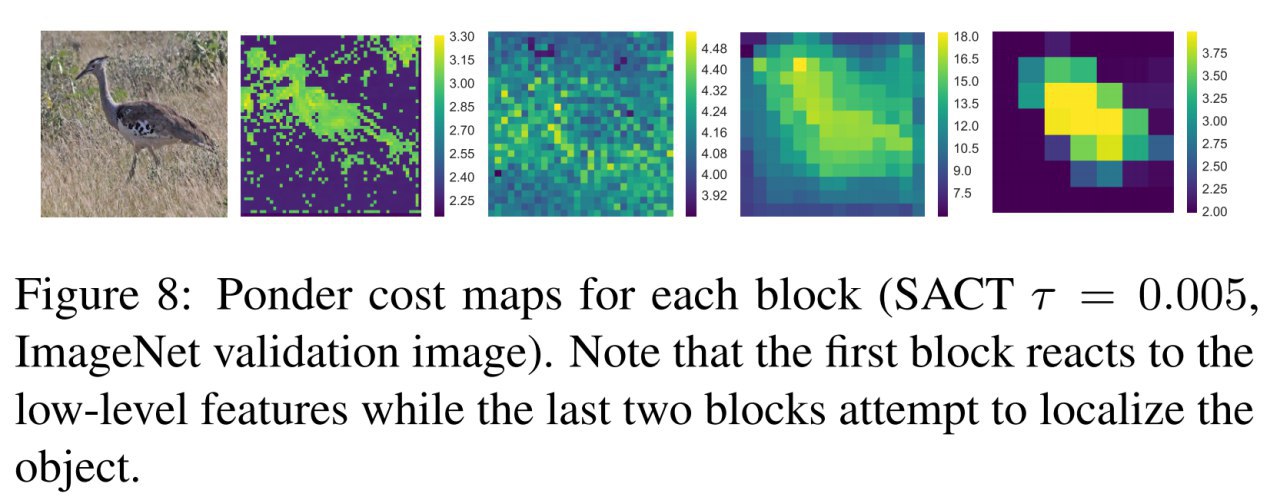
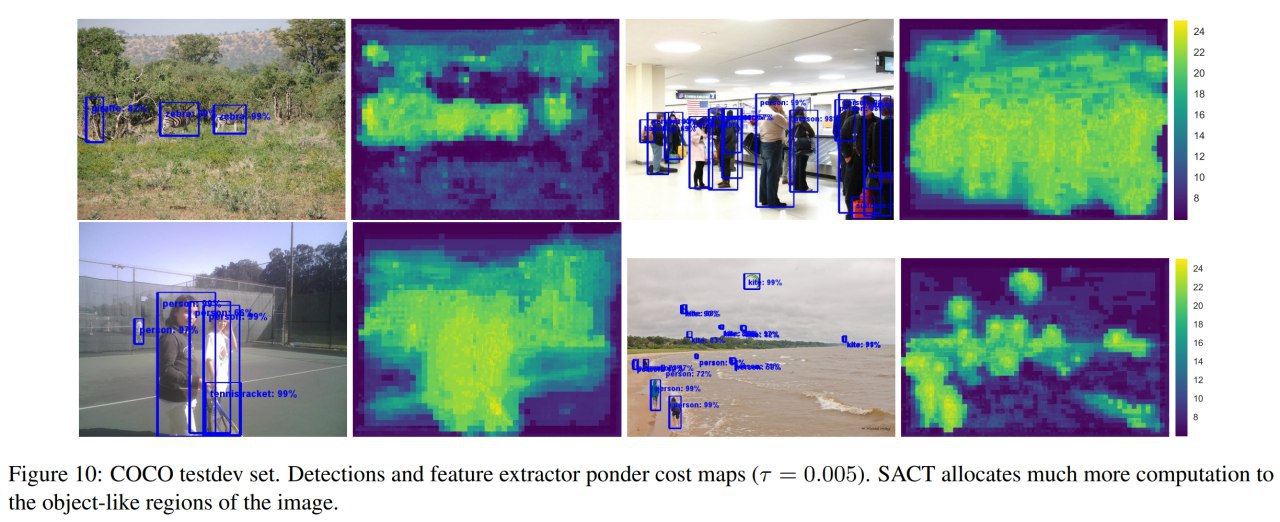
