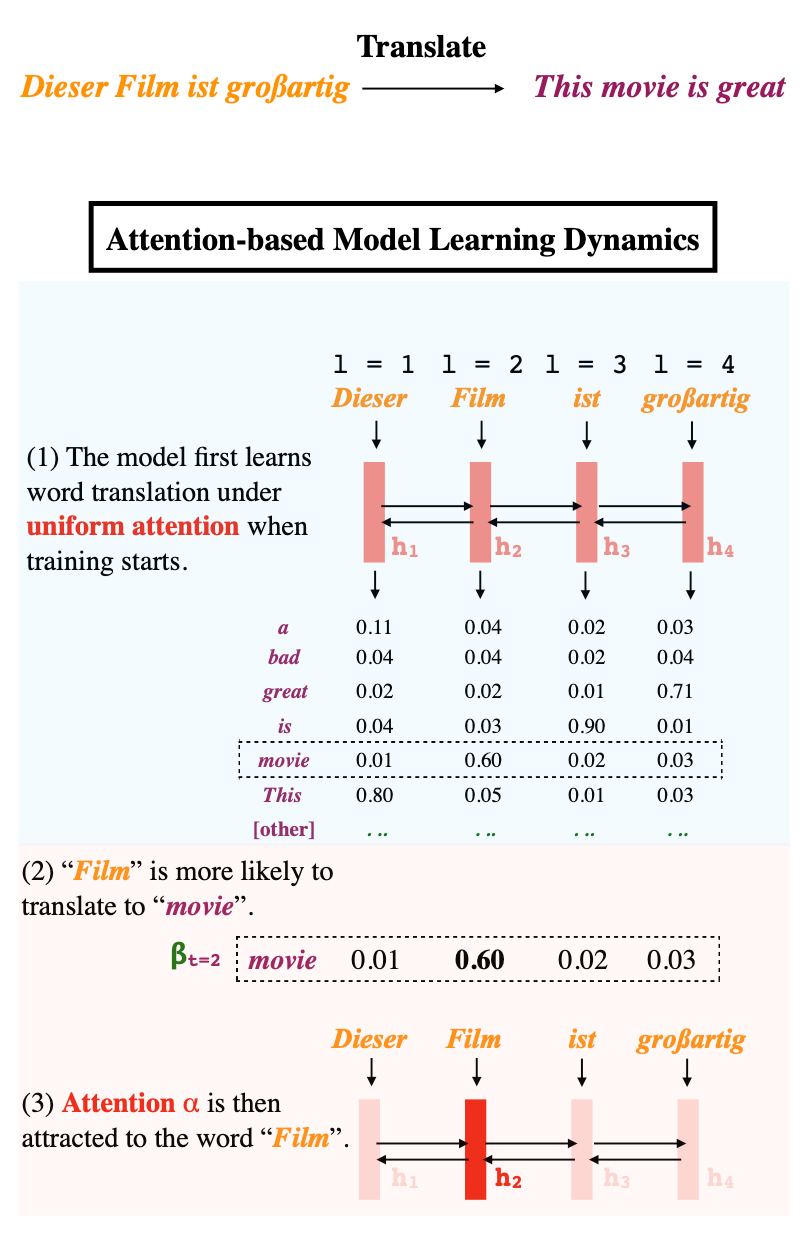
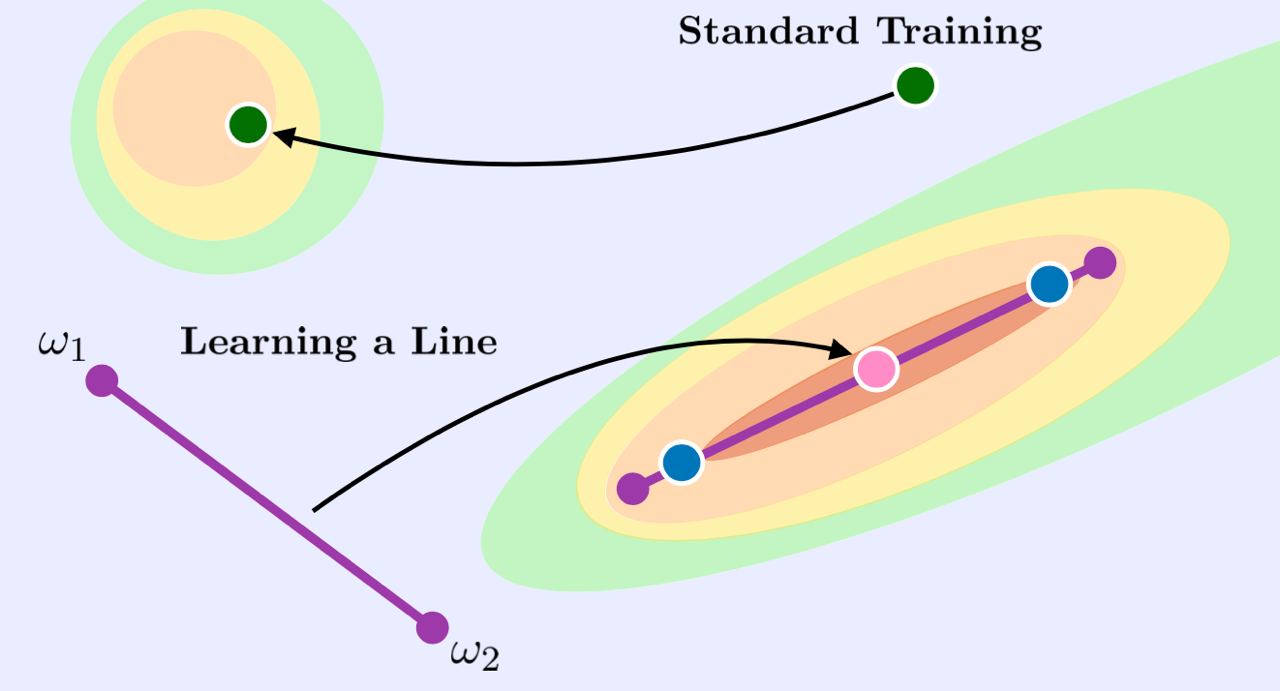
Learning Neural Network SubspacesWortsman et al. [Apple]
arxiv.org/abs/2102.10472Как мы обычно тренируем сетки – выучиваем параметры W. Но вообще говоря в пространстве параметров нейросети очень много подходящих нам W. Есть уже довольно много работ, которые показывают, что различные подходящие нам W связаны друг с другом (обычно, непрямыми) линиями, на проятжени которых наша тестовая accuracy остаётся высокой. В этой статье предлагают вместо выучивания одного W, выучивать целый симплекс. Зачем это надо? Во-первых это интересно. Но есть и практическая польза, о ней ниже.
