Y
Что то на татарском
Size: a a a
Y
SS
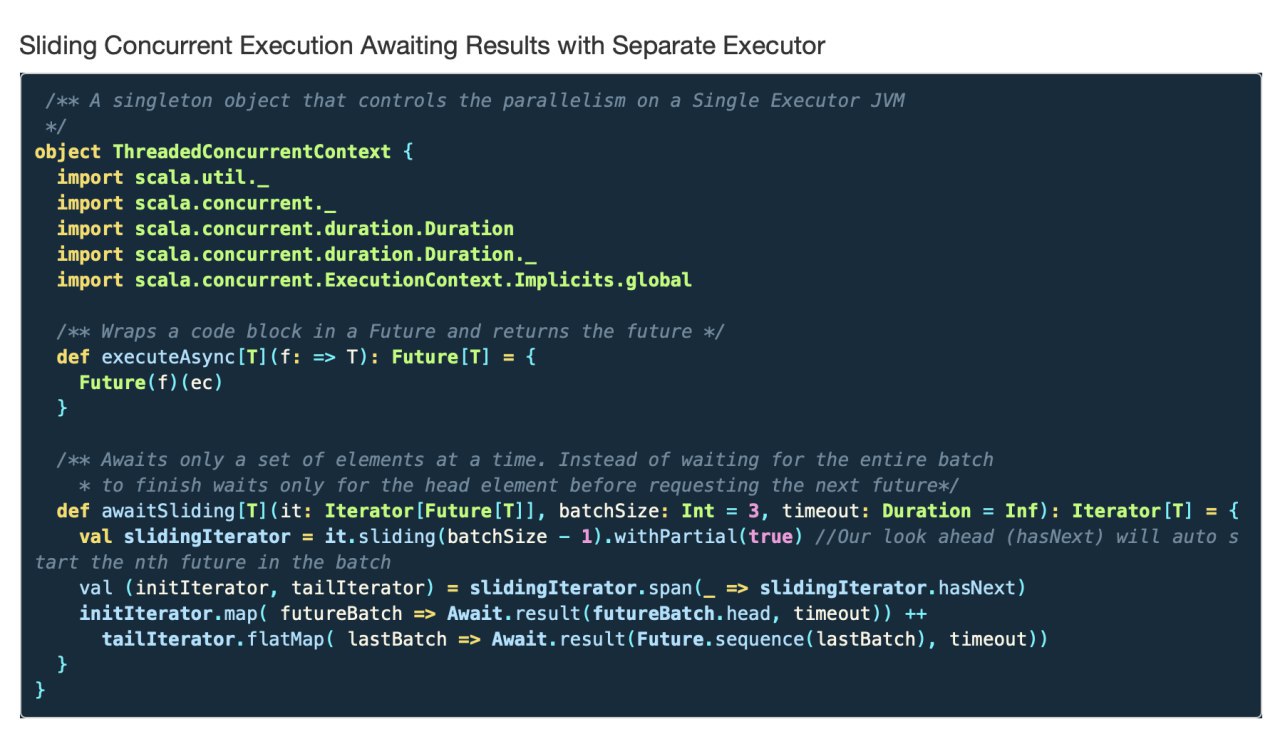
object ThreadedConcurrentContext {
import scala.util._
import scala.concurrent._
import scala.concurrent.duration.Duration
import scala.concurrent.duration.Duration._
import scala.concurrent.ExecutionContext.Implicits.global
/** Wraps a code block in a Future and returns the future */
def executeAsync[T](f: => T): Future[T] = {
Future(f)(ec)
}
/** Awaits only a set of elements at a time. Instead of waiting for the entire batch
* to finish waits only for the head element before requesting the next future*/
def awaitSliding[T](it: Iterator[Future[T]], batchSize: Int = 3, timeout: Duration = Inf): Iterator[T] = {
val slidingIterator = it.sliding(batchSize - 1).withPartial(true) //Our look ahead (hasNext) will auto start the nth future in the batch
val (initIterator, tailIterator) = slidingIterator.span(_ => slidingIterator.hasNext)
initIterator.map( futureBatch => Await.result(futureBatch.head, timeout)) ++
tailIterator.flatMap( lastBatch => Await.result(Future.sequence(lastBatch), timeout))
}
}MY
P
MY
AZ
MY
AS
MY
EK
object ThreadedConcurrentContext {
import scala.util._
import scala.concurrent._
import scala.concurrent.duration.Duration
import scala.concurrent.duration.Duration._
import scala.concurrent.ExecutionContext.Implicits.global
/** Wraps a code block in a Future and returns the future */
def executeAsync[T](f: => T): Future[T] = {
Future(f)(ec)
}
/** Awaits only a set of elements at a time. Instead of waiting for the entire batch
* to finish waits only for the head element before requesting the next future*/
def awaitSliding[T](it: Iterator[Future[T]], batchSize: Int = 3, timeout: Duration = Inf): Iterator[T] = {
val slidingIterator = it.sliding(batchSize - 1).withPartial(true) //Our look ahead (hasNext) will auto start the nth future in the batch
val (initIterator, tailIterator) = slidingIterator.span(_ => slidingIterator.hasNext)
initIterator.map( futureBatch => Await.result(futureBatch.head, timeout)) ++
tailIterator.flatMap( lastBatch => Await.result(Future.sequence(lastBatch), timeout))
}
}SS
SS
SS
SS
AS
ИК
EK
AS
ИК