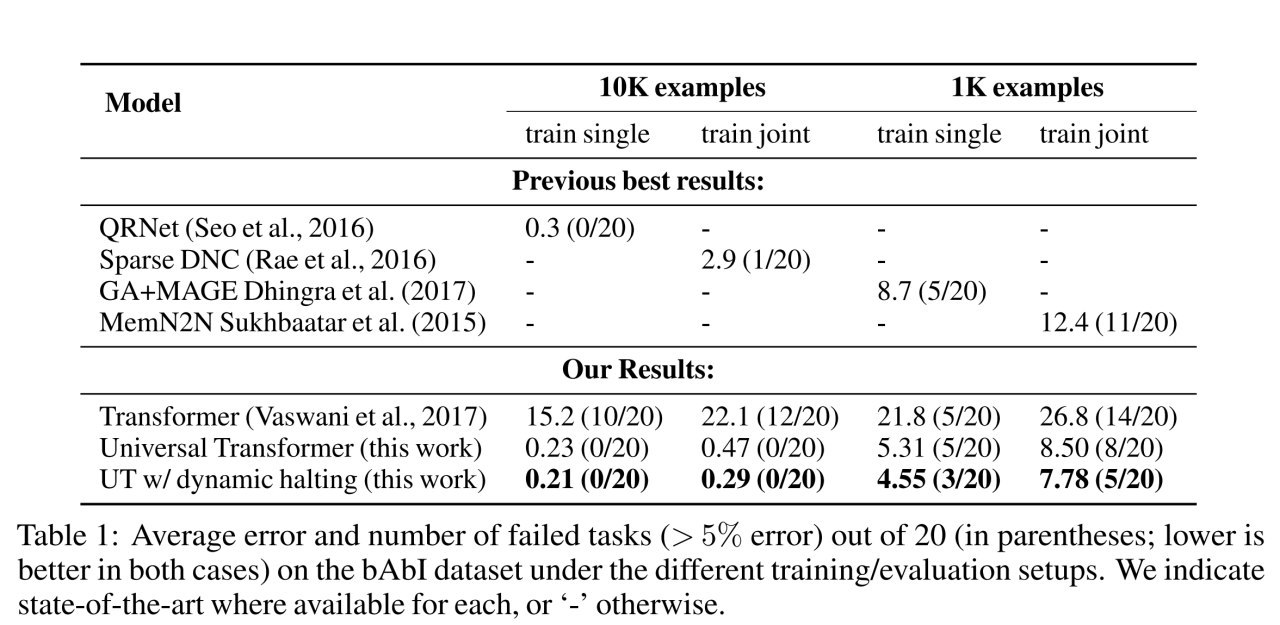
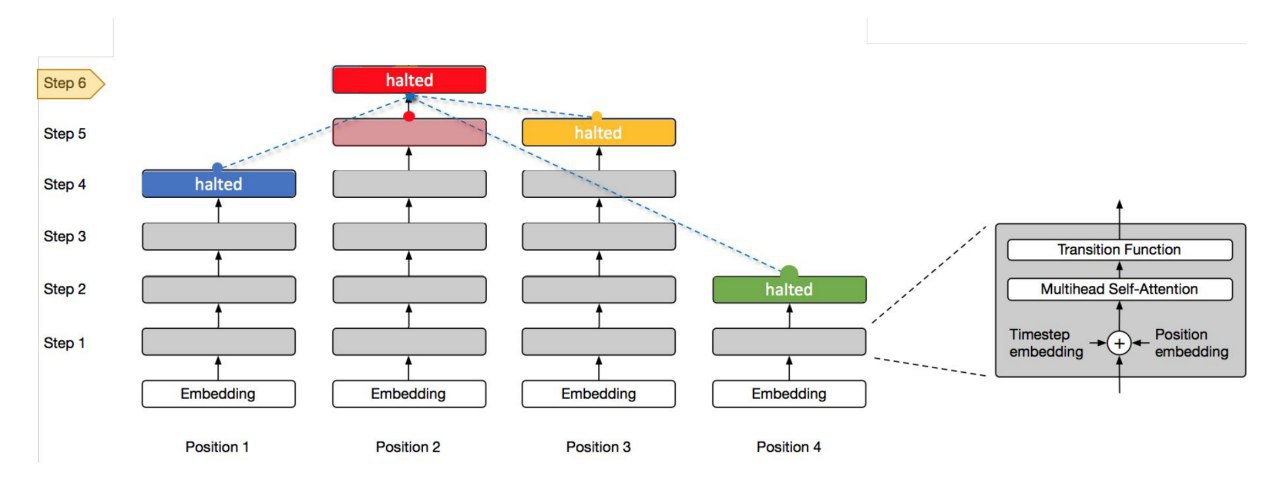
