#Transformers #NLP #seq2seq #LM
Обнаружил, что за последний год развелось куча всяких модификаций трансформера, про которые я толком не знаю. В том числе -- Universal Transformer/Sparsed Transformer/Transformer-XL. Решил для себя разобраться, что там интересного произошло, делюсь заметками, которые по итогам получились.
1. Коротко про Transformer.
В целом, про него уже столько написано, что проще дать ссылок.
Оригинальная статья:
https://arxiv.org/abs/1706.03762Оригинальный код:
https://github.com/tensorflow/tensor2tensorХороший разбор архитектуры:
http://jalammar.github.io/illustrated-transformer/Хороший разбор торчовой реализации:
http://nlp.seas.harvard.edu/2018/04/03/attention.htmlНо если коротко, то идея такая. Есть стандартная задача seq2seq, например, NMT. Известно, что RNN в целом имеют ограничения по применимости -- забывают контекст, тяжело и долго учатся и т.п.. Товарищи из Гугла в 2017 году придумали топологию, основаную только на FFNN и внимании, которая частично лишена этих недостатков.
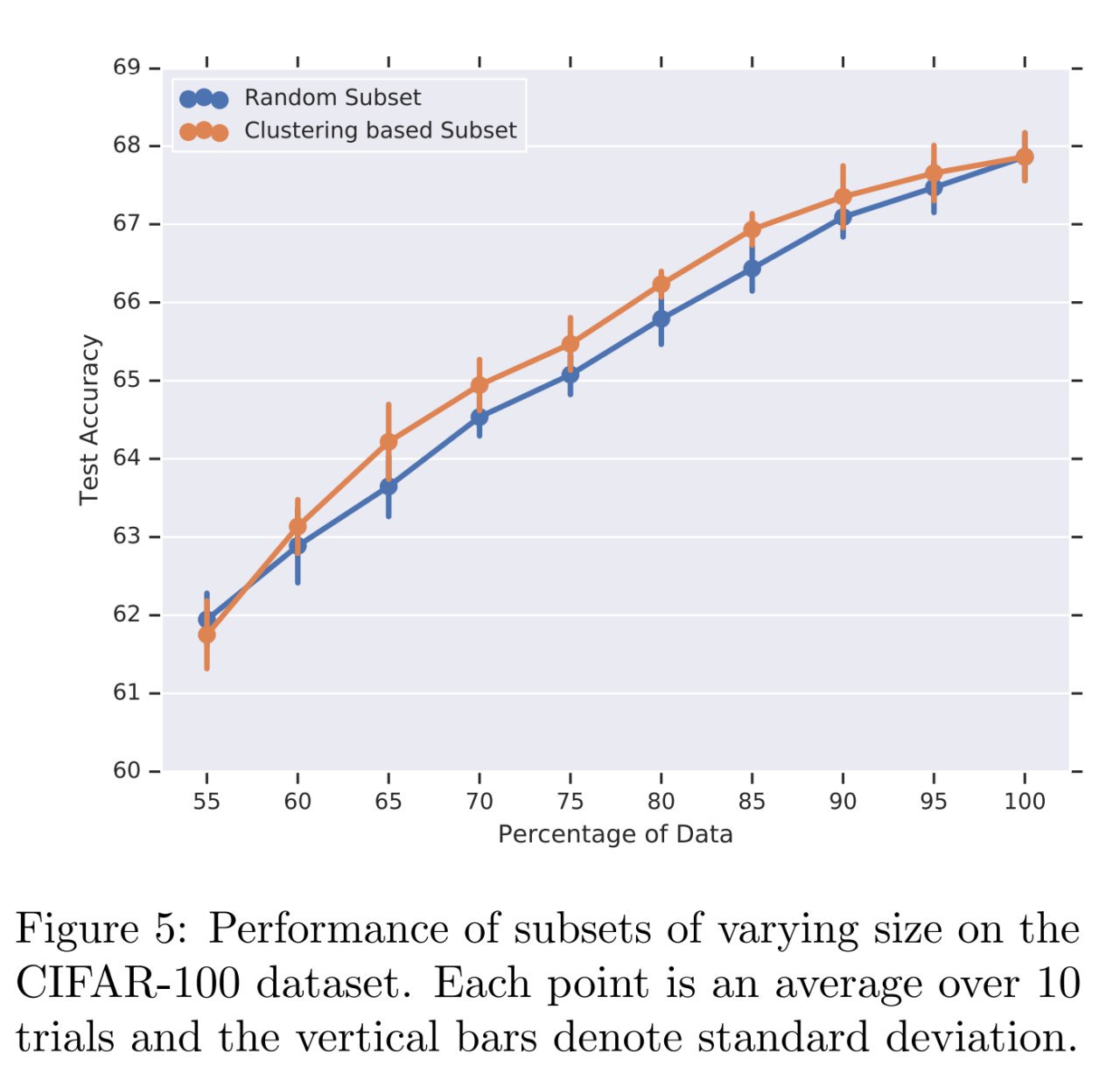
Как устроен Трансформер: кодирующая часть состоит из стека энкодер-слоёв (топологически одинаковых, но с разными весами). Финальный стейт верхнего слоя энкодера отдаётся в декодирующую часть. Она, аналогично, есть стек декодерных слоёв. Один энкодерный слой устроен так:
* входом является набор эмбеддингов (у нижнего слоя это эмбеддинги слов, у следующих -- выход предыдущего слоя)
* выход по форме совпадает со входом
* есть два подслоя -- self-attention и за ним обычная FFNN
* мимо этих двух подслоёв есть residual connection
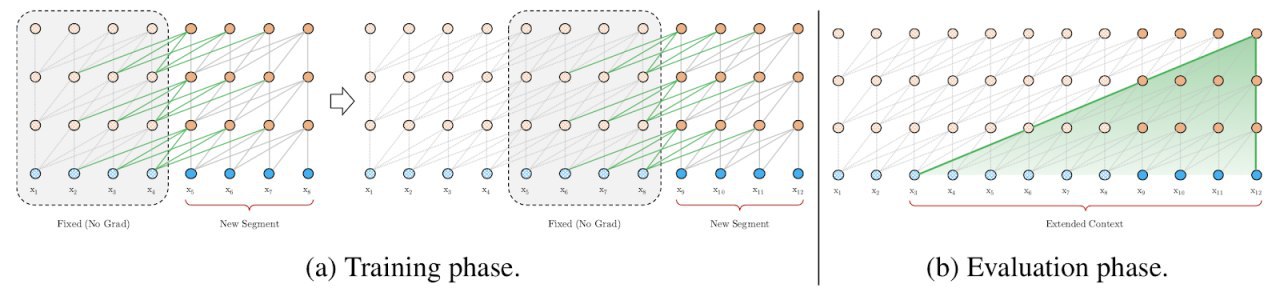
* self-attention смотрит на все слова входа сразу, поэтому общая длина входа сетки фиксирована, это важный момент. Вот как происходит обработка 1 входного слова:
- из входного эмбеддинга путём умножения на 3 обучаемые матрицы получаем 3 вектора (Query, Key, Value)
- сравнивая Query-вектор слова с Key-векторами всех слов входа, получаем веса внимания по этим другим словам.
