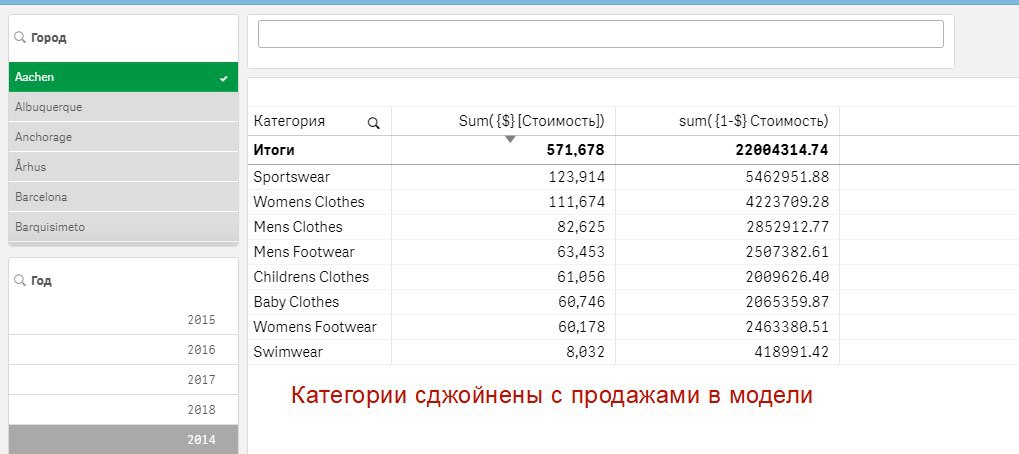
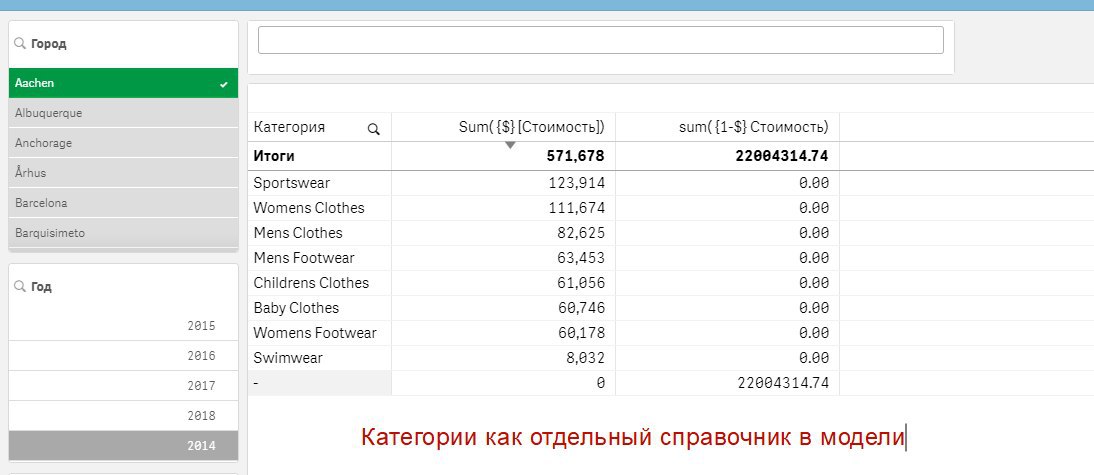
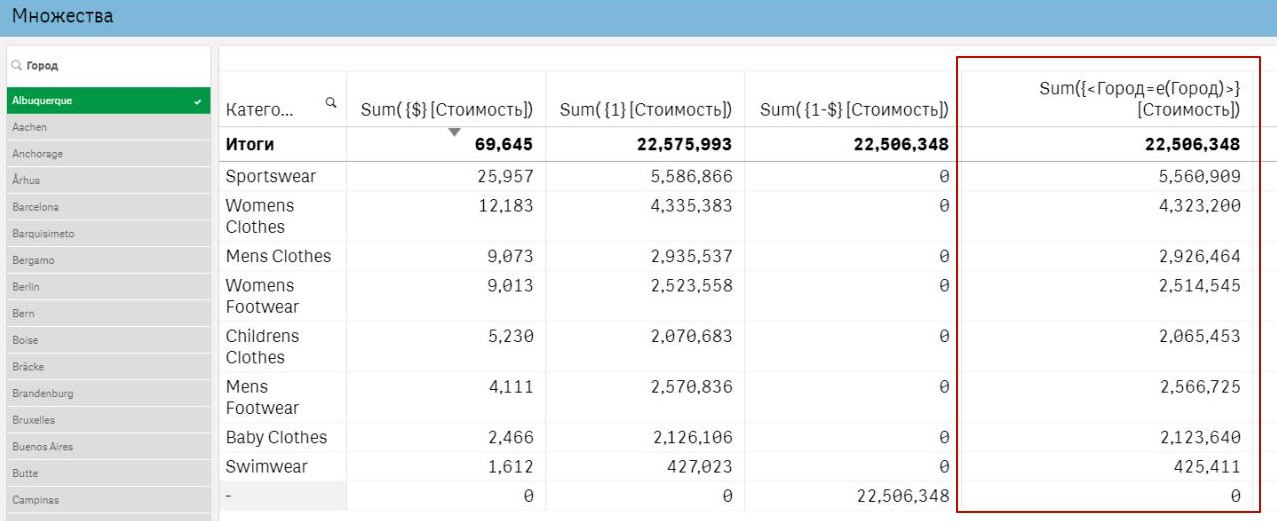
YT
Коллеги, нужна ваша помощь :)
Есть 2 выборки с разных БД. Это показания счетчиков дата+время данного показания. В обеих выборках поля "дата+время", "значение счетчика". Единственная разница в том, что в одной выборке показания каждые пол часа приходят, в другой раз в час.
Задача привести выборку получасовую к почасовой, соответвенно показания получасовые сложить между собой. Уверен решение легкое, но мне не приходит в голову к сожалению )
Есть 2 выборки с разных БД. Это показания счетчиков дата+время данного показания. В обеих выборках поля "дата+время", "значение счетчика". Единственная разница в том, что в одной выборке показания каждые пол часа приходят, в другой раз в час.
Задача привести выборку получасовую к почасовой, соответвенно показания получасовые сложить между собой. Уверен решение легкое, но мне не приходит в голову к сожалению )
Показания какого рода? Это обороты или типа одометра?