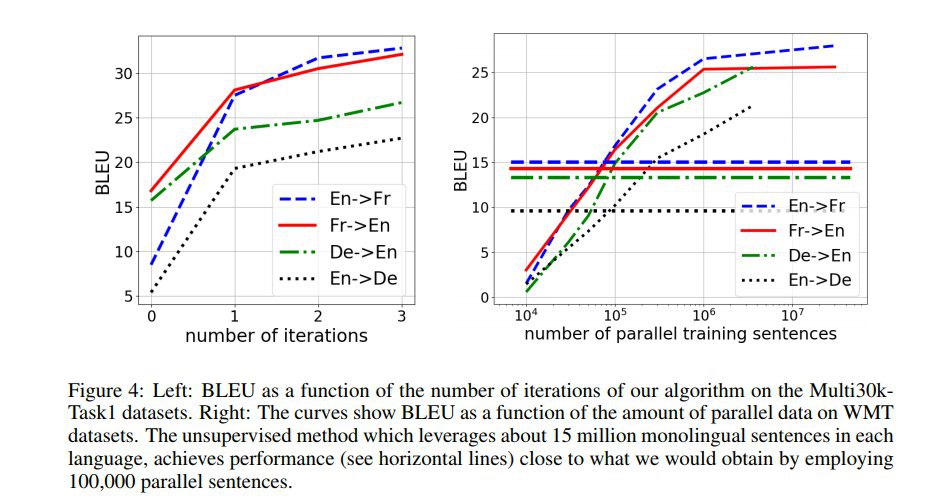
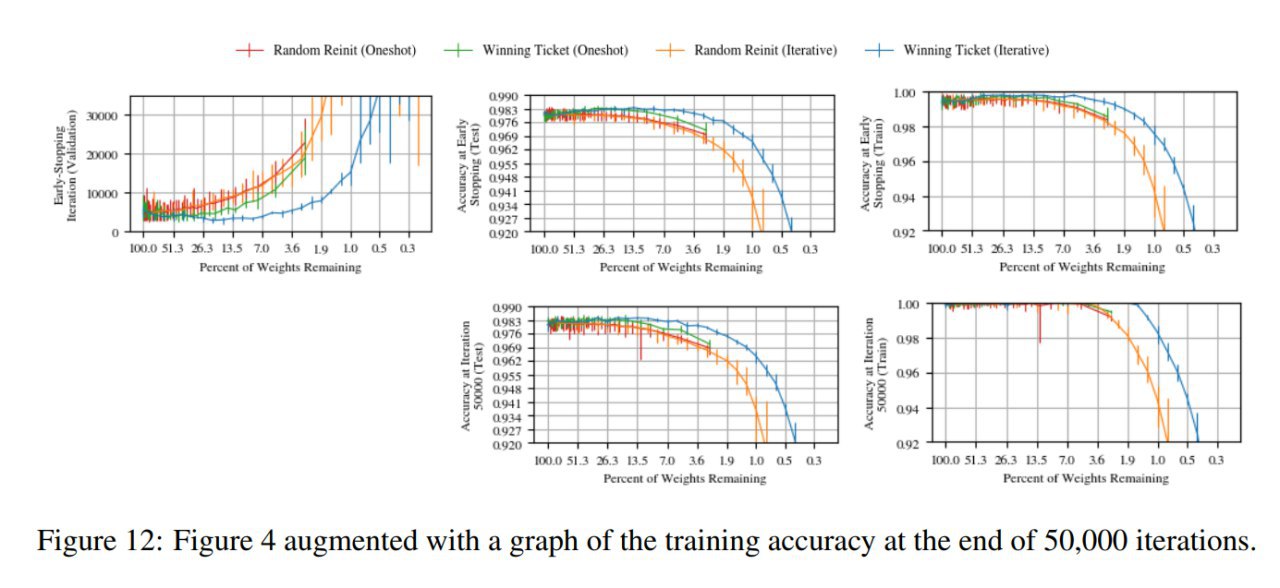
AET vs. AED: Unsupervised Representation Learning by Auto-Encoding Transformations rather than Data
Liheng Zhang, Guo-Jun Qi, Liqiang Wang, Jiebo Luo
(University of Central Florida, Huawei Cloud, University of Rochester)
https://arxiv.org/abs/1901.04596
#AE #unsupervised #representation_learning
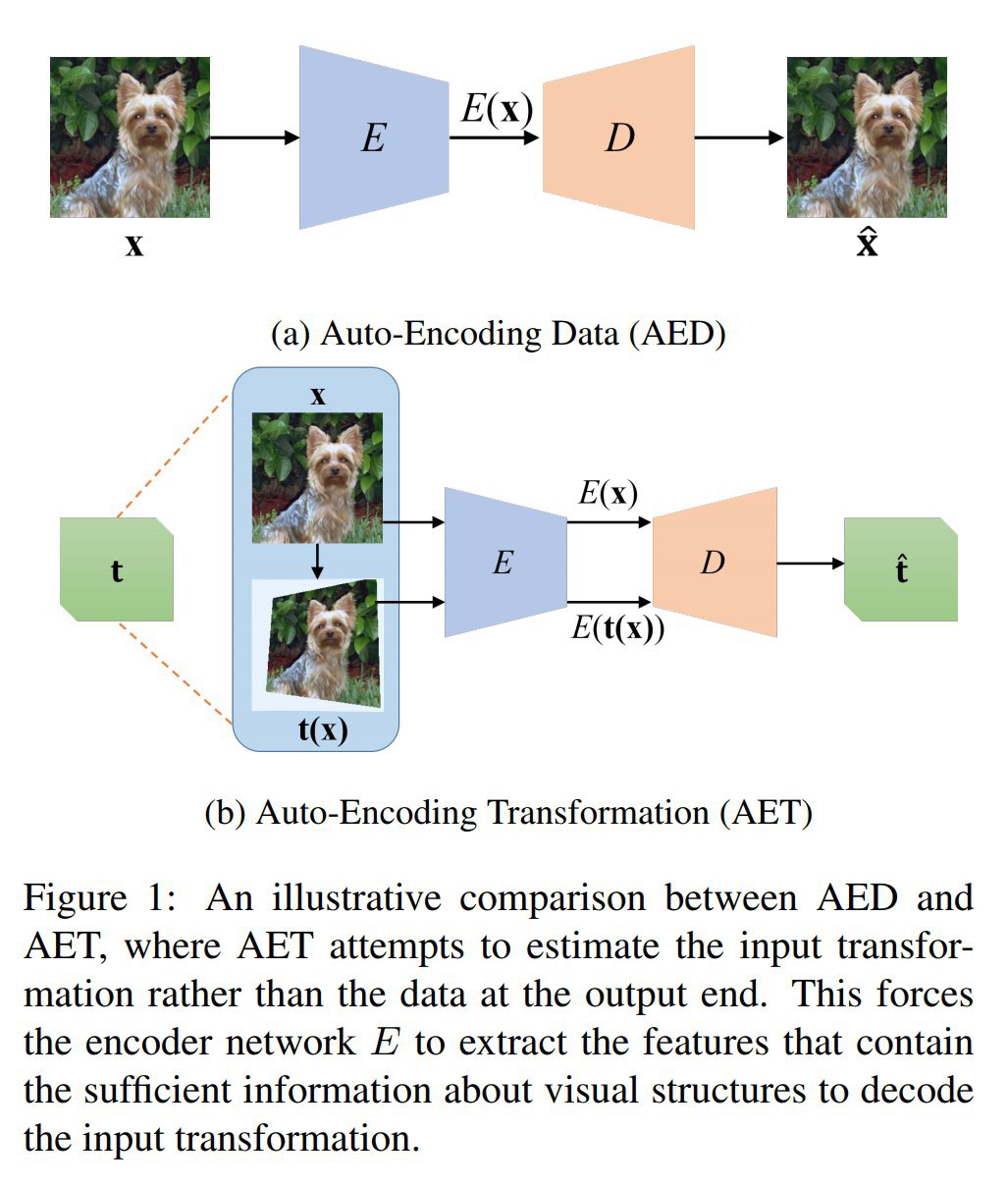
Прикольная идея про выучивание произведённых над данными трансформаций вместо выучивания восстановления самих данных (как в обычном автоэнкодере, Auto-encoding Data, AED).
Идея в том, что мы сэмплим из некоторого заготовленного пространства возможных операций трансформации изображений, применяем выбранную трансформацию к изображению, и подаём на автоэнкодер исходное и трансформированное изображение. Автоэнкодер должен на выходе корректно восстановить трансформацию (отсюда название Auto-encoding Transformations, AET).
Обсуждаются три вида преобразований:
1) Параметрические преобразования (например, афинные — тогда функция ошибки это L2 от разности матриц параметров);
2) GAN-преобразования (с генератором, принимающим на вход изображение в дополнение к обычному шуму z — loss тогда это снова L2, но теперь от разности z);
3) Непараметрические (где loss это матожидание расстояния между двумя трансформированными изображениями).
Дальше в работе рассматривают только параметрические преобразования. Это типа проще реализовывать, а также проще сравнивать с другими unsupervised методами.
