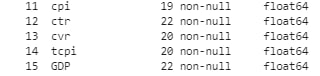
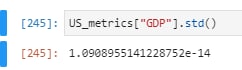
Может кто-нибудь подсказать, пожалуйста, как узнать метки классов для предсказанной модели на основе случайного леса и XGBoost. У меня есть 4 класса (1, 2, 3, 4). Я обучаю модель, затем мне нужно создать датафрейм в котором бы название колонок были названиями класса, а значения в них вероятностью (predict proba) для этого конкретного класса