h
можете скинуть ваши данные, хотя бы ненастоящие, но по структуре нужные?
Size: a a a
h
IS
IS
{r}
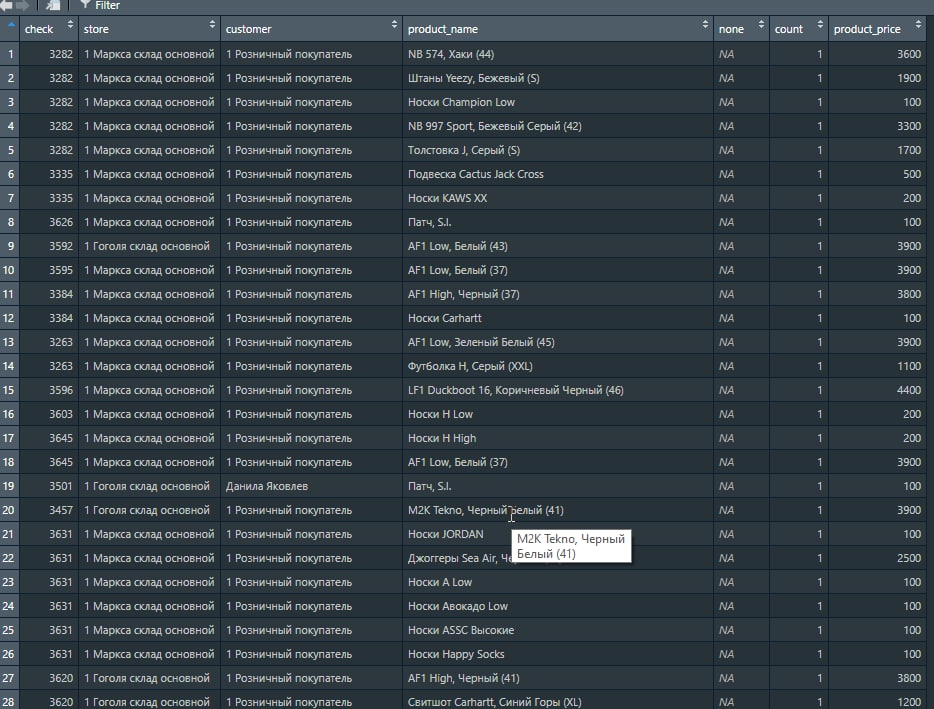
# считываем сырье и формируем предварительную табличку на разбор
raw_dt <- here::here("data", "etl", "m_and_s.zip") %>%
readr::read_lines(skip = 2) %>%
tibble::enframe(name = NULL) %>%
setDT()
temp_dt <- raw_dt %>%
# расставляем маркеры начала записей по якорным словам
.[, line_start := stri_detect_regex(value,
pattern = "склад")] %>%
.[, idx := cumsum(line_start)] %>%
# разделяем на колонки и заполняем пустоты (делаем прямоугольное представление)
.[line_start == TRUE, part1 := value] %>%
.[line_start == FALSE, part2 := value] %>%
# для быстрой проливки строк можно делать группировки, locf и пр.
# выберем вариант data.table, проливаем первую строку по группам
.[, part1 := head(part1, 1), by = idx] %>%
# забираем только полезные данные
.[!is.na(part2)] %>%
.[, data := stri_join(part1, part2)]
# отправляем повторно на штатный парсер csv
df <- stri_c(temp_dt$data, collapse = "\n") %>%
readr::read_delim(
delim = ";",
col_names = c("cheсk", "store", "customer", "product_name", "none", "count", "product_price")
)P
K
K
АМ
K
h
АМ
h
IS
h
h
IS
АМ