



K
Size: a a a
2020 December 14
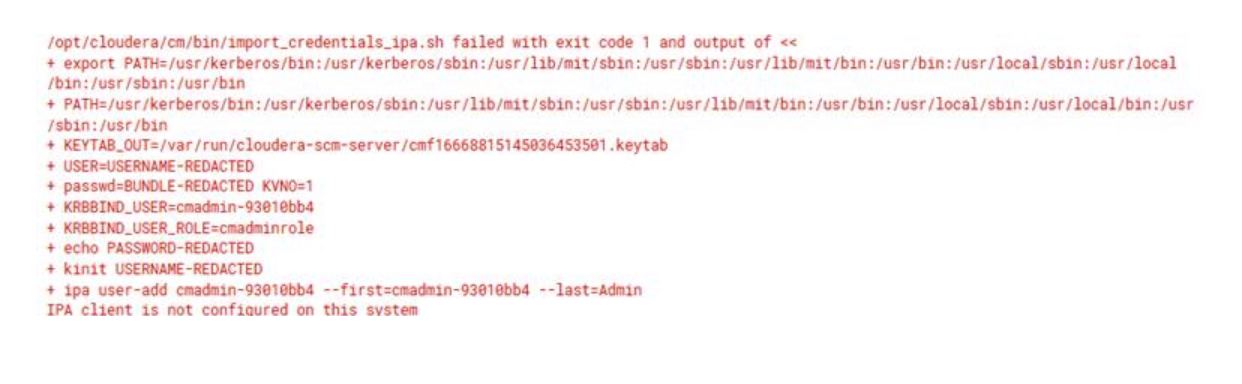
K
Подскажите, как побороть эту проблему?
K
дяденьки, здравствуйте!
подскажите, насколько это анти-паттерн: в одном SparkContext запускать несколько SparkStreamingContext?
подскажите, насколько это анти-паттерн: в одном SparkContext запускать несколько SparkStreamingContext?
можно только один иметь конеткст стримовый
K
если вам несколько нужно, стоит посмотреть в сторону структурного стриминга
SS
коллеги, хочу на Spark Structured Streaming сделать доставку данных из Кафки в ДатаЛейк (бронзовый слой) и одновременно парсинг/процессинг этих данных (серебряный слой)
ну там лямбда-чики-пуки...
через 2 writeStream не хочу - буду дважды вычитывать данные и оффсеты разойдутся.
через foreachBatch не хочу - там нет атомарности двух df.write (или есть?)
что вы используете для такого? строго один writeStream в stage/bronze и отдельный поток приземленные в stage/bronze данные для парсинга/процессинга?
ну там лямбда-чики-пуки...
через 2 writeStream не хочу - буду дважды вычитывать данные и оффсеты разойдутся.
через foreachBatch не хочу - там нет атомарности двух df.write (или есть?)
что вы используете для такого? строго один writeStream в stage/bronze и отдельный поток приземленные в stage/bronze данные для парсинга/процессинга?

OI
Я в драг металлах не силён, но звучит как 2 стрима: один кафка -> сырые данные. Второй сырые данные -> предобработанные данные.
OI
Там же из кафки данные в директорию кладутся?
SS
и вторым стримом постоянно делать листинг базового каталога на предмет появления новых файлов?
SS
ладно, если какая-нибудь DeltaLake-таблица, там вычитываются метаданные с путями до новых файлов
AS
коллеги, хочу на Spark Structured Streaming сделать доставку данных из Кафки в ДатаЛейк (бронзовый слой) и одновременно парсинг/процессинг этих данных (серебряный слой)
ну там лямбда-чики-пуки...
через 2 writeStream не хочу - буду дважды вычитывать данные и оффсеты разойдутся.
через foreachBatch не хочу - там нет атомарности двух df.write (или есть?)
что вы используете для такого? строго один writeStream в stage/bronze и отдельный поток приземленные в stage/bronze данные для парсинга/процессинга?
ну там лямбда-чики-пуки...
через 2 writeStream не хочу - буду дважды вычитывать данные и оффсеты разойдутся.
через foreachBatch не хочу - там нет атомарности двух df.write (или есть?)
что вы используете для такого? строго один writeStream в stage/bronze и отдельный поток приземленные в stage/bronze данные для парсинга/процессинга?
Можно организовать подобие лямбда архитектуры и писать в foreachBatch в два слоя, но потом добивать серебро батчами, ну или сделать подобие транзакции, но тут думаю надо велосипедить
SS
мне странно, что нет готовых решений... ведь все мы в той или иной степени черпаем тазиками из струяющейся жижи в болота данных
ME
Но у каждого тазик свой, сделанный собственноручно)
K
мне странно, что нет готовых решений... ведь все мы в той или иной степени черпаем тазиками из струяющейся жижи в болота данных
Так сделайте второй топик куда сырье льёте )
SS
я хочу одним "черпком" тазика и резервуар с говном дополнить и сразу грубую очистку тяжелых фракций сделать. чтобы в потом в резервуар питьевой долить
SS
если два черпальщика двумя тазиками будут черпать - то рано или поздно разойдутся по жиже внутри, если одним тазиком сначала в грязный чан вливать. то потом надо как-то быстро извлекать новую порцию второму черпальщику-очищальщику
SS
(жизнь научила, что без грязного чана - нельзя! рано или поздно приходится в нем повторно юарахтаться)
e
Spark ? Закешируй в середине и два раза write
SS
Spark ? Закешируй в середине и два раза write
через foreachBatch? нет гарантий атомарности... батрак черпанул один раз. влил в грязный чан и сдох от работы. чистый чан не дозаполнился, а оффсеты уже сдвинулись
SS
тьфу, наборот