Residual Energy-Based Models for Text Generation
Deng et al. [FAIR]
arxiv.org/abs/2004.11714
Новая интересная статья по генерации текста. Авторы предлагают вместо стандартного авторегрессионного моделирования перейти к моделированию ненормализованной вероятности (энергии) целого предложения.
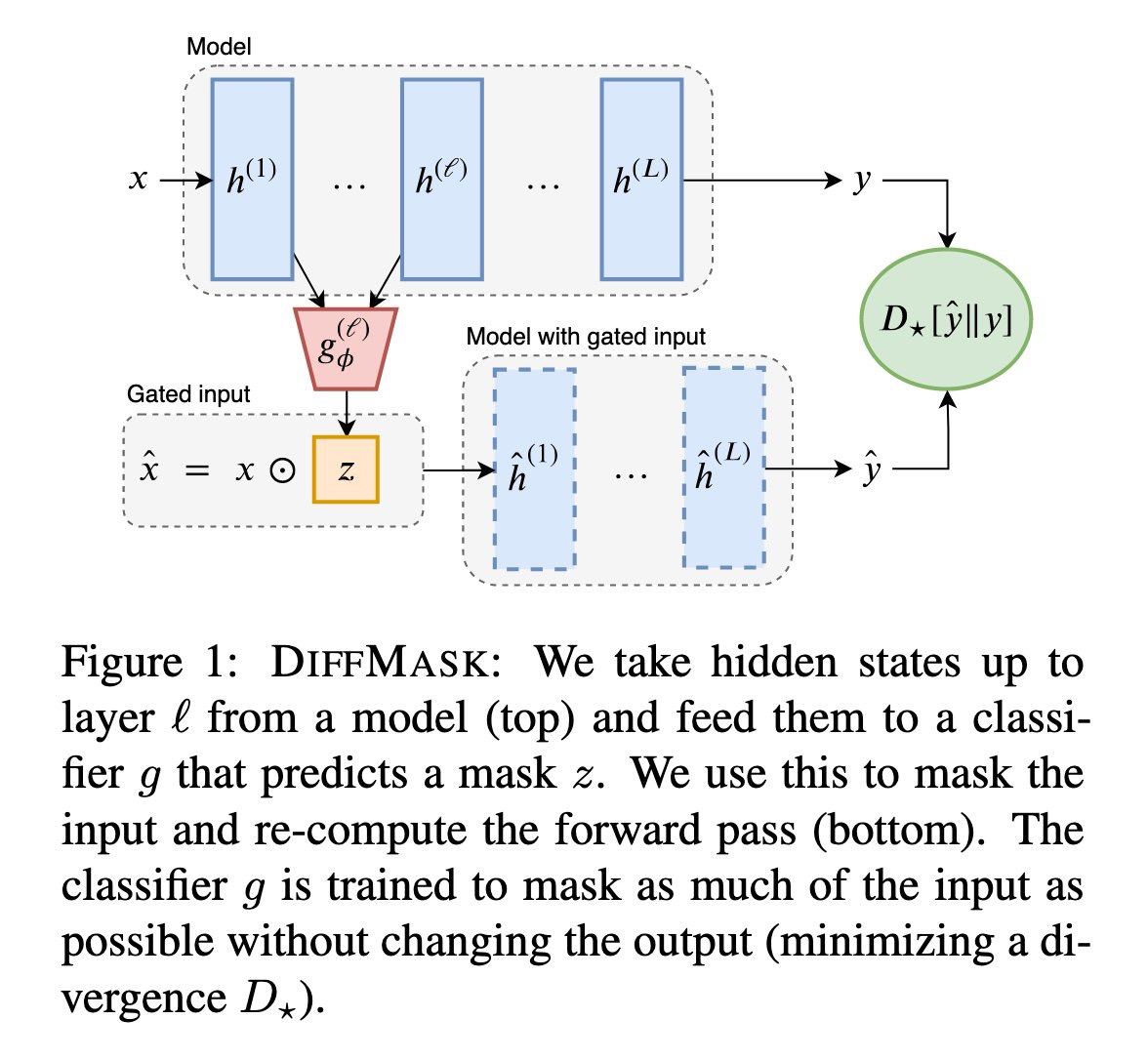
Но напрямую это сделать нельзя, тк непонятно, как геренировать примеры плохих последовательностей. Поэтому они параметризуют модель как
То есть E(x) обучается как дискриминатор учащийся различать между реальными текстами и текстами, сгенерированными LM. По сути мы получили GAN, описаный в терминах energy-based models (EBM).
