CD
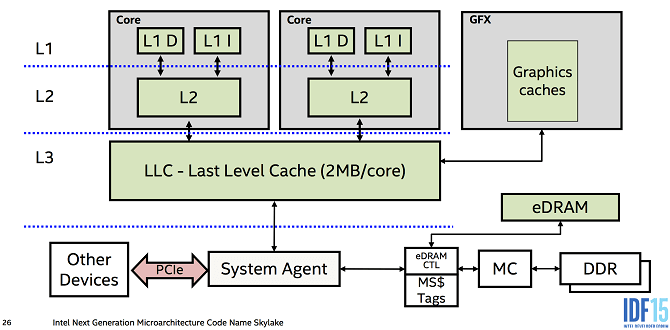
> Each core has its own L1 and L2 cache while the last level, the L3 cache is shared across all the cores on a die.
L1 обычно сверхбыстрый и очень маленький и часто делится на отдельные кеши для данных и инструкций
в L2 все свалено вместе и он жирнее и медленней
L1 обычно сверхбыстрый и очень маленький и часто делится на отдельные кеши для данных и инструкций
в L2 все свалено вместе и он жирнее и медленней
а, понял