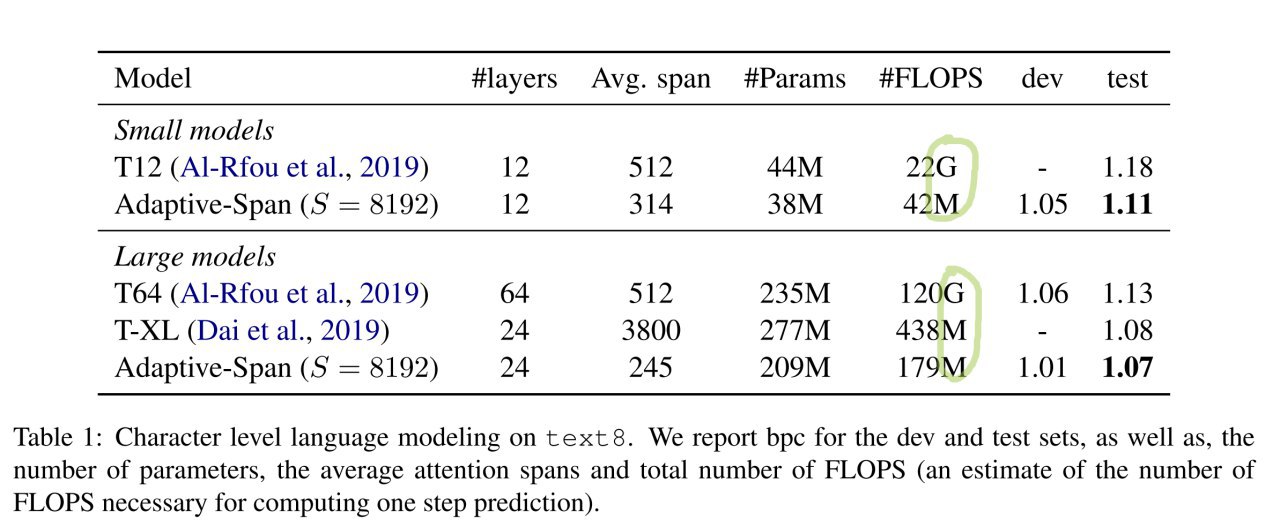
