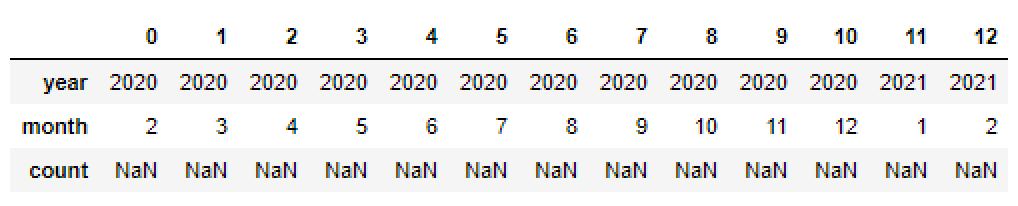
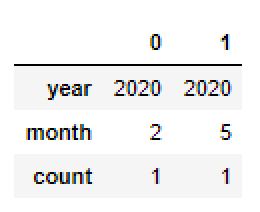
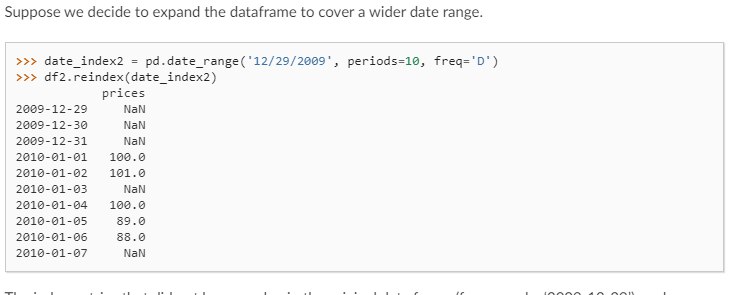
A
чо т туплю. Как в pandas границы slice в переменную сохранить
dates = ['2020-06-01':'2020-07-01'] ошибка!
supplies_9118 = supplies_9118[dates]
dates = ['2020-06-01':'2020-07-01'] ошибка!
supplies_9118 = supplies_9118[dates]
Про даты уже ответили, в общем случае срезы можно хранить через slice.
Для примера:
dates = slice('2020-06-01', '2020-07-01')
supplies = supplies_9118.loc[dates]
Аналогично можно передавать срез для полей
Для примера:
dates = slice('2020-06-01', '2020-07-01')
supplies = supplies_9118.loc[dates]
Аналогично можно передавать срез для полей