A
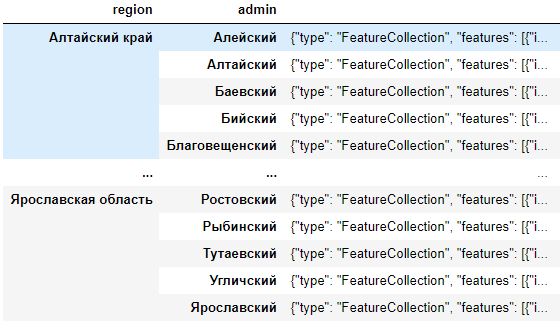
Можно добавить колонку id через резет индекс
Нужно чтобы в каждом регионе с одного начинались id
Size: a a a
A
A
A
PZ
YP
PZ
s
PZ
AS
AS
driver.get('https://halykbank.kz/exchange-rates')
list = driver.find_element_by_css_selector("body > div.wrapper > div > main > div > div.exchange_rates__wrap > div.select-group > div.select-sm.form-group > div.choices > div.choices__inner > div > div")
list.click()VL
driver.get('https://halykbank.kz/exchange-rates')
list = driver.find_element_by_css_selector("body > div.wrapper > div > main > div > div.exchange_rates__wrap > div.select-group > div.select-sm.form-group > div.choices > div.choices__inner > div > div")
list.click()AS
АМ
s
s
ND
PZ
OO
АМ