Ребята а как работает metallb? есть непонятка.
16 кубер kubespray
установлен metallb в роли loadballancer
ingress-nginx получил у metlalb ипшник
10.5.0.50 который доступен на всех нодах
я думал что я смогу с любой ноды обращаться к этому единому ип
10.5.0.50 но по факту получается что я к портам nginx достучаться могу только с ноды на которой стоит ingress-nginx
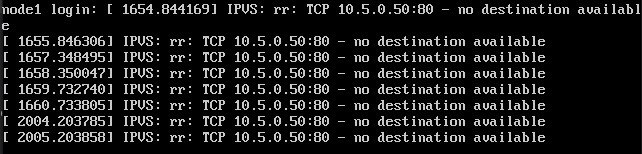
на всех остальных получаю
~# telnet 10.5.0.50 80
Trying 10.5.0.50...
telnet: Unable to connect to remote host: Connection refused
в ipmi сервака в консоле вижу IPVS no destination available