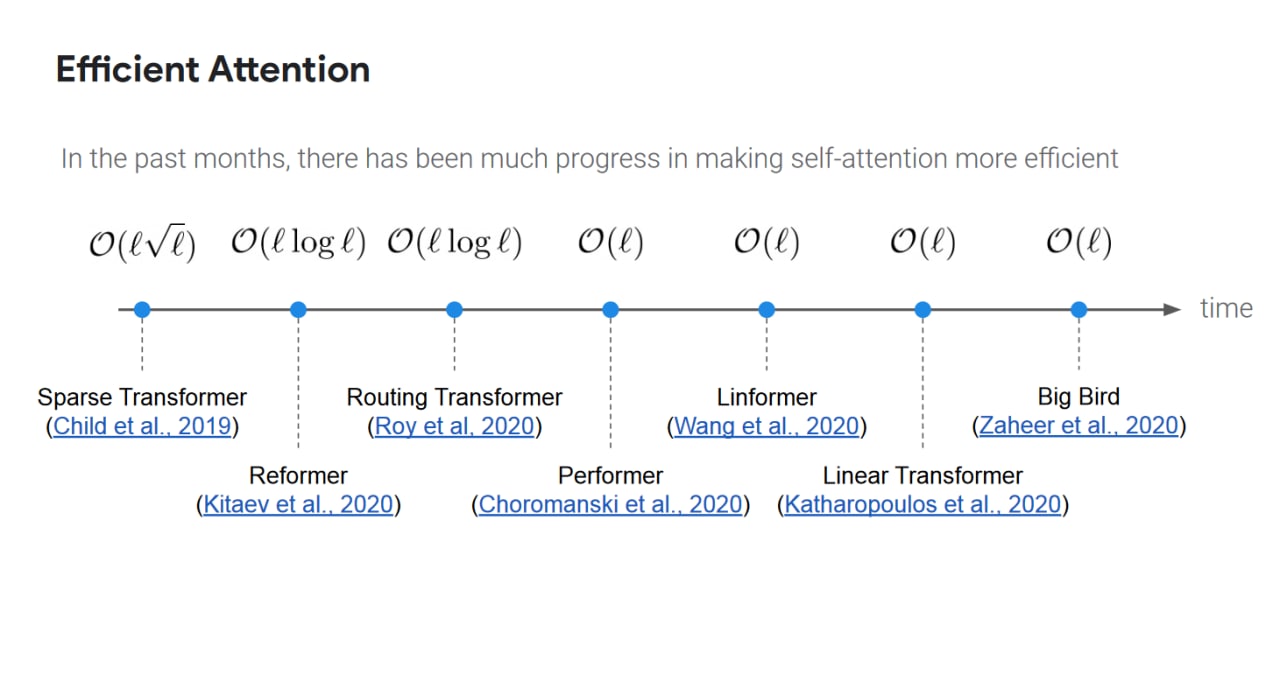
Как всегда, у GAN есть проблема семплирования - как геренировать текст с помощью обученной модели. Для этого авторы (используя немного матана) показывают, что сэмплирование текста длины K из этой EBM эквивалентно тому, если мы 1) сгеренируем несколько текстов длины K из языковой модели; 2) используя получишиеся семплы, оценим матожидание энергии E всей последовательности (там чуть сложнее, но идея такая); 3) используя нашу оценку энергии мы получим "подкорректированное" функцией энергии вероятностное распределение следующего слова и теперь будем семплировать из этих вероятностей. Причём по-идее эта коррекция (тк она смотрит планирует будущее на K-1 токен больше) должна улучшить языковую модель, которая только думает про следующее слово.
В качестве LM использовался обученный трансформер. В качестве дискриминатора использовался BERT (предобученный с нуля, на том же датасете, что и LM, чтобы не было читерства).
