A
Я использую вариант через udf
Попробывал сделать с UDFs на таком уровне:
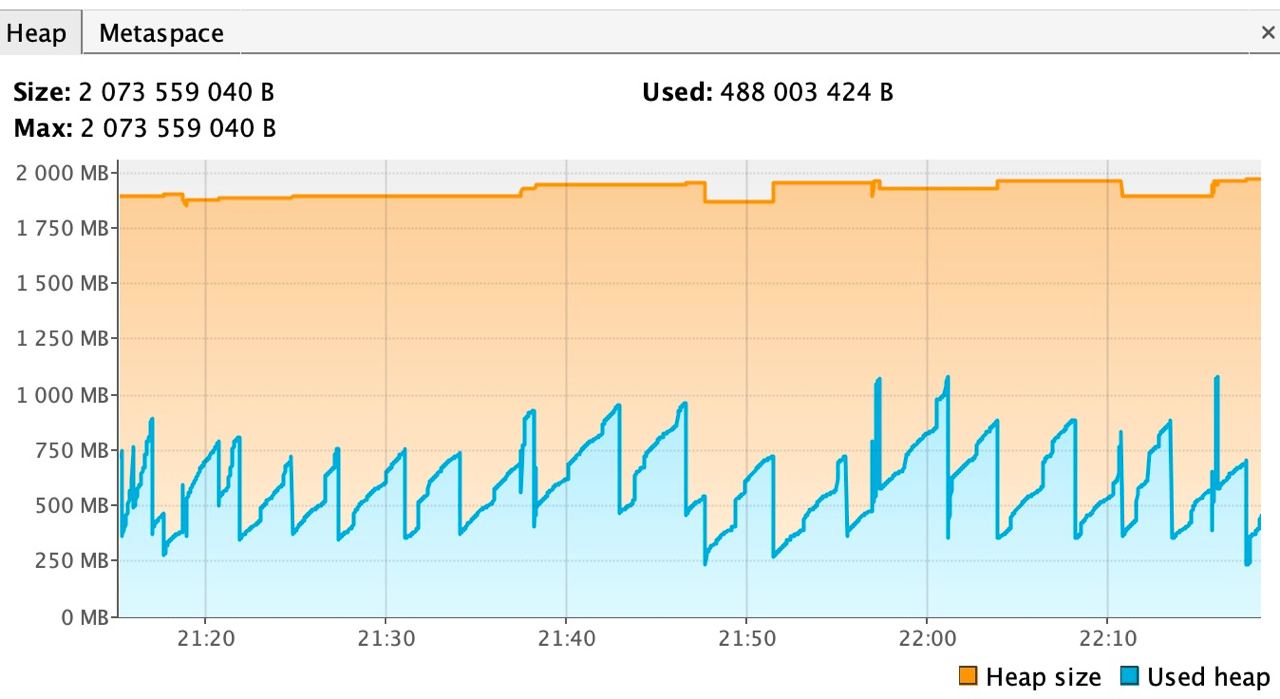
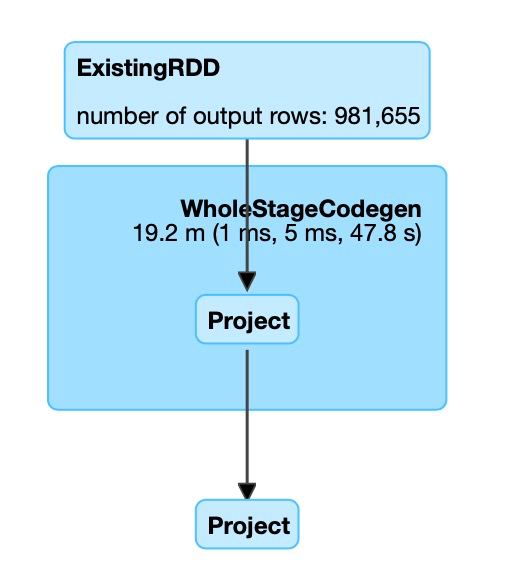
from pyspark.sql.types import StringTypeТолько вместо функции say_hello поставил свою функцию с inference. Запустилось через spark-submit. Но вычисления не ускоряются от числа нод... Нужно как-то хитро каждой ноде сказать что делать. Плюс у меня подозрение что функция описанная выше вообще спарком не параллелиться. То есть расчёт происходит не на векторах, а на отдельных склярах друг за другом.
from pyspark.sql.functions import udf, col
def say_hello(name : str) -> str:
return f"Hello {name}"
assert say_hello("Summer") == "Hello Summer"
say_hello_udf = udf(lambda name: say_hello(name), StringType())
df = spark.createDataFrame([("Rick,"),("Morty,")], ["name"])
df.withColumn("greetings", say_hello_udf(col("name")).show()