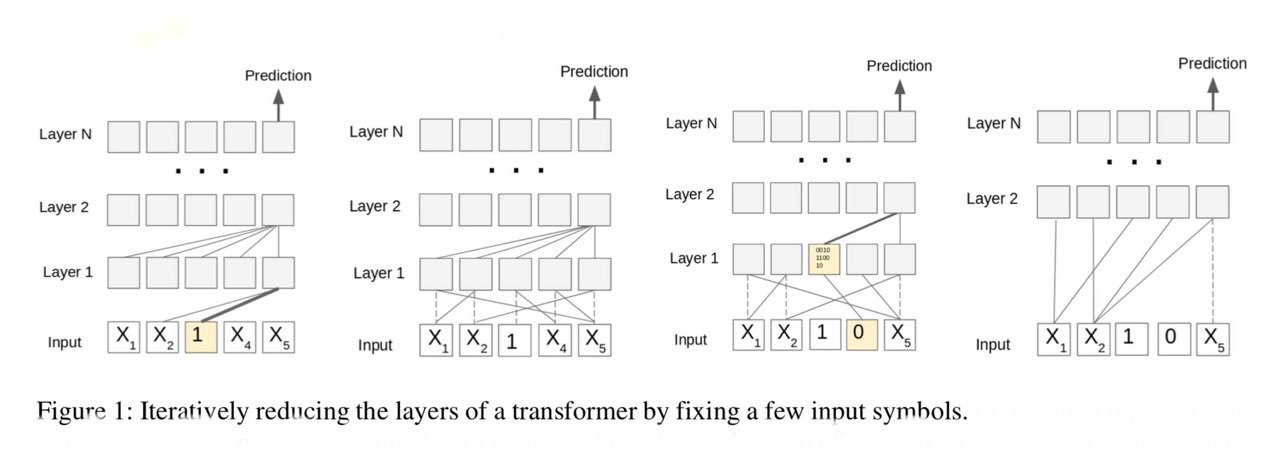
Тут в Стенфорде выяснили, что self-attention не классный. Точнее, доказали что при фиксированном числе слоёв (как мы его обычно и используем) он не может в простые формальные языки. Например, в детекцию четное или нечётное число какого-то токена есть у него на входе или в проверку валидности скобок.
От авторов:
These limitations seem surprising given the practical success of self-attention and the prominent role assigned to hierarchical structure in linguistics, suggesting that natural language can be approximated well with models that are too weak for the formal languages typically assumed in theoretical linguistics.
От себя хочу добавить, что вижу всё больше расхождений интуитивных представлений из лингвистики и реального мира. Так что не бойтесь пробовать ваши идеи даже если они не кажутся лингвистически корректными.