Regularizing and Optimizing LSTM Language Models
Stephen Merity, Nitish Shirish Keskar, Richard Socher
Salesforce Research
#LM #regularization #NLP #ICLR #2018
Статья: https://arxiv.org/abs/1708.02182
Пара пересказов: https://yashuseth.blog/2018/09/12/awd-lstm-explanation-understanding-language-model/, https://medium.com/@bingobee01/a-review-of-dropout-as-applied-to-rnns-72e79ecd5b7b
Родной код на pytorch: https://github.com/salesforce/awd-lstm-lm
Довольно упоротая работа, также известна под кодовым названием AWD-LSTM. Суть статьи в том, как из уже известных костылей можно собрать SOTA для LM. Правда SOTA это было в 2017 году, но как обзор регуляризационных техник -- довольно полезно. Ну и оно всё ещё используется, например, ULMFiT на нём собран.
База такая:
- архитектура -- стандартный LM на базе RNN
- ядро -- многослойный LSTM или GRU или QRNN
- используют tie weights (синхронизация весов эмбеддингов в энкодере и декодере)
Дропауты:
- обычный Dropout.
- Locked Dropout (аналог variational dropout) -- dropout элементов, статичный на всё время обработки батча, используется между слоями RNN.
- DropConnect aka WeightDrop -- это Locked Dropout, но для весов на связях сети, а не активаций, используется на скрытом состоянии между тактами RNN.
- Embedding Dropout -- при обработке батча dropout на эмбеддинги делается так, что у всех слов синхронно дропаются одни и те же координаты.
Работа с градиентом:
- используют схему переключения между SGD и average SGD, утверждают, что для задач типа LM это лучше чем Adam или momentum SGD
- используют weight decay
- для каждого батча делают BPTT рандомизированной длины, при этом делают поправку на LR в зависимости от этой длины.
- используют обычный gradient clipping
- Activation Regularization (AR) -- дополнительная регуляризация на число активированных нейронов
- Temporal Activation Regularization (AR) -- аналогично, но на первую производную числа активированных нейронов
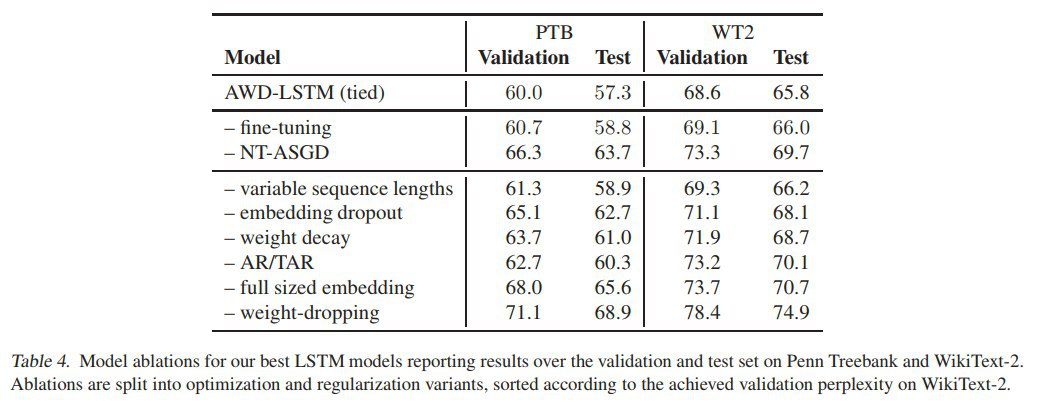
Приводят сравнительныей анализ эффективности этих методов, см табличку:
Stephen Merity, Nitish Shirish Keskar, Richard Socher
Salesforce Research
#LM #regularization #NLP #ICLR #2018
Статья: https://arxiv.org/abs/1708.02182
Пара пересказов: https://yashuseth.blog/2018/09/12/awd-lstm-explanation-understanding-language-model/, https://medium.com/@bingobee01/a-review-of-dropout-as-applied-to-rnns-72e79ecd5b7b
Родной код на pytorch: https://github.com/salesforce/awd-lstm-lm
Довольно упоротая работа, также известна под кодовым названием AWD-LSTM. Суть статьи в том, как из уже известных костылей можно собрать SOTA для LM. Правда SOTA это было в 2017 году, но как обзор регуляризационных техник -- довольно полезно. Ну и оно всё ещё используется, например, ULMFiT на нём собран.
База такая:
- архитектура -- стандартный LM на базе RNN
- ядро -- многослойный LSTM или GRU или QRNN
- используют tie weights (синхронизация весов эмбеддингов в энкодере и декодере)
Дропауты:
- обычный Dropout.
- Locked Dropout (аналог variational dropout) -- dropout элементов, статичный на всё время обработки батча, используется между слоями RNN.
- DropConnect aka WeightDrop -- это Locked Dropout, но для весов на связях сети, а не активаций, используется на скрытом состоянии между тактами RNN.
- Embedding Dropout -- при обработке батча dropout на эмбеддинги делается так, что у всех слов синхронно дропаются одни и те же координаты.
Работа с градиентом:
- используют схему переключения между SGD и average SGD, утверждают, что для задач типа LM это лучше чем Adam или momentum SGD
- используют weight decay
- для каждого батча делают BPTT рандомизированной длины, при этом делают поправку на LR в зависимости от этой длины.
- используют обычный gradient clipping
- Activation Regularization (AR) -- дополнительная регуляризация на число активированных нейронов
- Temporal Activation Regularization (AR) -- аналогично, но на первую производную числа активированных нейронов
Приводят сравнительныей анализ эффективности этих методов, см табличку: