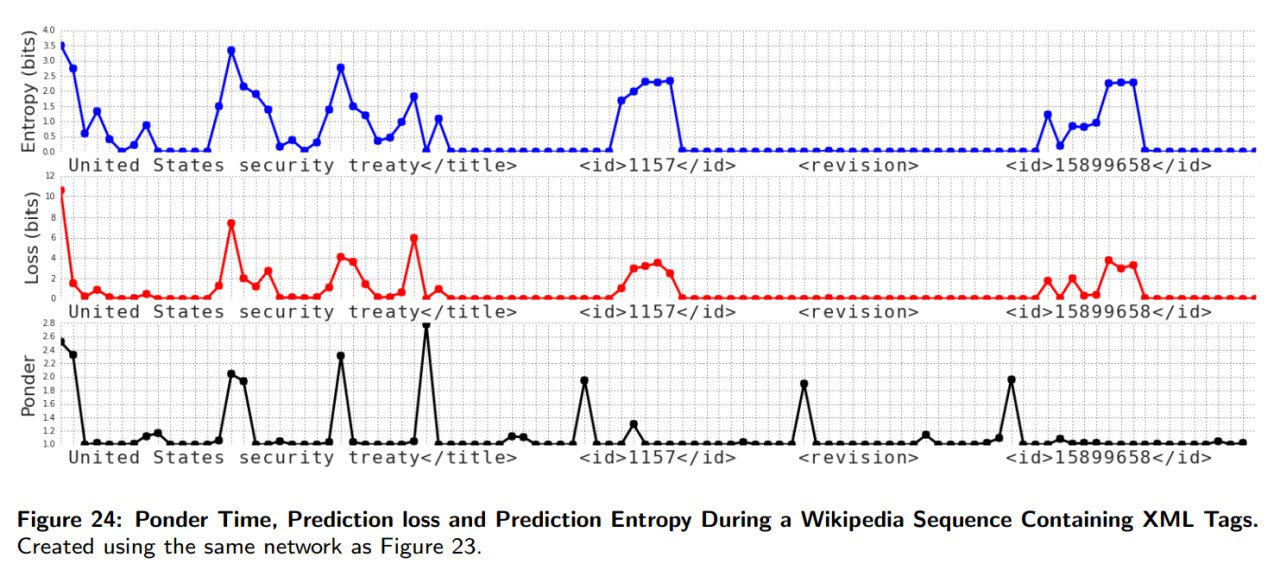
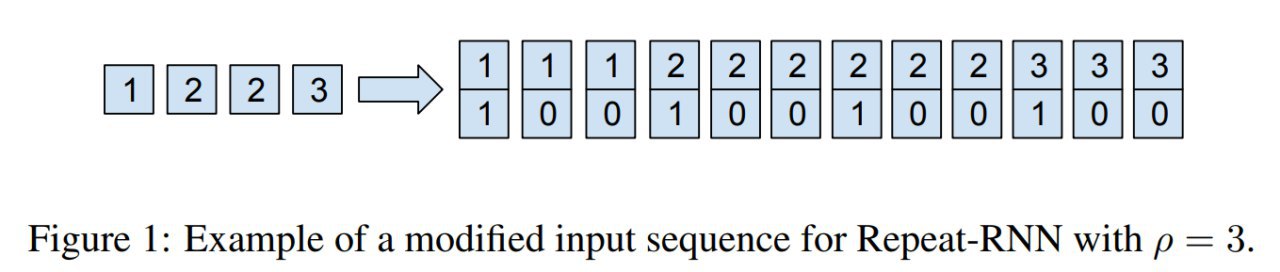
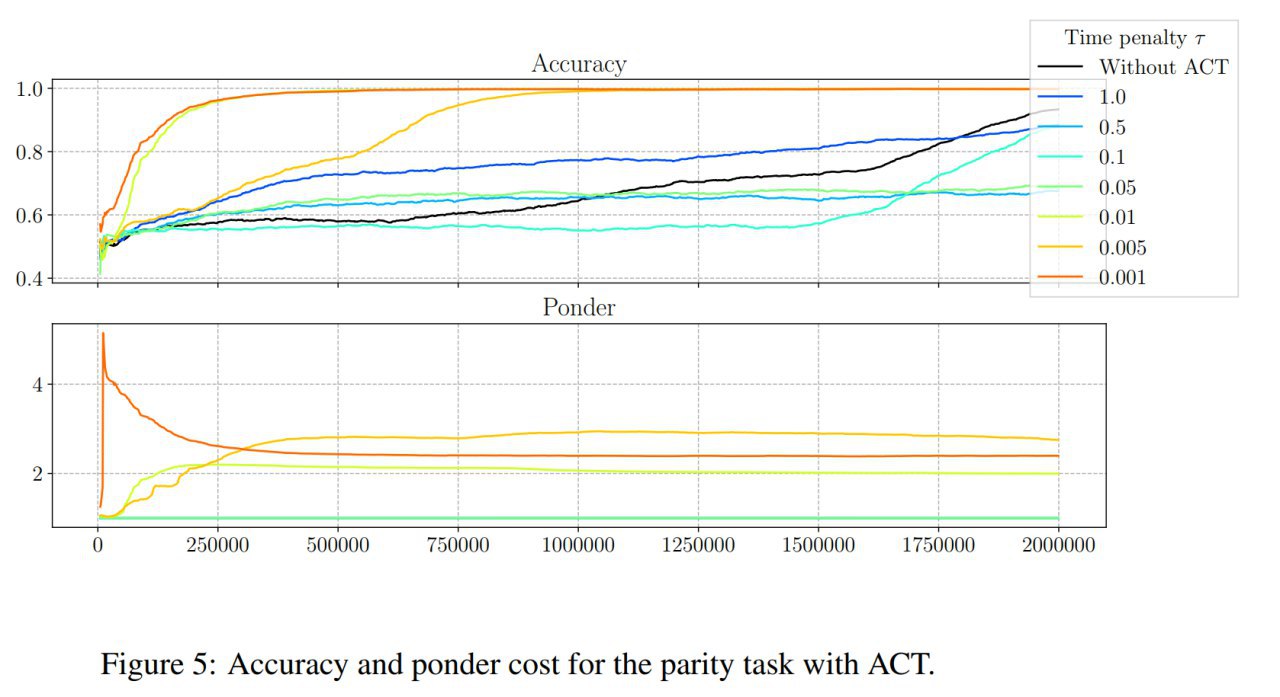
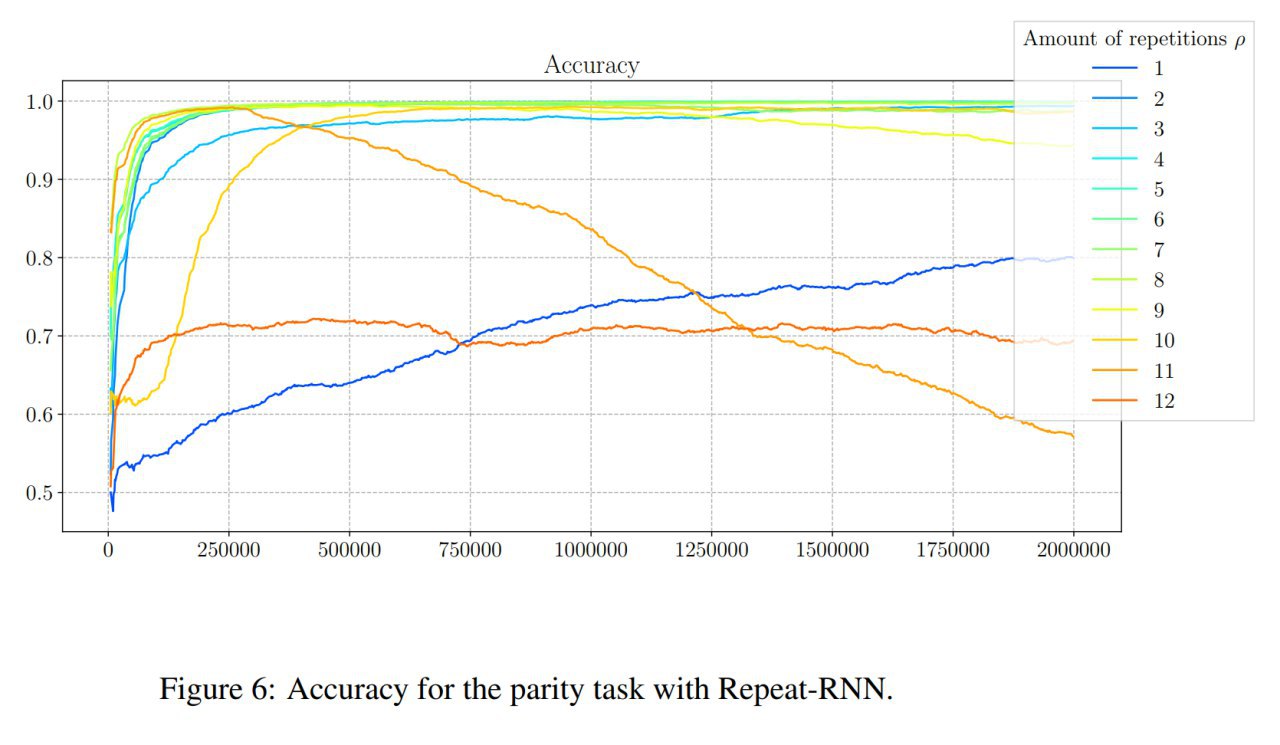
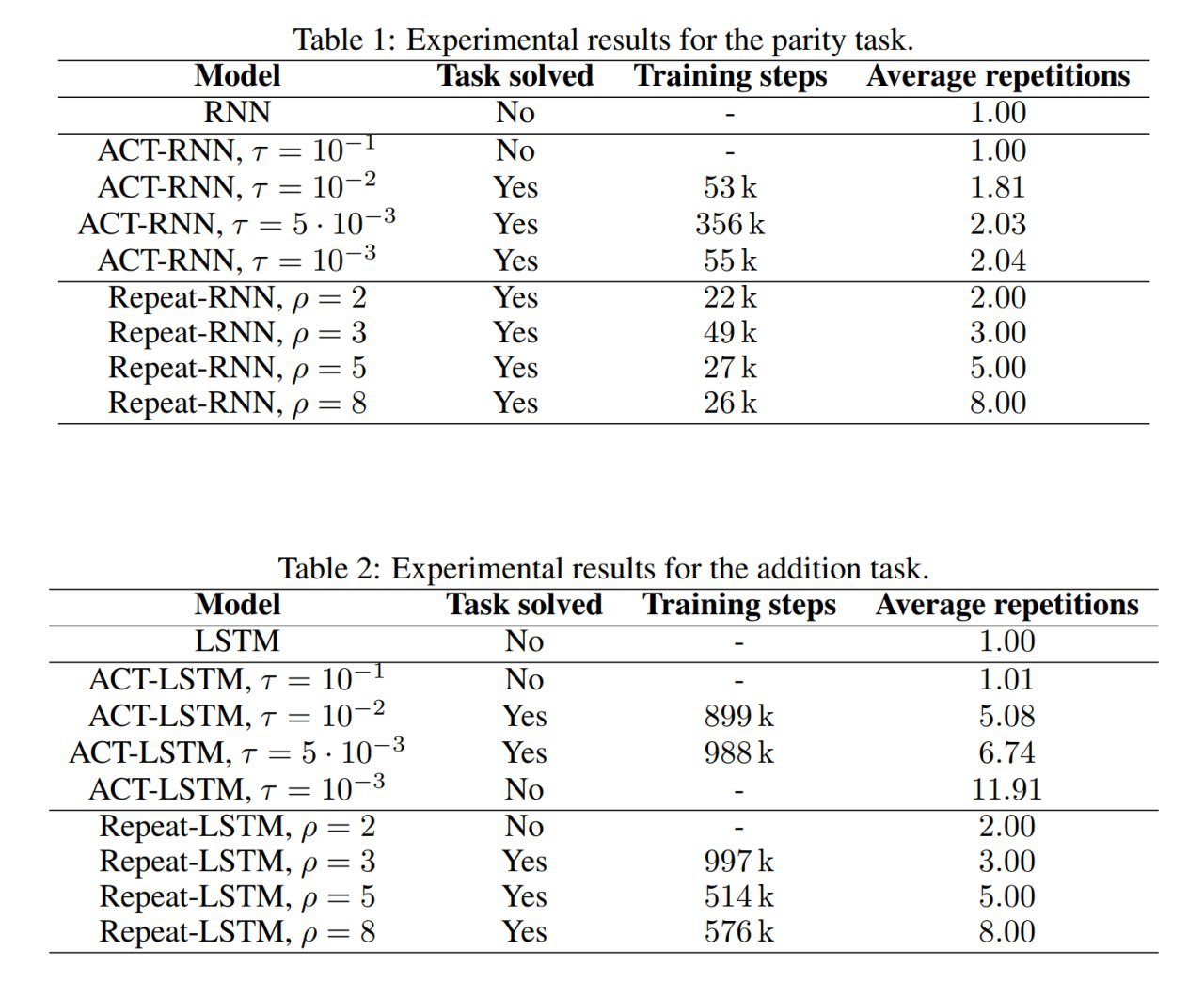
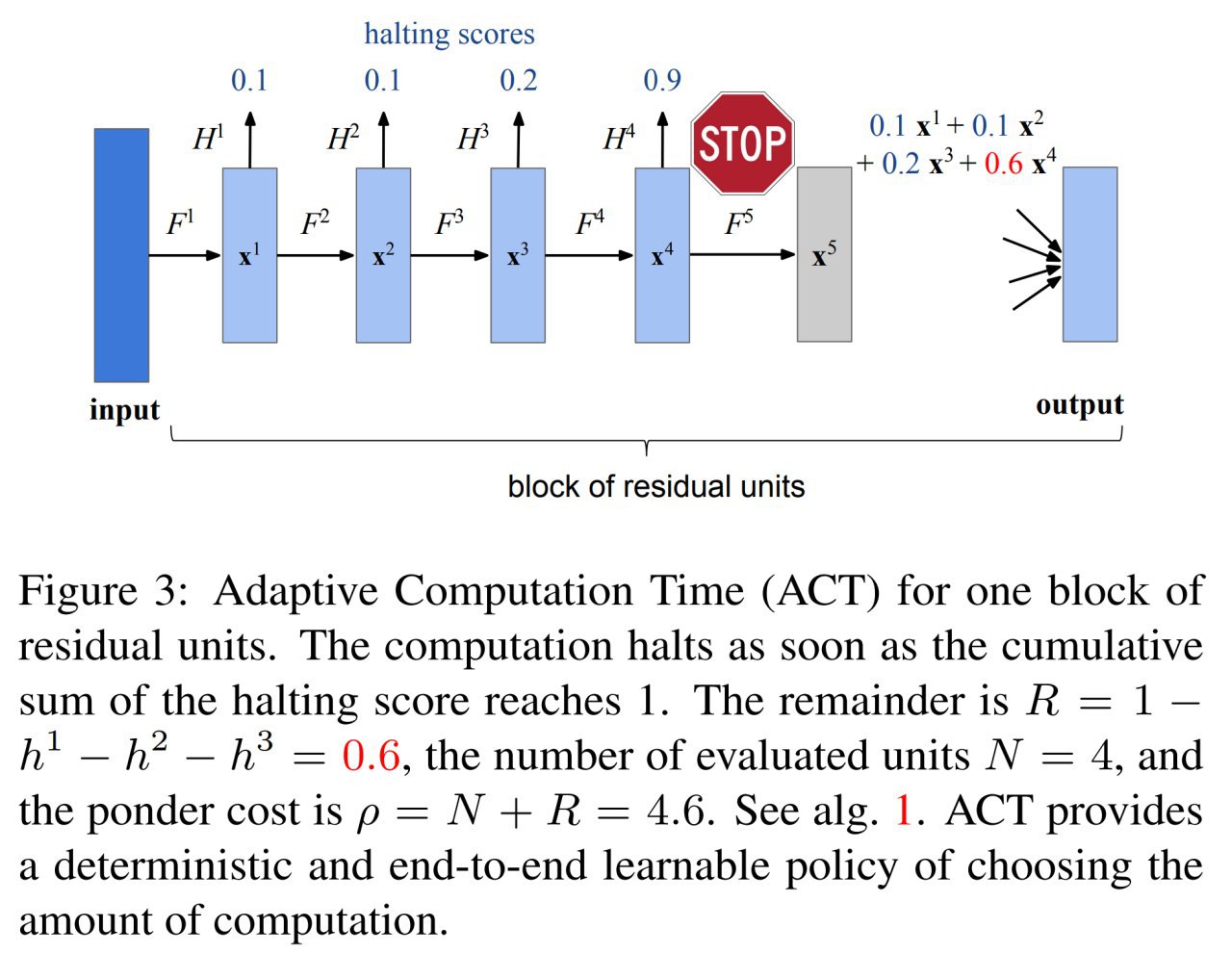
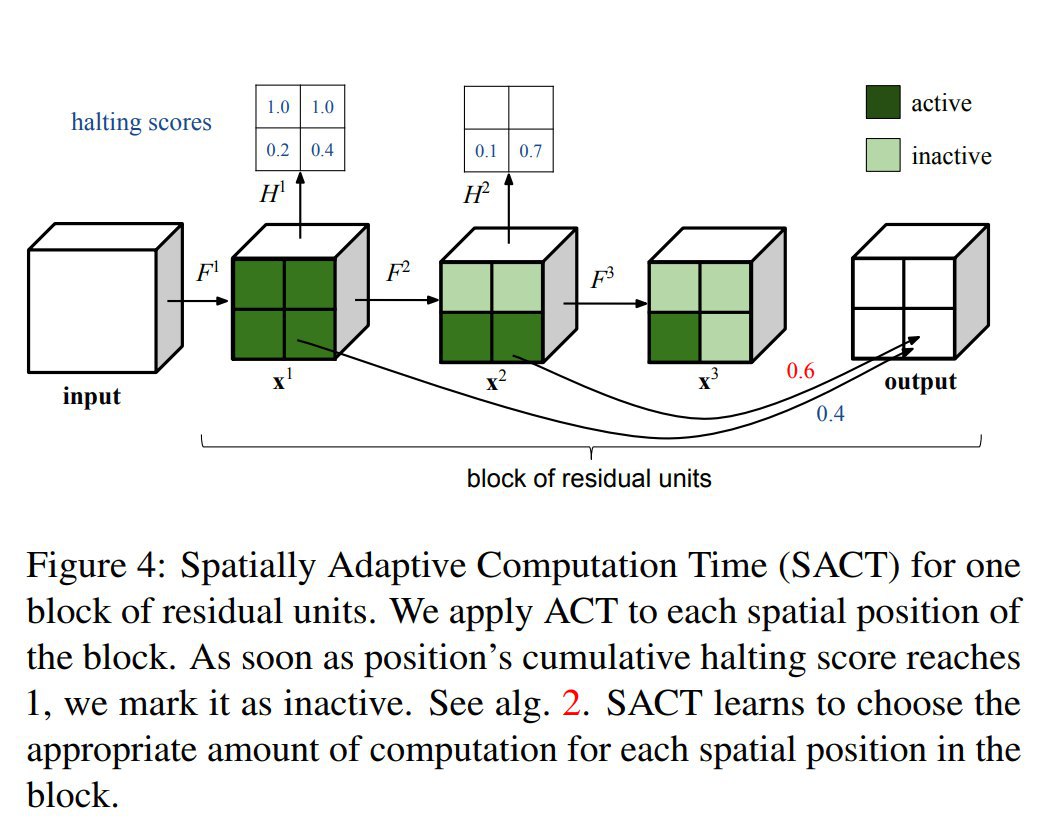
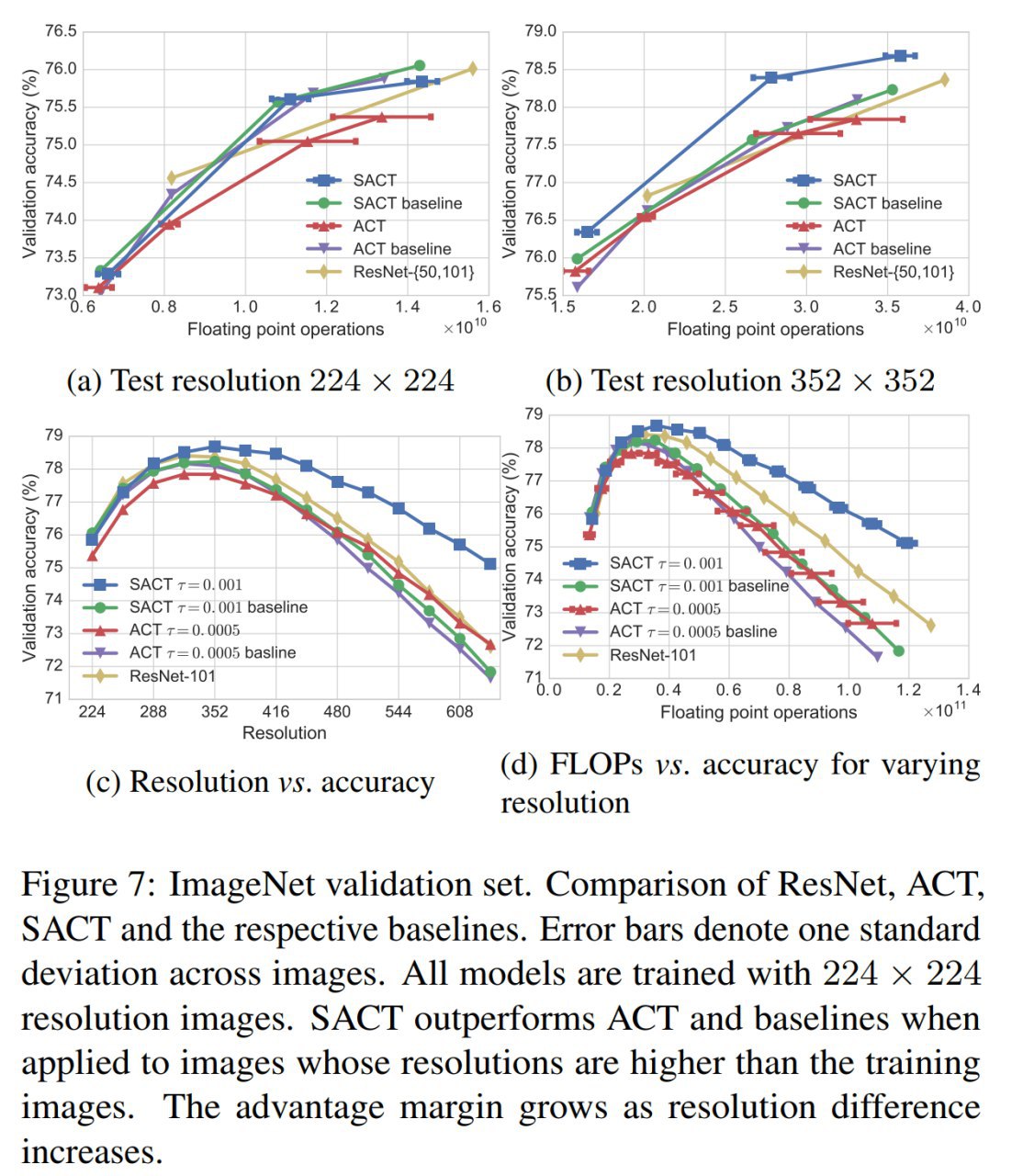
Небольшой follow-up со ссылками и замечаниями от читателей + то, что я сам ещё нашёл по теме.
1. Идею, похожую на Relative Positional Encoding из TXL, предлагали ещё в марте 2018 в Self-Attention with Relative Position Representations (https://arxiv.org/abs/1803.02155), но дальше не развили. Кстати, интересно, судя по коду BERT или реализации GPT-2 от huggingface, видно, что там вообще не заморачиваются с трюками в духе кодирования позиций гармониками из оригинальной статьи -- просто учат на каждую позицию отдельный эмбеддинг.
2. В оригинальной статье про Трансформер используется LDAN порядок слоев (Layer, Dropout, Add, Normalize). На практике все (в том числе официальная реализация в t2t) использует NLDA порядок, это сильно улучшает стабильность обучения и позволяет учить более глубокие архитектуры.
3. Была ещё статья Image Transformer (https://arxiv.org/abs/1802.05751), она посвящена модификации Т для работы с изображениями.
Если я правильно понял из беглого просмотра, основные модификации такие:
* делается кодирование двумерных координат пикселей
* делается локальное внимание в небольшом окне, чтобы избежать X^2
4. Бонус -- практические советы по обучению реализации трансформера из официального пакета Гугла: https://arxiv.org/abs/1804.00247
1. Идею, похожую на Relative Positional Encoding из TXL, предлагали ещё в марте 2018 в Self-Attention with Relative Position Representations (https://arxiv.org/abs/1803.02155), но дальше не развили. Кстати, интересно, судя по коду BERT или реализации GPT-2 от huggingface, видно, что там вообще не заморачиваются с трюками в духе кодирования позиций гармониками из оригинальной статьи -- просто учат на каждую позицию отдельный эмбеддинг.
2. В оригинальной статье про Трансформер используется LDAN порядок слоев (Layer, Dropout, Add, Normalize). На практике все (в том числе официальная реализация в t2t) использует NLDA порядок, это сильно улучшает стабильность обучения и позволяет учить более глубокие архитектуры.
3. Была ещё статья Image Transformer (https://arxiv.org/abs/1802.05751), она посвящена модификации Т для работы с изображениями.
Если я правильно понял из беглого просмотра, основные модификации такие:
* делается кодирование двумерных координат пикселей
* делается локальное внимание в небольшом окне, чтобы избежать X^2
4. Бонус -- практические советы по обучению реализации трансформера из официального пакета Гугла: https://arxiv.org/abs/1804.00247