3
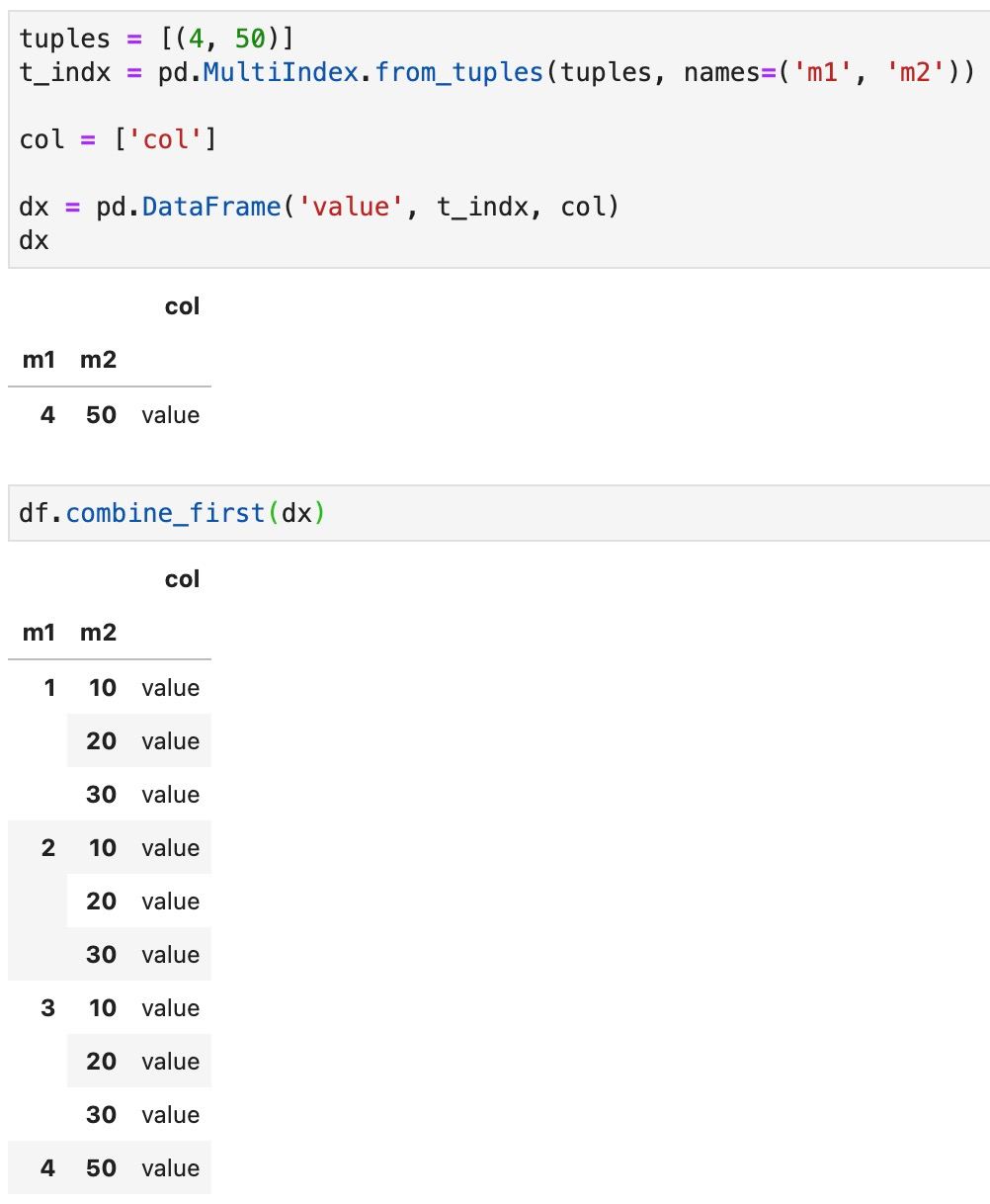
Нужно просто привести к необходимому виду
Size: a a a
3
AK
3
3
AK
ЛЭ

AK

T
$ tesseract all.tif letters.box nobatch box.trainчто я делаю не так? и как узнать подробнее в чем дело? хочу обучить тессеракт на своих картинках
Tesseract Open Source OCR Engine v4.1.1 with Leptonica
Page 1
Error during processing.
АР
T
$ tesseract all.tif letters.box nobatch box.trainчто я делаю не так? и как узнать подробнее в чем дело? хочу обучить тессеракт на своих картинках
Tesseract Open Source OCR Engine v4.1.1 with Leptonica
Page 1
Error during processing.
...
APPLY_BOXES: boxfile line 68/O ((2154,42),(2166,55)): FAILURE! Couldn't find a matching blob
FAIL!
APPLY_BOXES: boxfile line 69/S ((2187,43),(2196,53)): FAILURE! Couldn't find a matching blob
FAIL!
APPLY_BOXES: boxfile line 76/H ((2408,37),(2424,60)): FAILURE! Couldn't find a matching blob
APPLY_BOXES:
Boxes read from boxfile: 76
Boxes failed resegmentation: 66
Found 10 good blobs.
Generated training data for 9 words
T
AD
cumsum штоле?VR
cumsum штоле?LK
3
SZ
АР
cumsum штоле?3
VR
VM