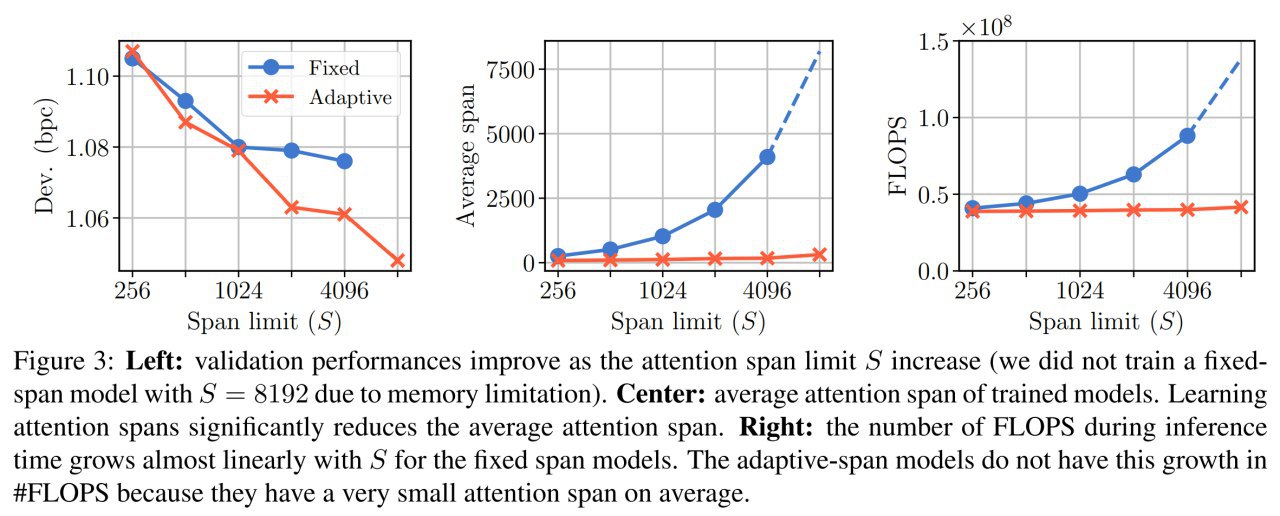
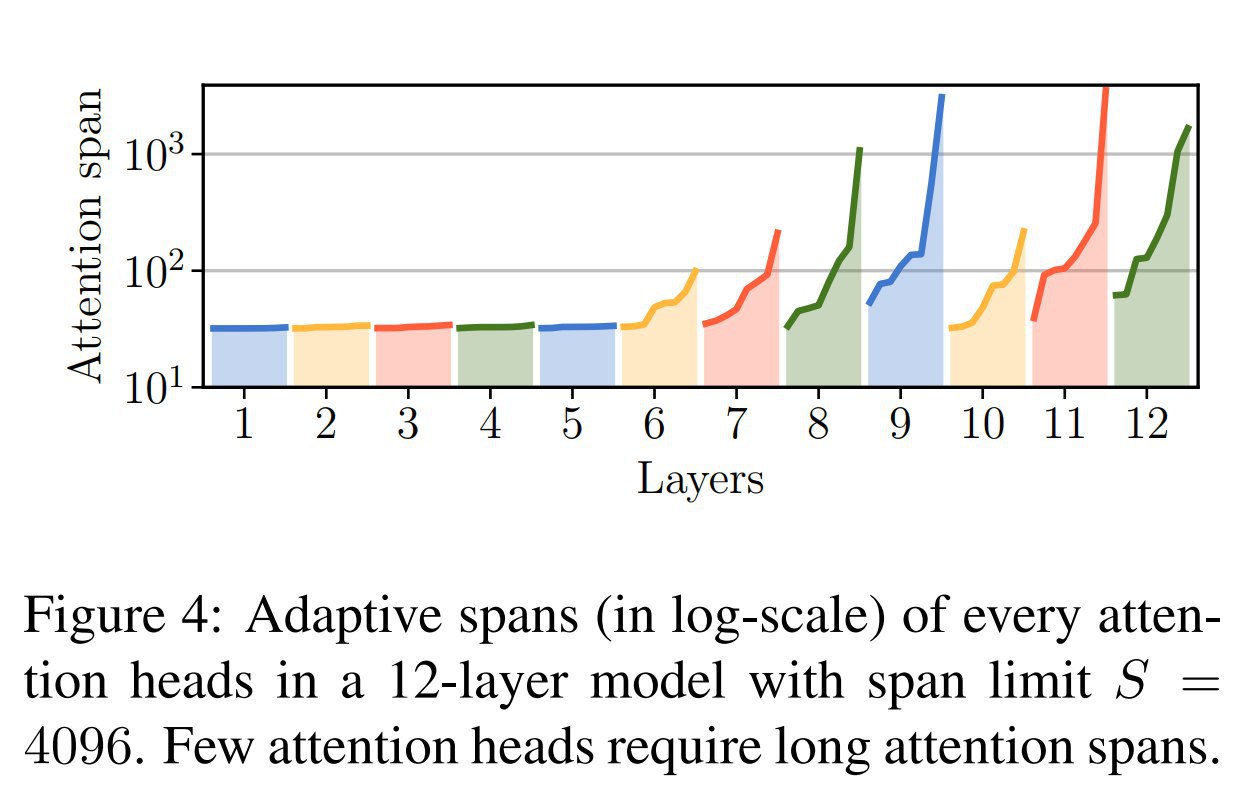
