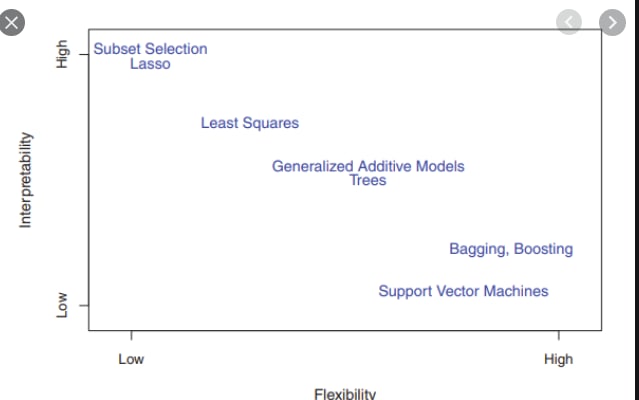
или с линрегрессией, которую используют именно чтобы получить легко трактуемые коэффициенты
Ну тогда только простая селекция по R2, порог 0.9-0.95,и всё. А с бустингами и нейронками, которые на таблицы ориентированы, вопрос. Тут все перечисленные методы должны сгодиться, но тут лишь для уменьшения размерности признакового пространства и скорости работы модели. Вопрос, что быстрее. Но в качестве на тесте такая селекция не особо мне помогала, даже наоборот, ведь немного информации все же теряется, не строгая же мультиколлинеарность..