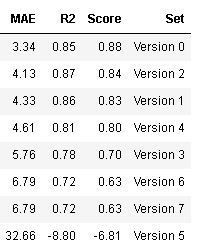
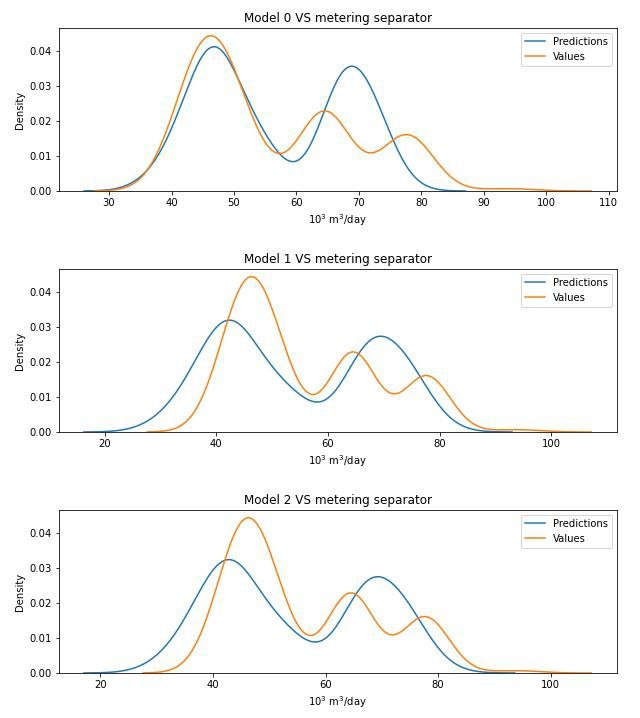
Всем привет! Делаю прогонку модели по разным наборам признаков. Получается, что модели с лучшими метриками хуже чувствуют суть физического процесса. А модели с худшими метриками неплохо понимают процесс, но имеют сдвиг влево. Вечная отрицательная ошибка. Интуитивно кажется, что можно как-то сдвинуть модель вправо. Но как это сделать я не понимаю. Подскажите, пожалуйста, в какую сторону рыть дальше