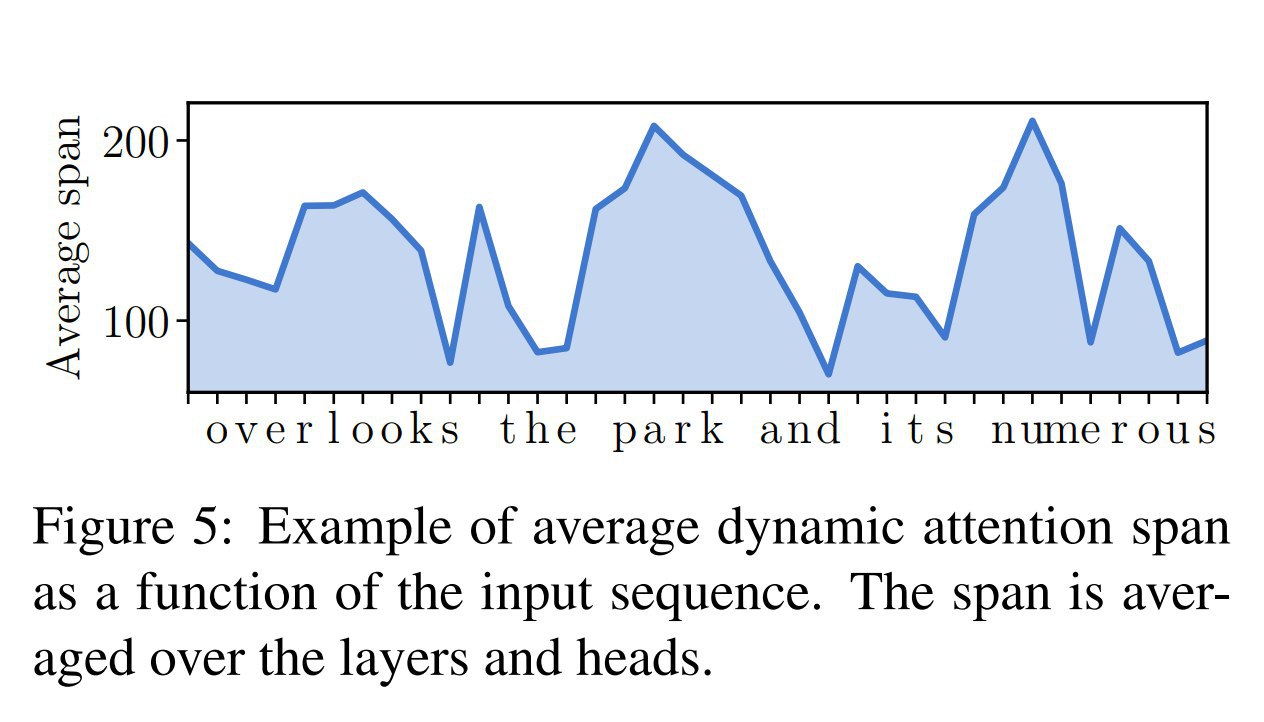
Продолжение про ACT, часть 4-я.
