



МЦ
@dmitryrodin Спасибо! 🙏🏻👍🏻
Size: a a a
МЦ
DR
DR
DR
DR
N
YP
N
НК
НК
YP
YP
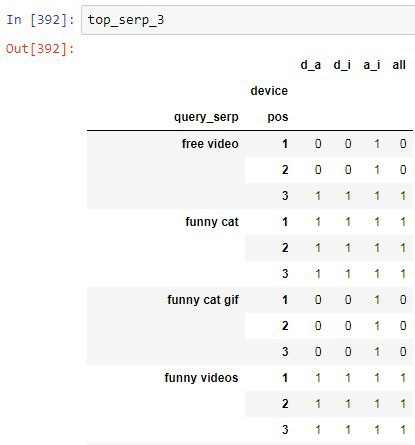
free video 1И в процентах
funny cat 1
funny videos 3
free video 20%Некоторые слова пропустил.
funny cat 20%
funny videos 60%
N
N
AD
N
YP
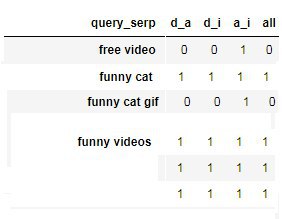
df = df.reset_index().groupby('query_serp').count()
df['all'] = df['all'] / len(df)
Вроде так. Скинь первоначальные данные, покажу, как из них без костылей получить тот же выходЕА
R
