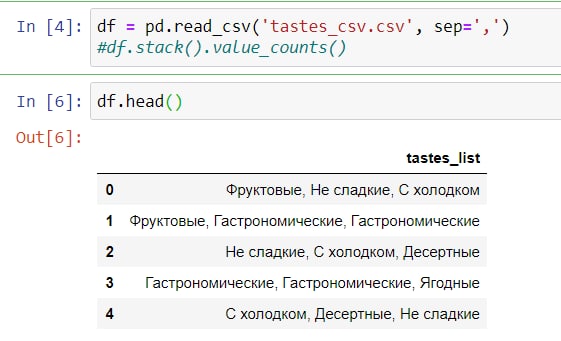
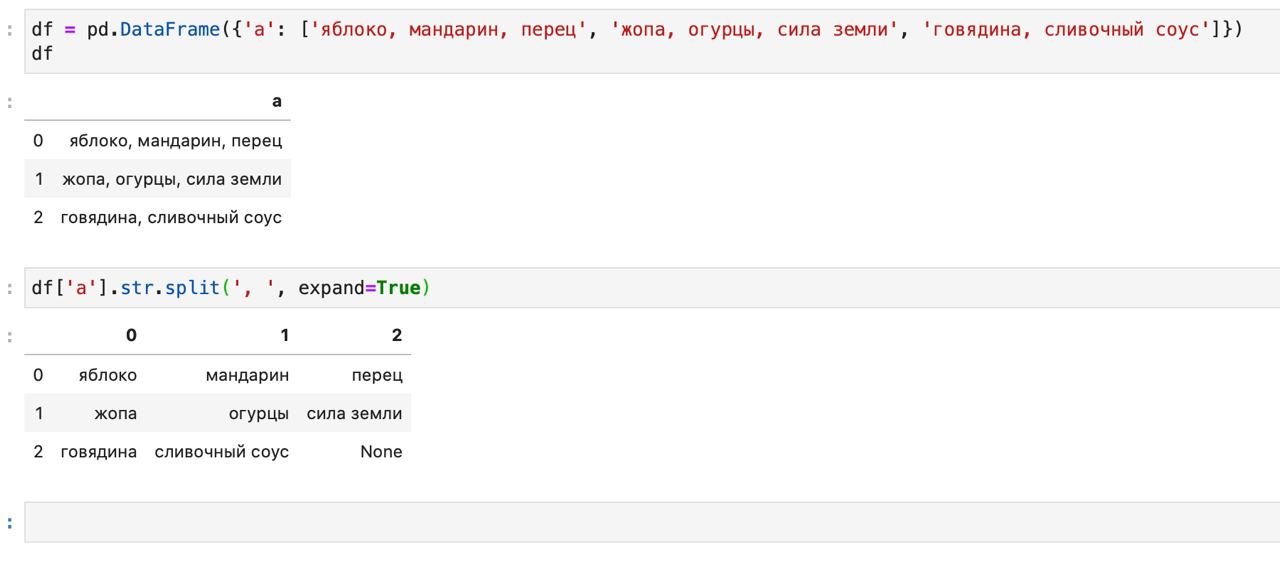
А
Добрый день.
Помогите советом. Есть датафрейм в нём некоторые данные надо "замаскировать" что бы вместо строки был какой нибудь инт. Но что бы можно было потом в любое время расшифровать и отображать норм данные.
Например, отдать данные подрядчику и потом после анализа/обработки расшифровать.
Нужно писать функцию? Что то подсказывает что есть готовое решение.
Помогите советом. Есть датафрейм в нём некоторые данные надо "замаскировать" что бы вместо строки был какой нибудь инт. Но что бы можно было потом в любое время расшифровать и отображать норм данные.
Например, отдать данные подрядчику и потом после анализа/обработки расшифровать.
Нужно писать функцию? Что то подсказывает что есть готовое решение.