Efficient Transformers: A Survey
Tay et al. [Google Research]
arxiv.org/abs/2009.06732За прошлые два года число различных модификаций трансформера резко выросло. В частности была куча статей, которые пытаются адаптировать трансформеры для длинных текстов: reformer, longformer, linformer, ...
Google Research решил сделать небольшую статью с обзором этих X-former. Они суммаризируют, что изначально люди активно занимались
фиксированными паттернами atttention (Sparse Transformer et al.), потом начали заниматься
факторизацией этих паттернов (Axial transformer et al.) и постепенно сдвинулись в хитрые
тренируемые паттерны (Reformer et al.). Сейчас же появляется всё больше работ, в которых пытаются использовать
ризкоранговую аппроксимацию матриц attention (Linformer).
В параллель к этому появилось пара реккурентрых подходов удлинения трансформеров - Transformer-XL и Compressive Transformer.
Как всегда в таких обзорах, они заканчиваются тем, что нету никакого стандартного метода сравнения методов друг с другом, кто-то использует генеративные задачи (LM), кто-то GLUE и что в конце-концов не ясно какой подход работает лучше остальных.
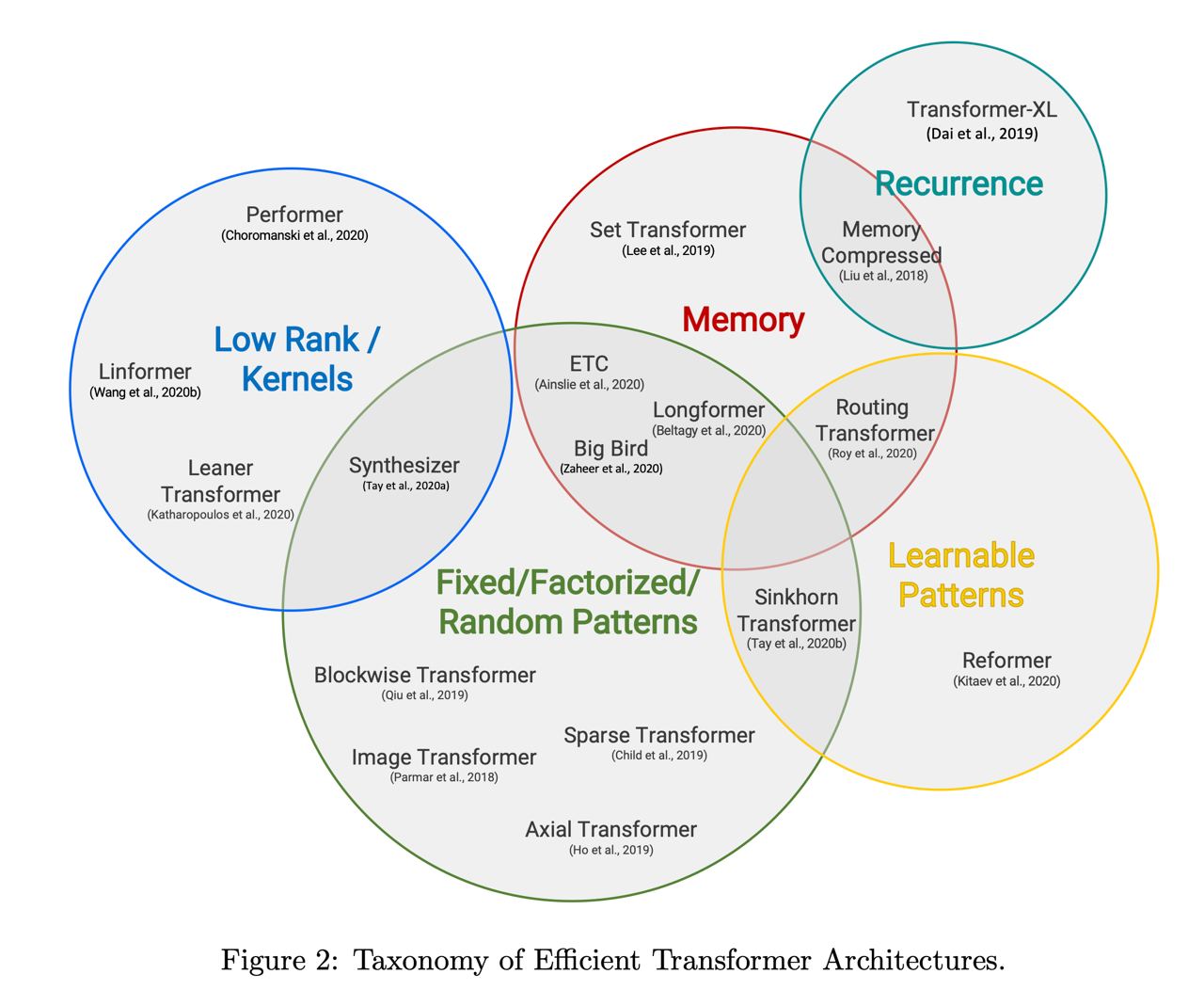
Мне из статьи очень понравилась вот эта картинка, которая хорошо суммаризирует основные подходы.