#3: Universal TransformerНаконец про трансформеры. Лёша про них уже недавно писал, но теперь более детально.
Universal TransformersMostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, Łukasz KaiserСтатья:
https://arxiv.org/abs/1807.03819 Презентация:
http://mostafadehghani.com/wp-content/uploads/2018/08/Universal_Transformers.pdf Код:
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/research/universal_transformer.pyНекоторые другие реализации:
https://github.com/topics/universal-transformerРабота выставлялась постером на ICLR 2019, но известна уже более полугода.
По сути делаем трансформер с рекуррентностью и динамическим критерием останова. А заодно вроде как получаем Turing completeness (теоретическую способность вычислить всё вычислимое — сэмулировать машину Тьюринга).
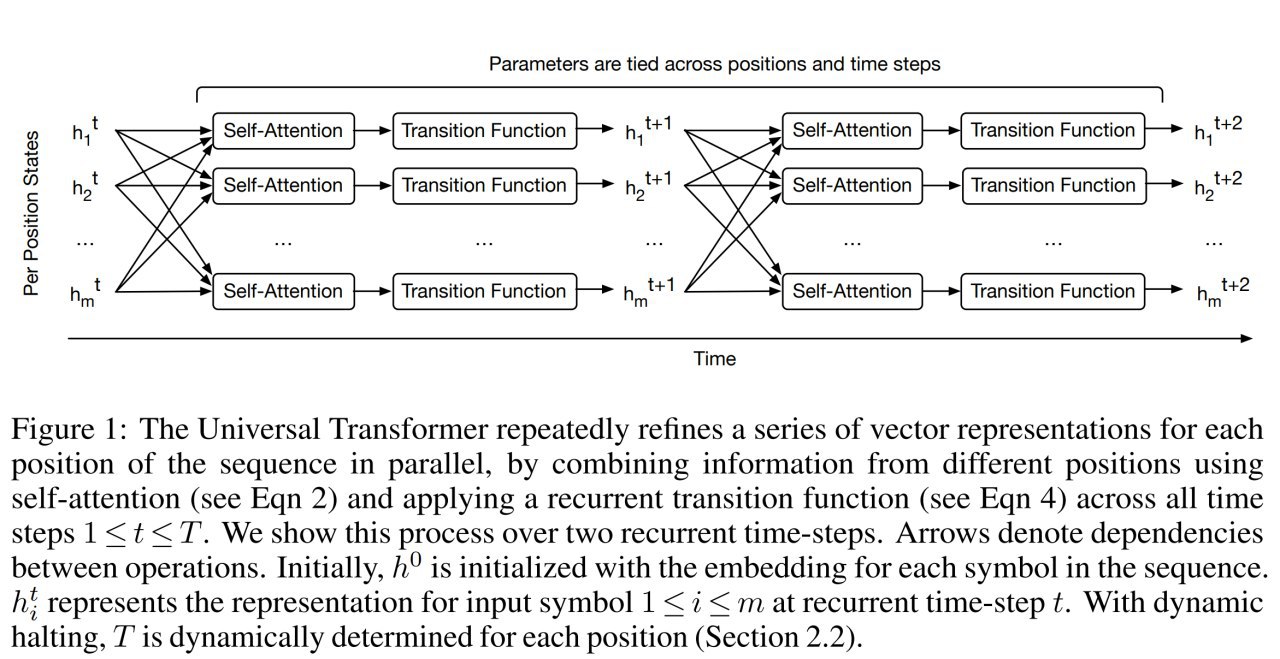
Рекуррентность здесь такого же рода как рекуррентность добавляемая ACT, то есть не рекуррентность над последовательностью символов, а рекуррентность над репрезентациями каждого конкретного символа — итеративно улучшаем представления (фичи) входной последовательности. По идее получаем как бы более глубокий трансформер с шарингом весов (что эффективно).
