



IM
Добрый день
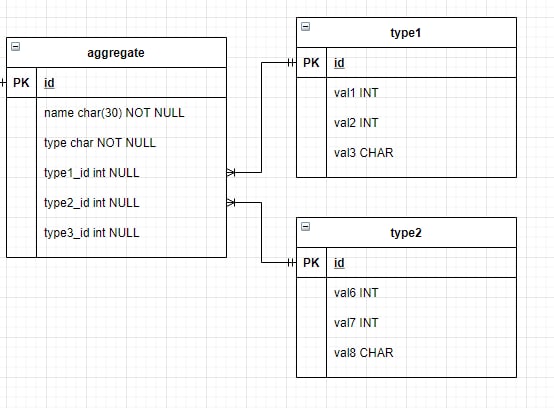
Небольшой вопрос по проектированию
Нормальной ли практикой будет иметь несколько foreign key null в таблице, собирающей в себя различные типы?
Или это плохая практика?
Небольшой вопрос по проектированию
Нормальной ли практикой будет иметь несколько foreign key null в таблице, собирающей в себя различные типы?
Или это плохая практика?
Не страшно. Но все зависит от контекста. Есть ситуации, где норм. По логике вещей