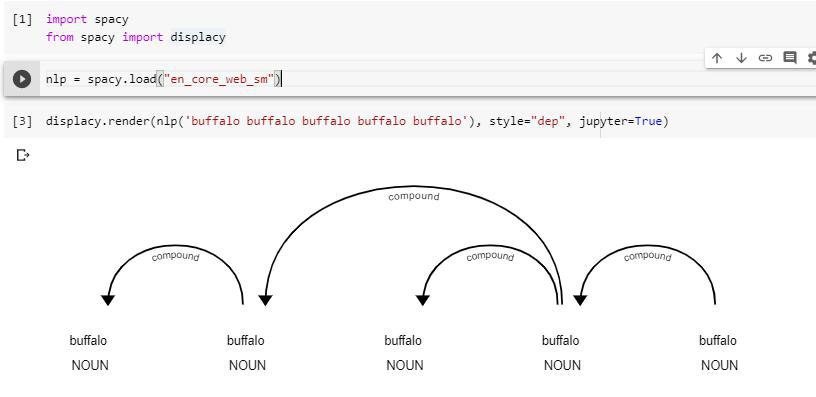
Язык так устроен. Синтаксическая связь -- вопрос от одного слова к другому слову или группе слов. Тип связи — ответ на вопрос. Это же и одновременно синтаксическая роль, которую размечает constituency parser. Разница в том, что в 1970м парсер на O(N^3) был непрактичен, и даже проективный O(N^2) парсер был непрактичен, и влезающую в компьютеры лингвистическую нейросеть для O(N) (линейного) shift-reduce парсера ещё не придумали.
Поэтому написали упрощённые правила для определения этих ролей, и огрубили роли, чтобы правила реже ошибались. Для английского даже как-то работало.
И до сих пор, тот же Jurafsky описывает примеры на составляющих. И по тому что я видел в описаниях продуктов типа PoolParty, Megaputer - они тоже используют такие простые правила. Не хочется повторять за ними, но другого видения у меня нет.
Может быть ты встречал примеры?