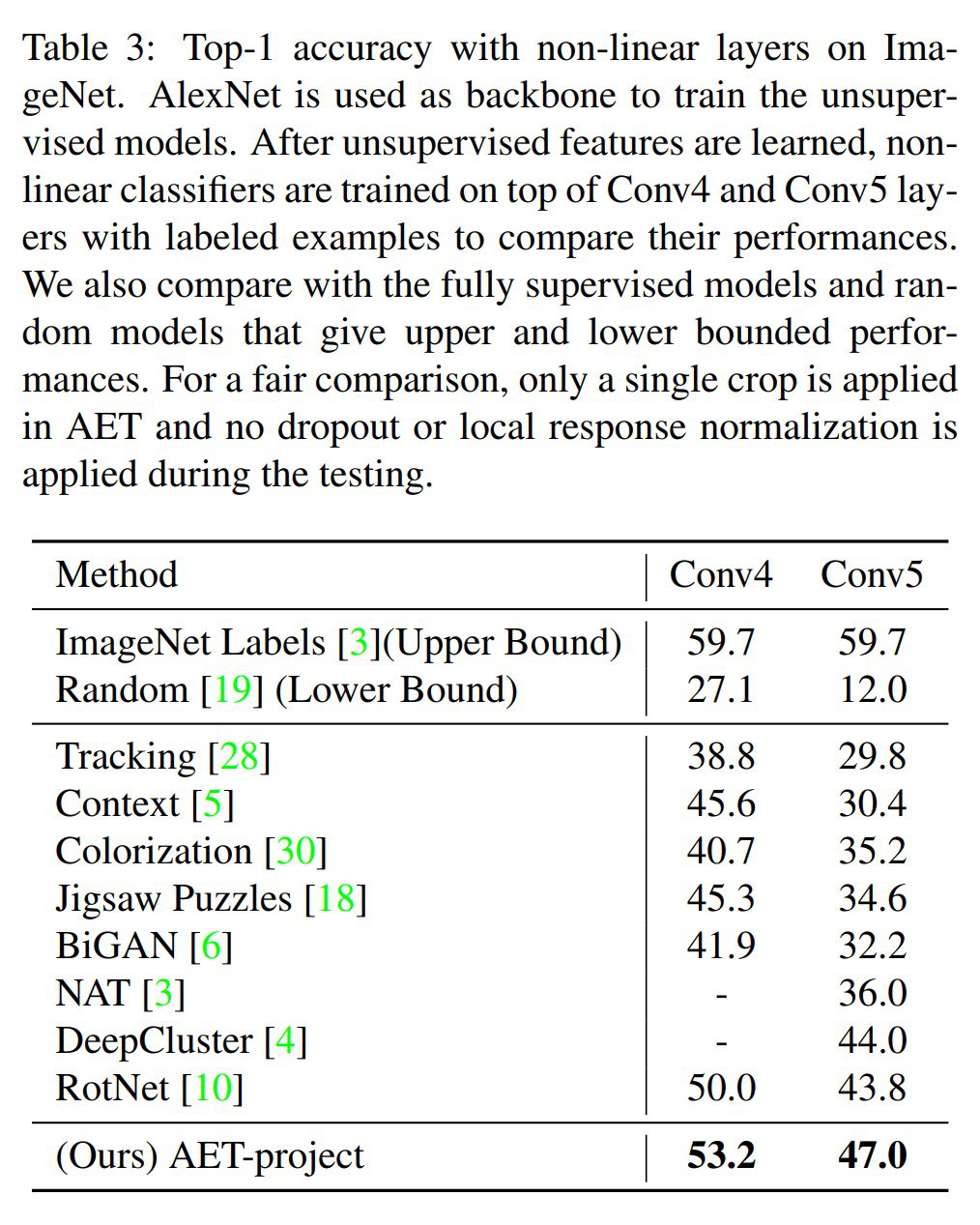
Показывают, что AET выучивает классные фичи, с использованием которых потом простенькие классификаторы приближаются к результатам supervised моделей (на датасетах CIFAR-10, ImageNet, Places).
Liheng Zhang, Guo-Jun Qi, Liqiang Wang, Jiebo Luo
(University of Central Florida, Huawei Cloud, University of Rochester)
https://arxiv.org/abs/1901.04596
#AE #unsupervised #representation_learning
Прикольная идея про выучивание произведённых над данными трансформаций вместо выучивания восстановления самих данных (как в обычном автоэнкодере, Auto-encoding Data, AED).
Идея в том, что мы сэмплим из некоторого заготовленного пространства возможных операций трансформации изображений, применяем выбранную трансформацию к изображению, и подаём на автоэнкодер исходное и трансформированное изображение. Автоэнкодер должен на выходе корректно восстановить трансформацию (отсюда название Auto-encoding Transformations, AET).
Обсуждаются три вида преобразований:
1) Параметрические преобразования (например, афинные — тогда функция ошибки это L2 от разности матриц параметров);
2) GAN-преобразования (с генератором, принимающим на вход изображение в дополнение к обычному шуму z — loss тогда это снова L2, но теперь от разности z);
3) Непараметрические (где loss это матожидание расстояния между двумя трансформированными изображениями).
Дальше в работе рассматривают только параметрические преобразования. Это типа проще реализовывать, а также проще сравнивать с другими unsupervised методами.
Показывают, что AET выучивает классные фичи, с использованием которых потом простенькие классификаторы приближаются к результатам supervised моделей (на датасетах CIFAR-10, ImageNet, Places).