Память на сердечниках) . жаргон такой
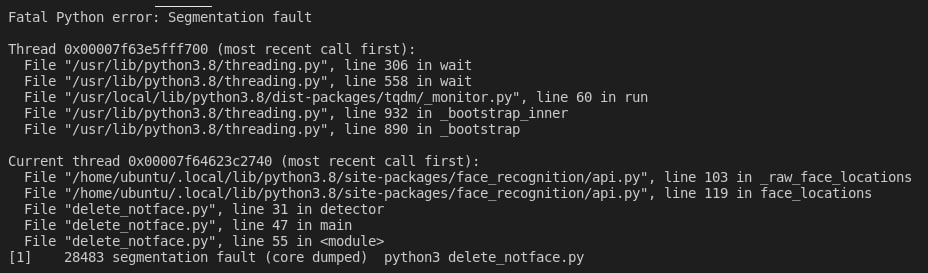
когда программа "падает", должен образоваться файл core, который представляет собой слепок памяти в этот момент.
вот его можно через gdb проанализировать.
не факт что получится самому разобраться, но stack trace подсказывает последовательность и названия вызовов машинного кода, из которого тоже можно делать предположения не будучи программистом на Си. Довольно часто это работает. Во всяком случае, будет что погуглить более конкретно по названию функций.
если это все слишком сложно, можете просто перебирать разные варианты окружения. у людей ведь как-то работает, значит ваша проблема сравнительно редкая и зависит от условий. Например, да, от объема памяти. или конкретной фоточки