Добавление рекуррентного inductive bias должно быть полезным в задачах, где такой bias естественнен (некоторые алгоритмические и языковые задачи).
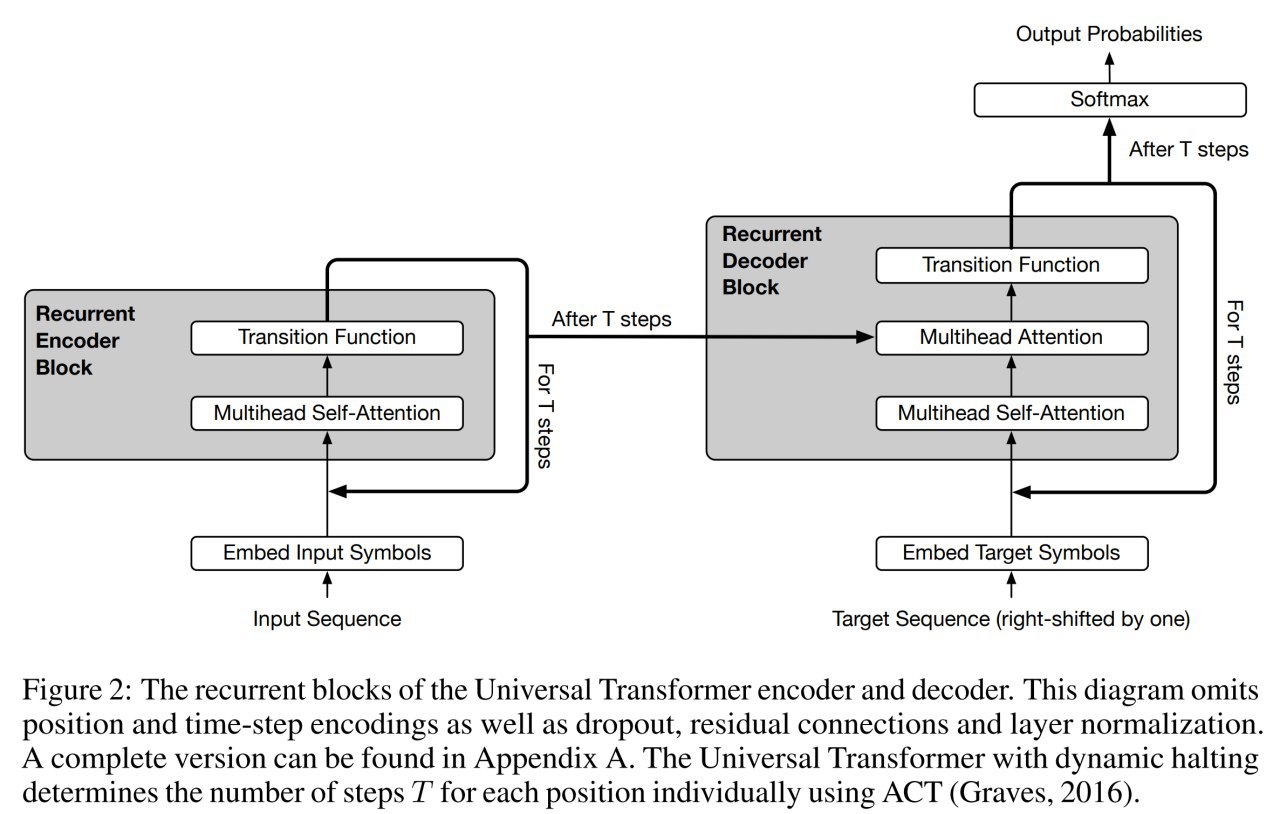
На каждом рекуррентном шаге выполняются две операции: 1) self-attention по входной для этого слоя последовательности, 2) transition function поверх выходов self-attention’а, независимо в каждой позиции. В работе применяли две различные transition function в зависимости от задачи: separable convolution или полносвязную сеть с relu.
