OA
а, я кажется понял
Size: a a a
OA
OA
D
OA
АГ
pd.read_sql(query.format(date=target_date), con=engine, ...)Е
OA
pd.read_sql(query.format(date=target_date), con=engine, ...)НК
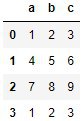
df = pd.DataFrame(np.array([[1,2,3], [4,5,6], [7,8,9], [1,2,3]]), columns=['a', 'b', 'c'])
И он выглядит так.НК
НК
АМ
df = pd.DataFrame(np.array([[1,2,3], [4,5,6], [7,8,9], [1,2,3]]), columns=['a', 'b', 'c'])
И он выглядит так.df.groupby('a').apply(lambda x: x[['b','c']].values)НК
df.groupby('a').apply(lambda x: x[['b','c']].values)АМ
series, а датафрейм на выходе, то просто вызвать к получившейся конструкции метод .to_frame()ЕД
НК
Е
АМ
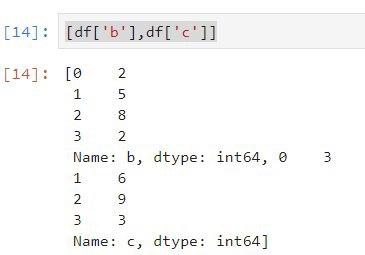
[df['b'], df['c']], то тем самым делаете просто одномерный список из двух Series.АМ
df.apply(lambda x: [x['b'],x['c']],axis=1)АМ
groupby со сворачиванием в список