



AD
то что ты описал называется бекенд
и немного фронта - это там где формочки для юзера
и немного фронта - это там где формочки для юзера
Size: a a a
AD
VM
МК
@
МК
VM
@
VM
МК
DP
aa
IS
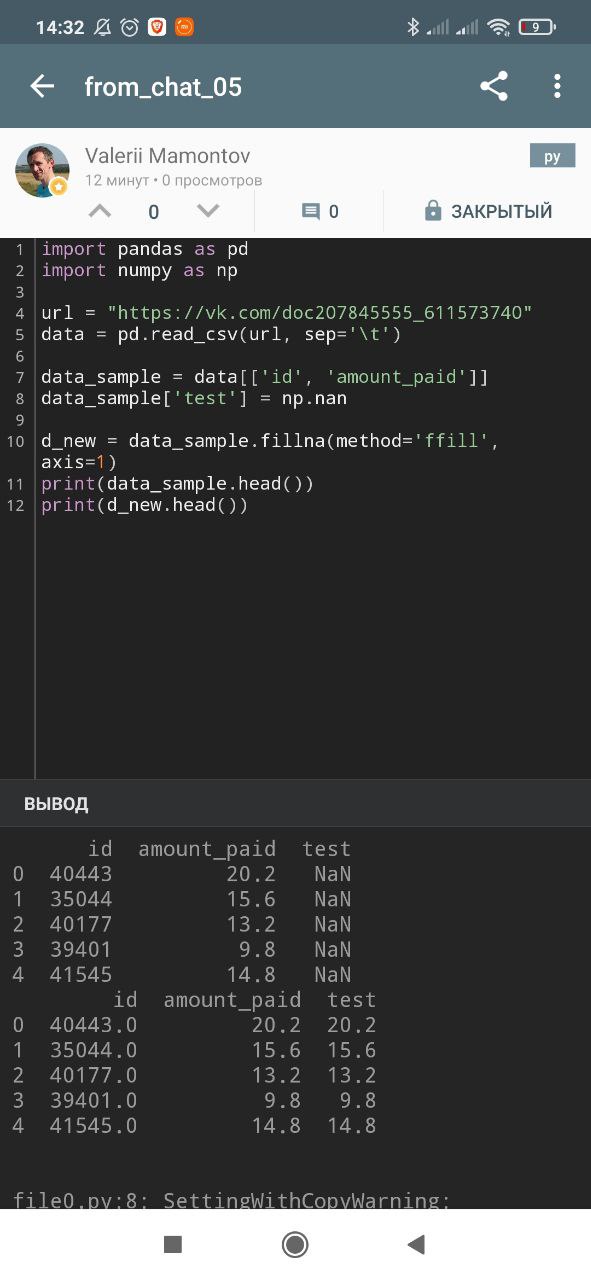
ffill — один из вариантов.import pandas as pd
import numpy as np
# Coalesce
df = pd.DataFrame({
'Hourly Rate': [20, 30, np.nan, 28, np.nan, 17, np.nan,22, 32],
'Daily Rate': [72, 74,65,80, 74, np.nan, 67,82,75]})
df
df.ffill(axis = 1)
1
IS
МК
PZ
PZ
1
PZ
