



M
кажется, что автор спрашивал не про решение на R, а мне как-то не очень важно, так что не утруждайтесь 😊
Size: a a a
M
M
IS
V
IS
{r}
df <- data.frame(
index = c(1,2,3,4,5),
Customer = c("A", NA, "B", "C", NA),
Value = c(1, NA, 1, 1, NA),
"Customer(1)" = c(NA, "A", NA, NA, "D"),
Value = c(NA, 1, NA, NA, 1)
)
# выкинем индекс за ненужностью, переименуем колонки по унифицированным правилам
nn <- 1:ncol(df) %>%
{paste(ifelse(. %% 2 == 1, "val", "customer"), . %/% 2, sep = "_")}
df1 <- df %>%
setnames(nn) %>%
select(-1) %>%
# свернули по покупателям
pivot_longer(cols = starts_with("customer"),
names_to = "customer",
values_to = "product") %>%
drop_na(product) %>%
# свернули по штукам
pivot_longer(cols = starts_with("val_"),
names_to = NULL,
values_to = "amount") %>%
drop_na()
df1 %>% count(customer)
Ну вот и получаем примерно такое> df1
# A tibble: 5 x 3
customer product amount
<chr> <chr> <dbl>
1 customer_1 A 1
2 customer_2 A 1
3 customer_1 B 1
4 customer_1 C 1
5 customer_2 D 1
> df1 %>% count(customer)
# A tibble: 2 x 2
customer n
<chr> <int>
1 customer_1 3
2 customer_2 2
M
IS
V
M
V
IS
M
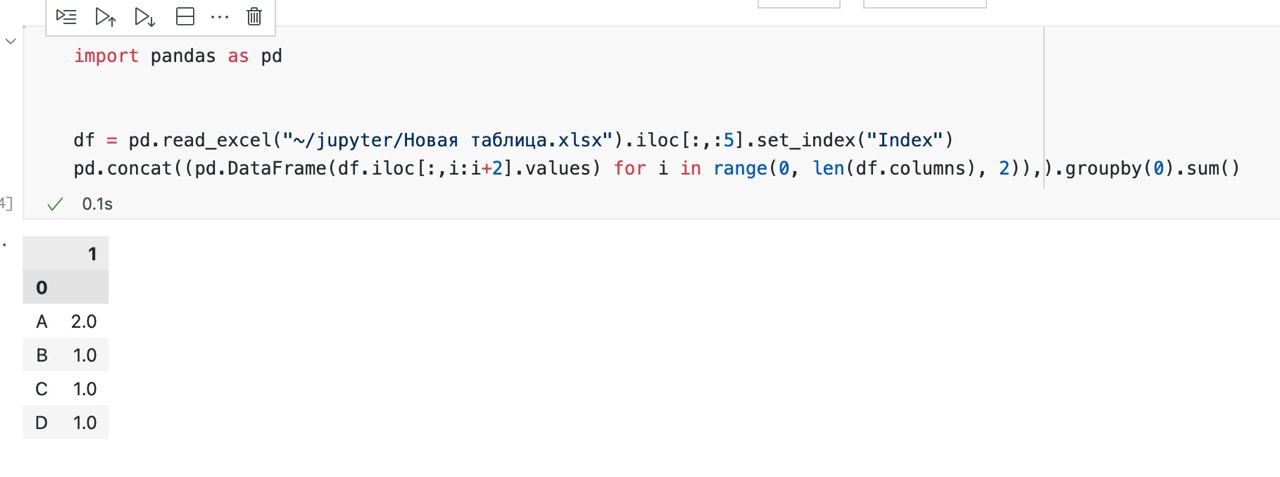
pd.concat((pd.DataFrame(df.iloc[:,i:i+2].values) for i in range(0, len(df.columns), 2)),).groupby(0).sum()M
IS
IS
M
IS
M
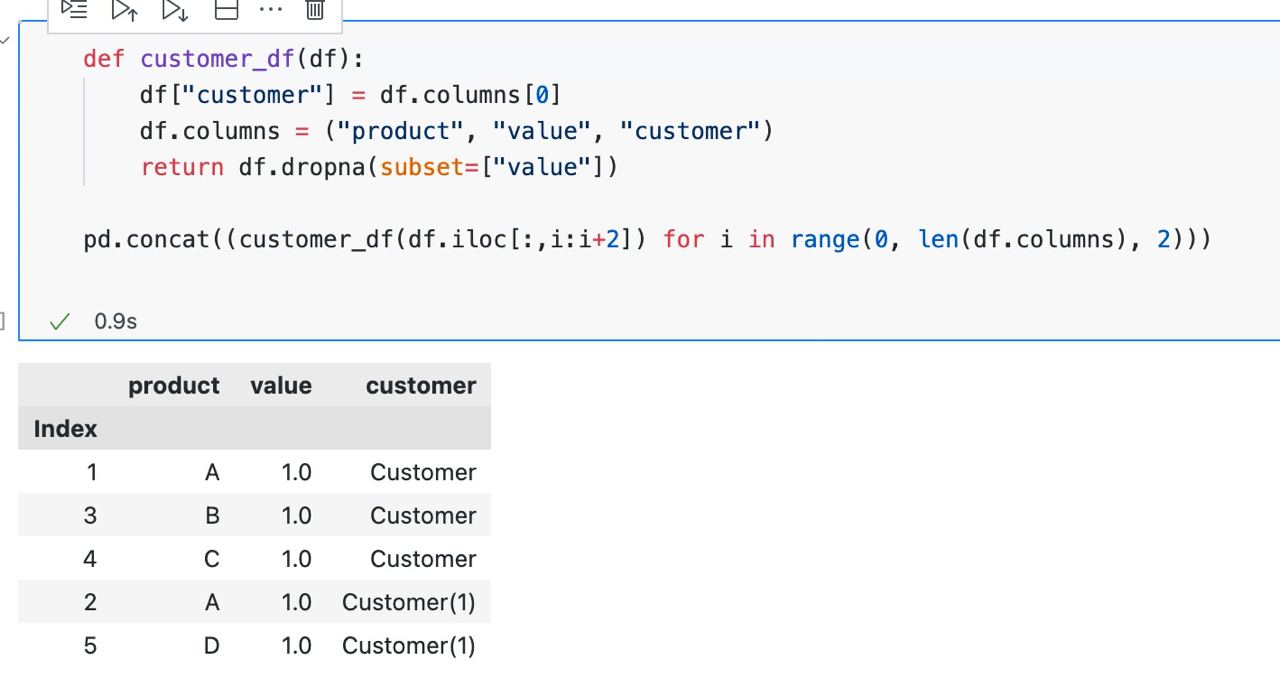
def customer_df(df):
df["customer"] = df.columns[0]
df.columns = ("product", "value", "customer")
return df.dropna(subset=["value"])
pd.concat((customer_df(df.iloc[:,i:i+2]) for i in range(0, len(df.columns), 2)))