Это Universal Transformer.
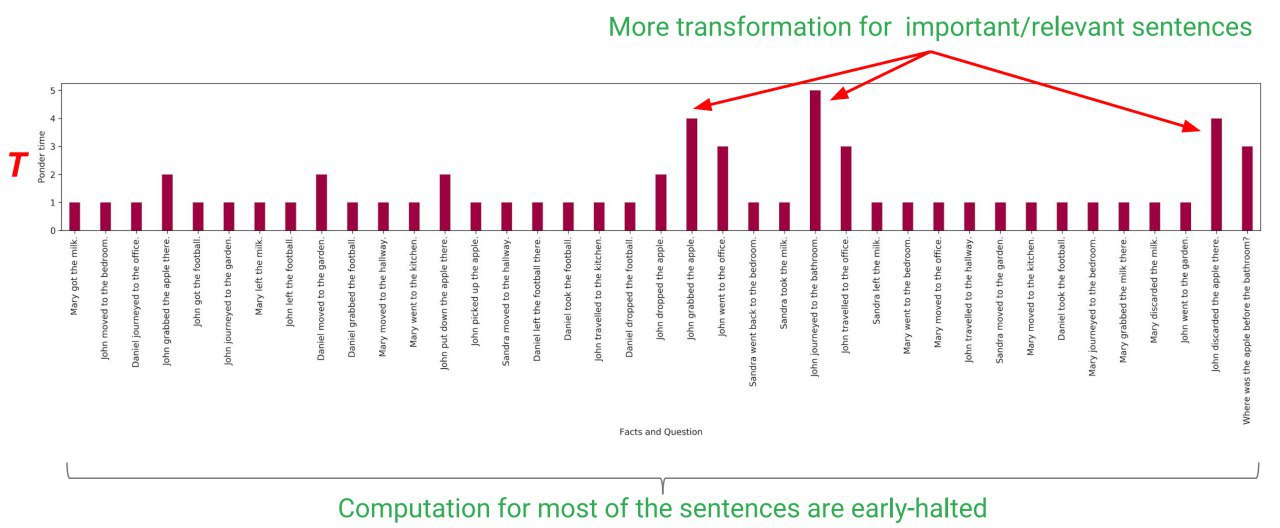
А чтобы было совсем интересно для определения глубины этой рекуррентности добавим ACT, то есть адаптивное определение этой глубины. Применяется точно так же, как и в предыдущих кейсах с ACT.
Это Adaptive Universal Transformer.
Далее применяют полученный универсальный трансформер (а иногда и адаптивный) к разным задачам, на которых обычных трансформер работает плохо.
На bAbi QA dataset результат хороший. На subject-verb agreement обычный трансформер работает хуже LSTM, а адаптивный универсальный дотягивает до SOTA. На LAMBADA бьёт и обычный трансформер и LSTM. На алгоритмических задачах не дотягивает до Neural GPU (который обучался по специальному протоколу), но бьёт LSTM и обычный трансформер. На Learning to Execute тоже бьёт эту парочку. На машинном переводе в WMT 2014 en-de тоже бьёт обычные и weighted трансформеры.
В общем явно хорошая штука.
Среди преимуществ авторы отмечают эффективность по данным — работает на маленьких датасетах.
Авторы сводят Universal Transformer к Neural GPU (который Turing complete) и соответственно доказывают, что UT тоже Turing complete. Для тех, кто этой темой ранее не интересовался, про RNN также существует доказательство, что они Turing complete. Но про это как-нибудь отдельно, если будет интересно. Также на ICLR 2019 была другая интересная работа про универсальность обычных трансформеров и Neural GPU, но про неё тоже как-нибудь отдельно.