- складываем их Value-вектора с весами внимания, полученный вектор и есть выход подслоя self-attention для данного слова
* multi-headed attention означает что вот эти все трюки с QKV мы параллельно независимо делаем несколько раз, это по задумке даёт сетке возможных выучить несколько разных взаимодополняющих механизмов внимания; тогда на выходе получаем несколько матриц по числу головок внимания; чтобы их смёржить, конкатенируем их и проекцируем обучаемой матрицей снова в рабочую размерность
* FFNN просто независимо обрабатывает вектор каждого из слов, полученный на выходе self-attention
* перед самым выходом делается LayerNorm
В такой схеме, однако, все позиции слов равнозначны и нет понимания, кто где стоял. Поэтому придумали к эмбеддингам входа добавлять (сложением, не конкатенацией) сигнал тайминга, условно это что-то вроде гармоник, устроенных так, что чем дальше два слова, тем меньший вес имеет произведение их позиционных сигналов. Интуиция в том, что близкие слова должны больше обращать внимания друг на друга. Этот сигнал позиции добавляется только на самом нижнем слое, дальше сетка сама решит, надо ли его пробрасывать.
Декодерный слой отличается от энкодера не очень сильно:
* есть дополнительный подслой внимания через такие же Query, Key, Value, но внимание это смотрит на выход верхнего энкодера (с любого из слоёв декодера) -- чтоб не сбиваться с мысли.
* декодеру запрещено смотреть вниманием на слова декодера справа, т.е. заглядывать в будущее. Это делается просто занулением весов внимания в нужных местах.
Наверху стека мы сворачиваем финальный стейт декодера в логиты, а из них делаем софтмаксом логпробы.
При обучении end2end оптимизируем кроссэнтропию с 1-hot векторами правильных слов.
Какие у этой конструкции важные свойства:
* быстро учится и применяется
* местами хорошо параллелится
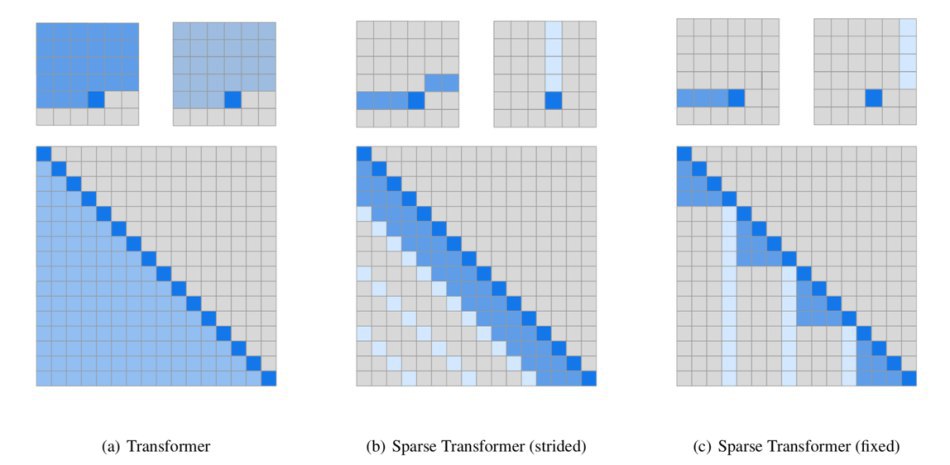
* вход имеет фиксированную длину, дальше этой длины контекста у сети быть не может
* т.к. нет рекурсии и число операций фиксировано, то утверждается, что выразительная мощность ниже чем Turing Complete