Последний момент состоит в том, что оценивать перплексию у такой модели напрямую нельзя, тк мы моделируем ненормализованные вероятности. Авторы придумали метод, который позволяет оценить её с помощью того, что мы геренируем очень много достаточно длинных текстов и вычисляем вероятности для подсчёта перплексии из статистик сгеренированных текстов.
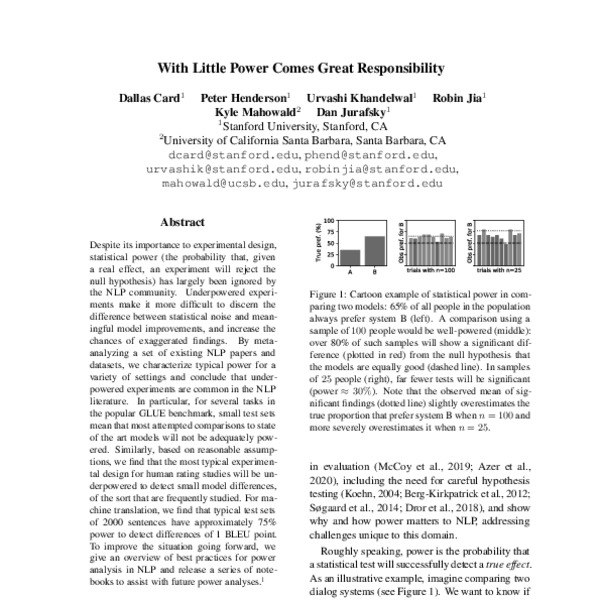
Результаты:
1. чуть лучше перплексия, чем у языковой модели такого же размера как LM + BERT
1. человеческая оценка качества текстов сгеренированных новой моделью тоже выше, чем у всех бейзлайнов
1. чуть более разнообразные n-gram чем у языковых моделей, но ещё далеко до человека
Deng et al. [FAIR]
arxiv.org/abs/2004.11714
Новая интересная статья по генерации текста. Авторы предлагают вместо стандартного авторегрессионного моделирования перейти к моделированию ненормализованной вероятности (энергии) целого предложения.
Но напрямую это сделать нельзя, тк непонятно, как геренировать примеры плохих последовательностей. Поэтому они параметризуют модель как
p(x) = LM(x) * exp(-E(x)), где LM - обычная (обученная) авторегрессионная языковая модель, оценивающая вероятность следующего слова, а E(x) - функция энергии, оценивающая всю последовательность. И качестве "плохих" последовательностей во время обучения E берут то, что геренирует LM.То есть E(x) обучается как дискриминатор учащийся различать между реальными текстами и текстами, сгенерированными LM. По сути мы получили GAN, описаный в терминах energy-based models (EBM).
Как всегда, у GAN есть проблема семплирования - как геренировать текст с помощью обученной модели. Для этого авторы (используя немного матана) показывают, что сэмплирование текста длины K из этой EBM эквивалентно тому, если мы 1) сгеренируем несколько текстов длины K из языковой модели; 2) используя получишиеся семплы, оценим матожидание энергии E всей последовательности (там чуть сложнее, но идея такая); 3) используя нашу оценку энергии мы получим "подкорректированное" функцией энергии вероятностное распределение следующего слова и теперь будем семплировать из этих вероятностей. Причём по-идее эта коррекция (тк она смотрит планирует будущее на K-1 токен больше) должна улучшить языковую модель, которая только думает про следующее слово.
В качестве LM использовался обученный трансформер. В качестве дискриминатора использовался BERT (предобученный с нуля, на том же датасете, что и LM, чтобы не было читерства).
Последний момент состоит в том, что оценивать перплексию у такой модели напрямую нельзя, тк мы моделируем ненормализованные вероятности. Авторы придумали метод, который позволяет оценить её с помощью того, что мы геренируем очень много достаточно длинных текстов и вычисляем вероятности для подсчёта перплексии из статистик сгеренированных текстов.
Результаты:
1. чуть лучше перплексия, чем у языковой модели такого же размера как LM + BERT
1. человеческая оценка качества текстов сгеренированных новой моделью тоже выше, чем у всех бейзлайнов
1. чуть более разнообразные n-gram чем у языковых моделей, но ещё далеко до человека