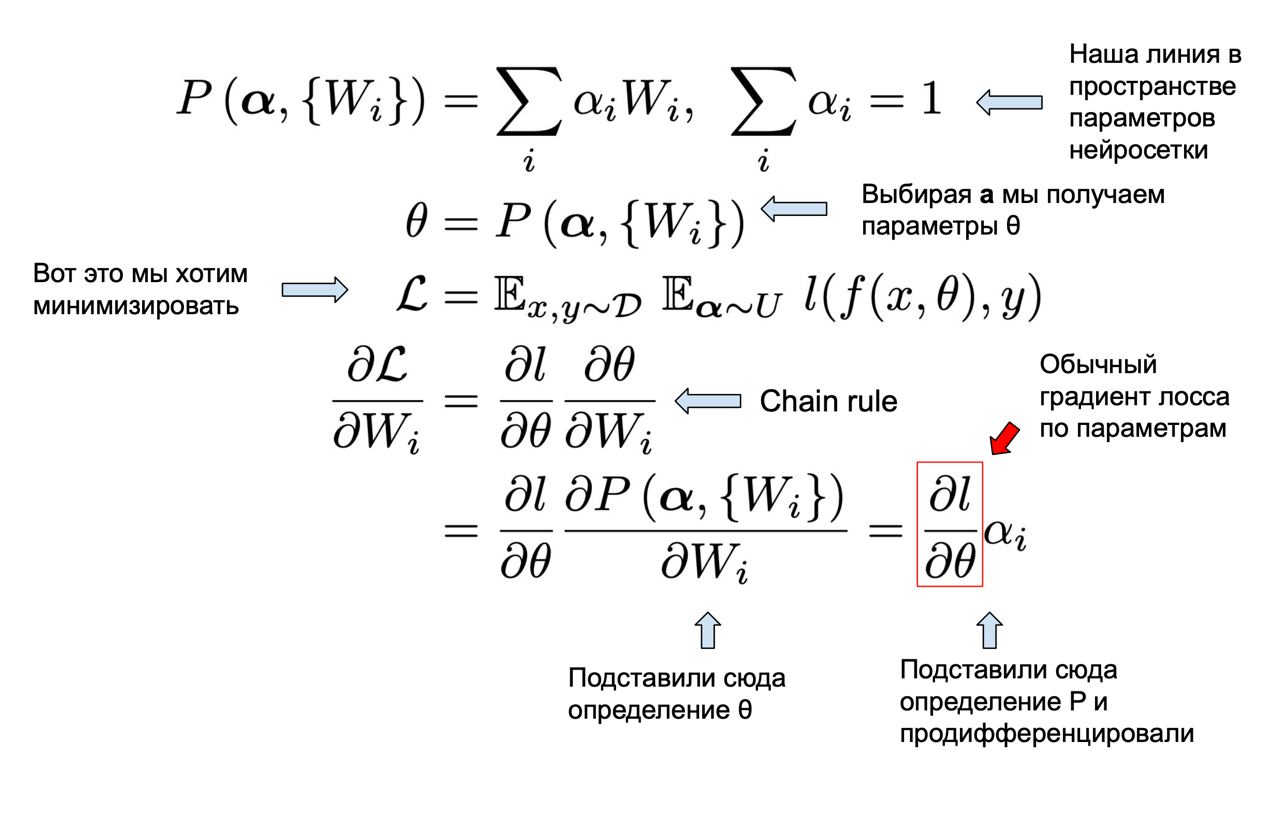
Сам алгоритм выучивания симплекса очень простой. У нас есть параметризованая линия P(
a) в пространстве наших весов нейросети. Например, в случае симплекса P(
a) = sum(a_i * W_i), где sum(a_i) = 1. Мы хотим подобрать N такие сетов параметров нейросети W_i (вершин симплекса), что на всей линии P(
a) у нас будет низкий лосс. Звучит сложно, а решение очень классное. Мы просто применяем chain rule и он выдаёт нам обыкновенный градиент лосса по параметром нейросети (тот же, что вам выдаёт loss.backward() в торче) взвешенный на параметры линии
a. Обучаем мы N вершин нашего симплекса W_i в одном и том же тренировочном цикле просто семплируя различные
a из равномерного распределения.
На выходе получается симплекс, в котором каждая точка должна давать достаточно высокий тренировочную (а на практике и тестовую) accuracy. Как это можно использовать? Взять центральную точку этого симплекса в качестве параметров нейросети. В статье эта точка зачастую обходит по тестовой accuracy и обычные методы тренировки и stochastic weight averaging. Ещё при тренировке в лосс добавляют регяляризатор, максимизирующий квадрат косинусного расстояния между различными W_i, это позволяет немножко улучшить результат.