М
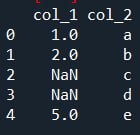
Привет) Чтобы не описывать проблему, держите сразу воспроизводимый пример) Вопрос какого фига NaN не отфильтровываются? Подкажите, плиз, как сделать так, чтобы их не было в результате?
a = pd.DataFrame({'col_1':[1, 2, np.nan, 4, 5],
'col_2':['a', 'b', 'c', 'd', 'e']})
b = pd.DataFrame({'col_1':[1, 2, np.nan, np.nan, 5],
'col_2':['a', 'b', 'c', 'd', 'e']})
b[b['col_1'].isin(a['col_1'])]