на основе здравого смысла.
5. MuSeRC (Multi-Sentence Reading Comprehension) — машинное чтение. Задания содержат текст и вопрос к нему, но такой, на который можно ответить, сделав вывод из текста.
6. RuCoS (Russian reading comprehension with Commonsense) — тоже задача на машинное чтение. Модели даётся новостной текст, а также его краткое содержание с пропуском — пропуск нужно восстановить, выбрав из вариантов.
7. TERRa (Textual Entailment Recognition for Russian) — классификация причинно-следственных связей между предложениями (собрали с нуля по новостям и худлиту).
8. RUSSE (Russian Semantic Evaluation) — задача распознавания смысла слова в контексте (word sense disambiguation). Взят из RUSSE
9. RWSD (Russian Winograd Schema Dataset) — задания на логику, с добавленными неоднозначностями («Если бы у Ивана был осёл, он бы его бил»). Создан по аналогии с Winograd Schema.
Разработчики и энтузиасты приглашаются представить свои модели на лидерборде!
Пост на habr https://habr.com/ru/company/sberbank/blog/506058/