


/¯
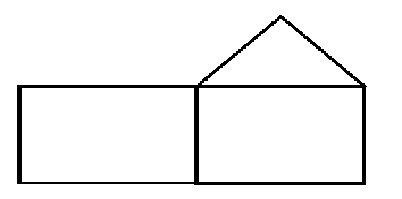
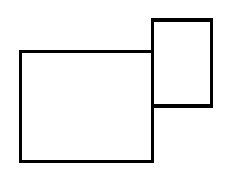
Еще есть ограничение: если у фигур менее чем 2-х общих вершин - не соединяем их
Тогда что это за условие?
Size: a a a
/¯
/¯
/¯
/¯
ГС
ГС
ГС
ГС
/¯
/¯
ГС
ГС
/¯
A
EZ
MB
KK
MB
AL
user|group
1|1
2|1
1|2
2|2
4|7
5|7
1|3
15|3
group | users
1&2|[1,2,15]
7|[4,5]
MB
user|group
1|1
2|1
1|2
2|2
4|7
5|7
1|3
15|3
group | users
1&2|[1,2,15]
7|[4,5]